
自2016年4月Nvidia推出SXM形式、基於Pascal架構的Tesla P100 GPU,以及搭配8個P100的深度學習整合應用設備DGX-1,市面上,陸續開始出現多款支援GPU互連介面NVLink的伺服器。
隔年5月,Nvidia發表SXM2形式、基於Vota架構的Tesla V100,以及採用這款GPU的DGX-1,以及DGX Workstation。
到了2018年3月,Nvidia推出GPU記憶體多達32GB的Tesla V100、可支援16個GPU互連的交織網路NVSwitch,以及運算效能更強、體型也更為龐大的深度學習整合應用設備DGX-2。
同年年底,他們發表了基於Turing架構、鎖定雲端服務環境使用的GPU,名為T4,接著,又於去年5月,將搭配這張GPU加速卡的EGX伺服器,與他們的單板電腦Jetson Nano、車用電腦Drive AGX Pegasus,並列為EGX平臺,主攻邊緣運算。
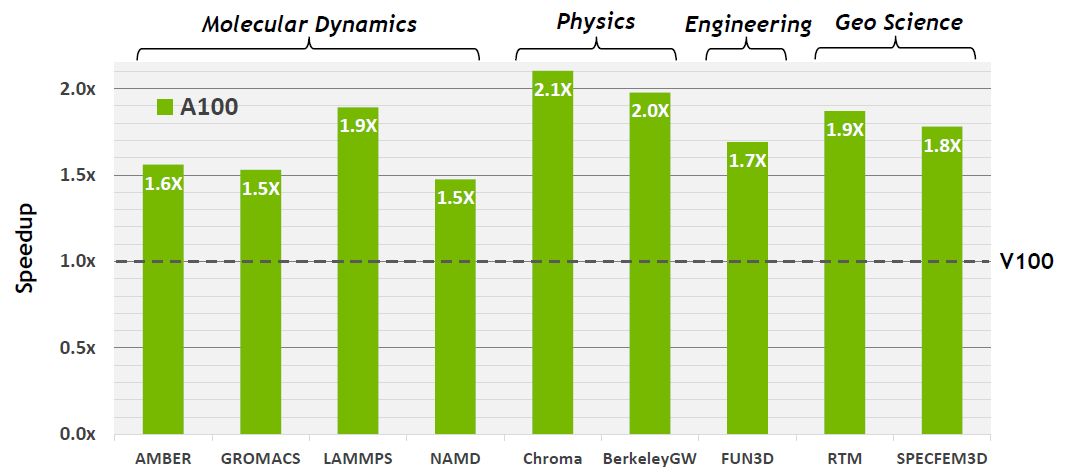
今年5月,該公司終於推出新世代的資料中心等級GPU,名為A100,採用了他們最新發展的Ampere架構,若以採用前代Volta架構的GPU為比較基準,A100效能提升幅度上看20倍。
相較於Volta架構GPU的單精度浮點運算(FP32),若改用A100新支援的TensorFloat-32(TF32)計算模式,來進行人工智慧與高效能運算的張量處理作業,效能為156 TFLOPS,速度可提升至10倍;若結合TF32與結構化的稀疏性處理(Sparsity),A100的效能為312 TFLOPS,增長幅度可達到20倍之高。

採用7奈米、內建記憶體容量提升到40GB
就本身的配置而言,A100的外形為SXM4,採用台積電研發的7奈米製程,由542億顆電晶體所組成,是全世界目前最大的7奈米處理器。

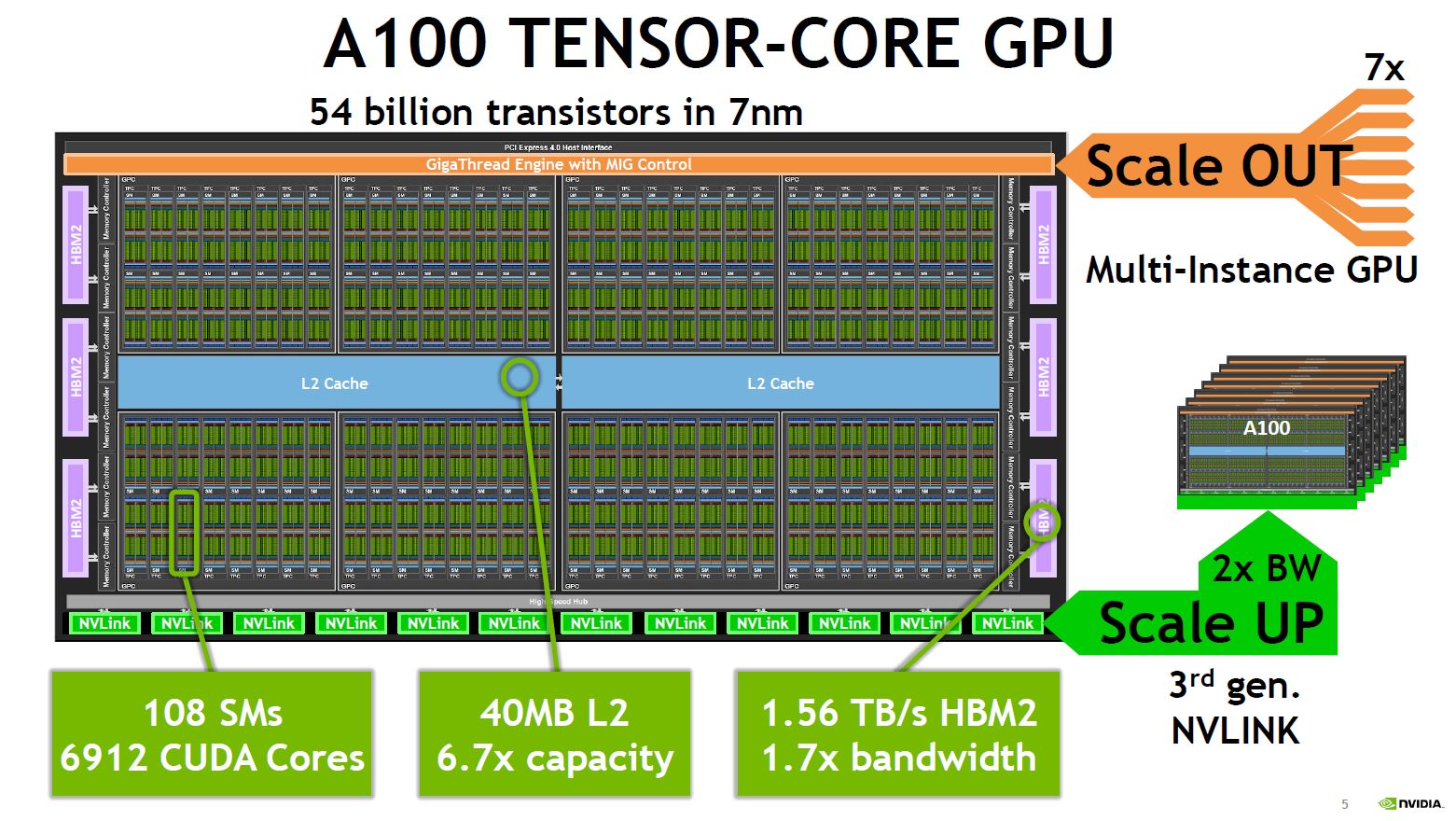
記憶體的部份,它依然採用HBM2,容量增加到40GB(V100為32GB、P100為16GB),存取介面也提升到5120位元,存取頻寬增加到1,555 GB/s(比起V100提升73%);L2快取大幅增加到40MB(V100為6MB、P100為4MB),可提供更強大、迅速的快取能力。

除此之外,A100也加入運算資料壓縮的功能,能進一步提升記憶體與L2頻寬,改善幅度可達到4倍,同時還能提升L2使用容量。
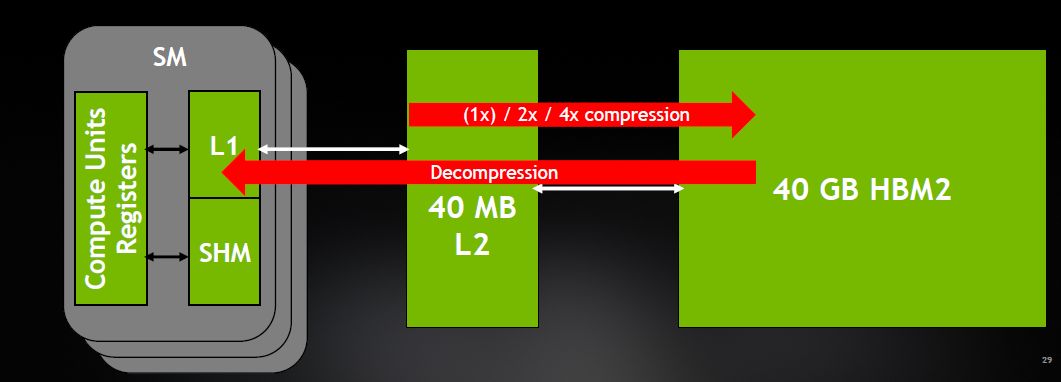
採用第三代Tensor Core,支援TF32的運算模式
在運算單元的搭配上,A100擁有6,912顆FP32核心、6912顆INT32核心,3,456顆FP64核心,都比V100增加了35%,但Tensor Core不增反減,僅搭配432顆(V100是640顆)。事實上,A100使用了第三代Tensor Core,可支援深度學習與高效能運算應用的資料型別,包括FP16、 BF16、TF32、FP64、INT8、 INT4、Binary,若是搭配上述的稀疏性處理功能,能將GPU的處理能力提升至2倍。
從GPU的整體元件來看,我們可看看下列兩張圖,分別是本次推出的A100,以及先前發表的V100的完整GPU配置。兩者有何差異?A100在I/O介面上,使用了PCIe 4.0,V100則是PCIe 3.0;A100搭配了12個512位元記憶體控制器,以及6個HBM2記憶體堆疊,V100則是8個512位元記憶體控制器,以及4個HBM2記憶體堆疊;至於NVLink,A100設置了12個,V100是6個。
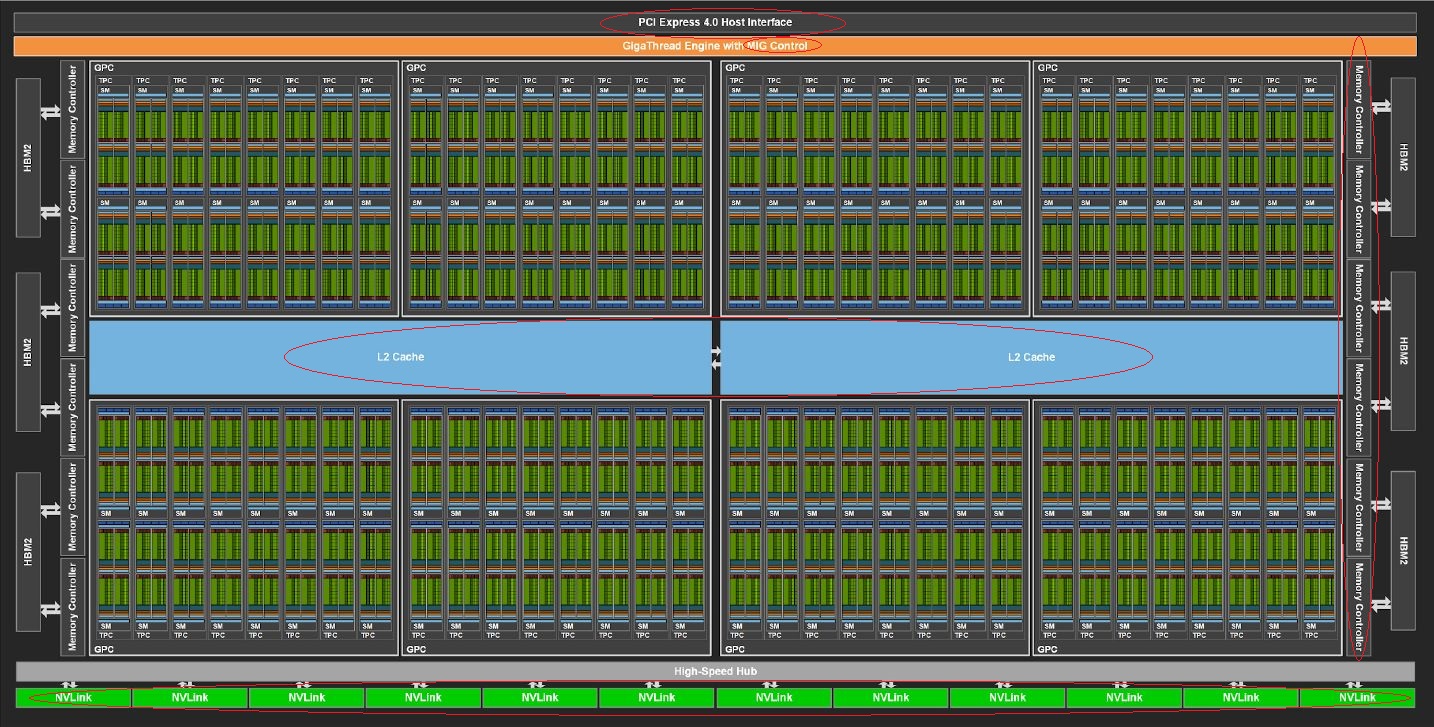
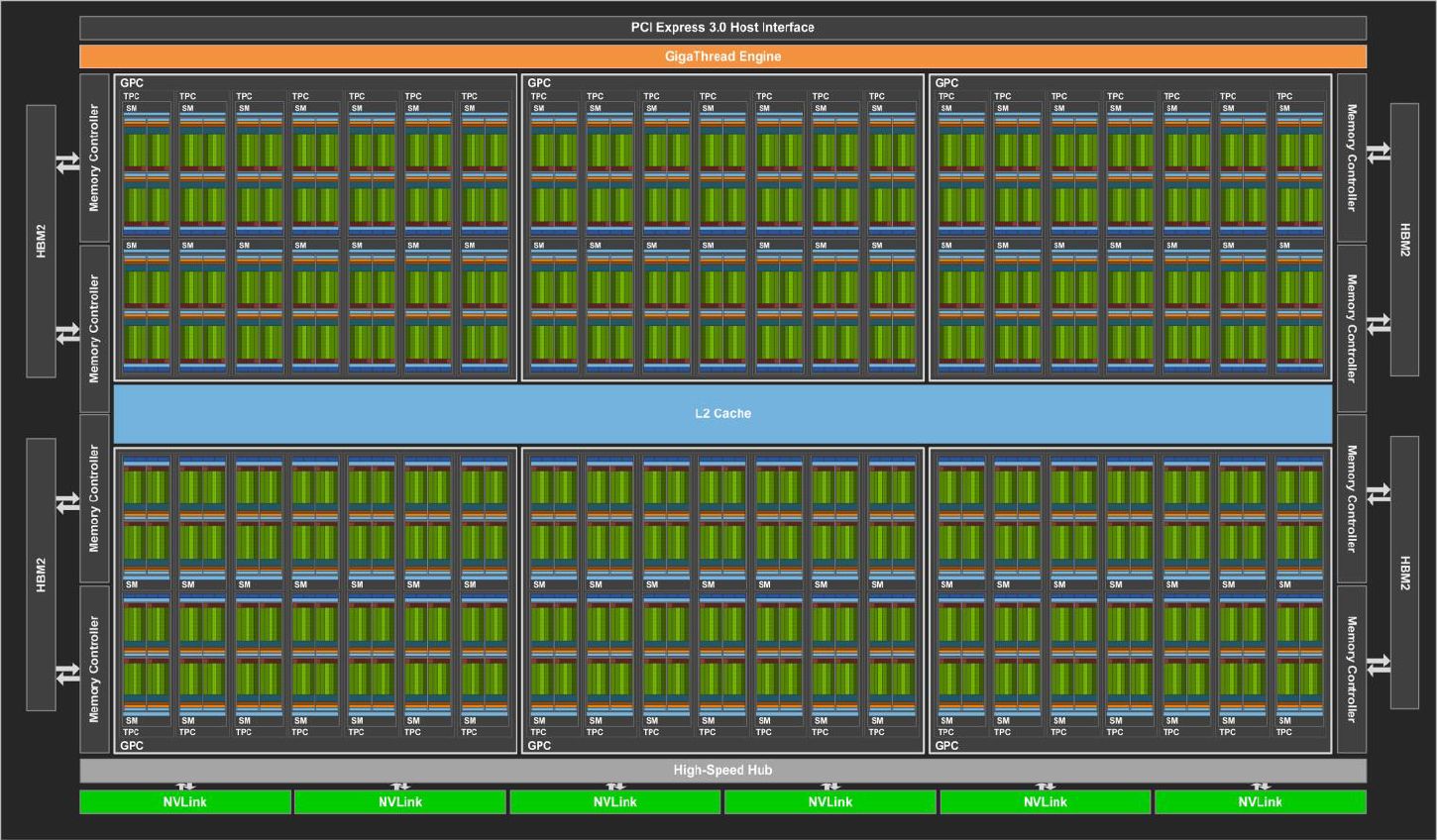
若從串流複合處理器(Streaming Multiprocessor,SM)的角度來看,也進一步看出前後兩代GPU架構的差異。以L2快取為例,A100分成兩個區塊,目的為了增加記憶體存取頻寬與降低延遲,Nvidia表示,A100的L2頻寬是V100的2.3倍
對於Tensor Core的配置上,A100每個SM有4個Tensor Core,每個Tensor Core在一個時脈週期可執行256個FP16/FP32 FMA運算,而V100有8個Tensor Core,每個Tensor Core在一個時脈週期可執行64個FP16/FP32 FMA運算。因此,兩者在這類運算力上,相差1倍。
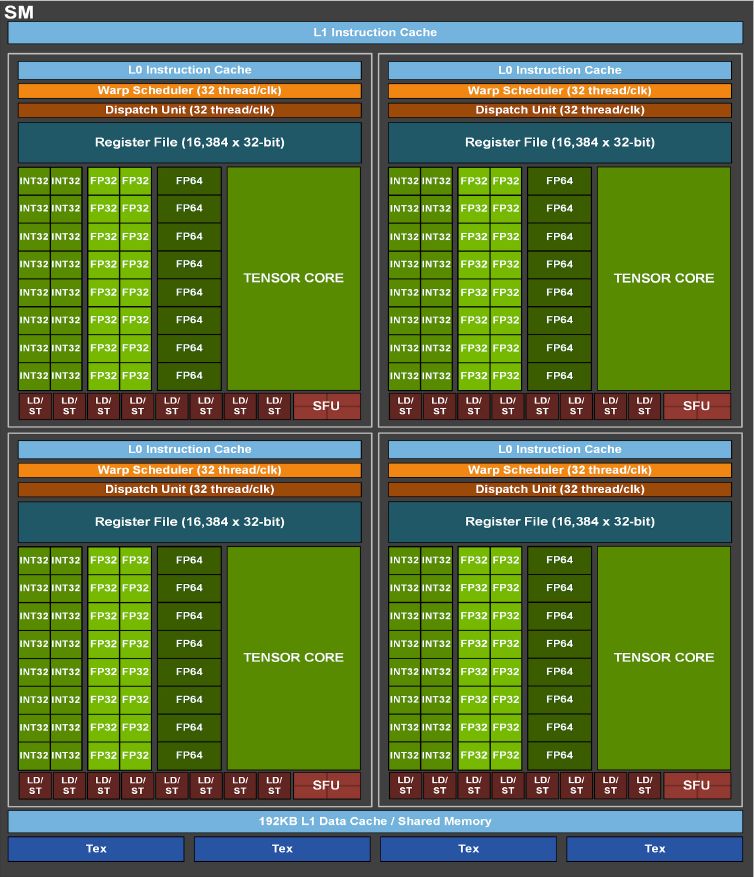
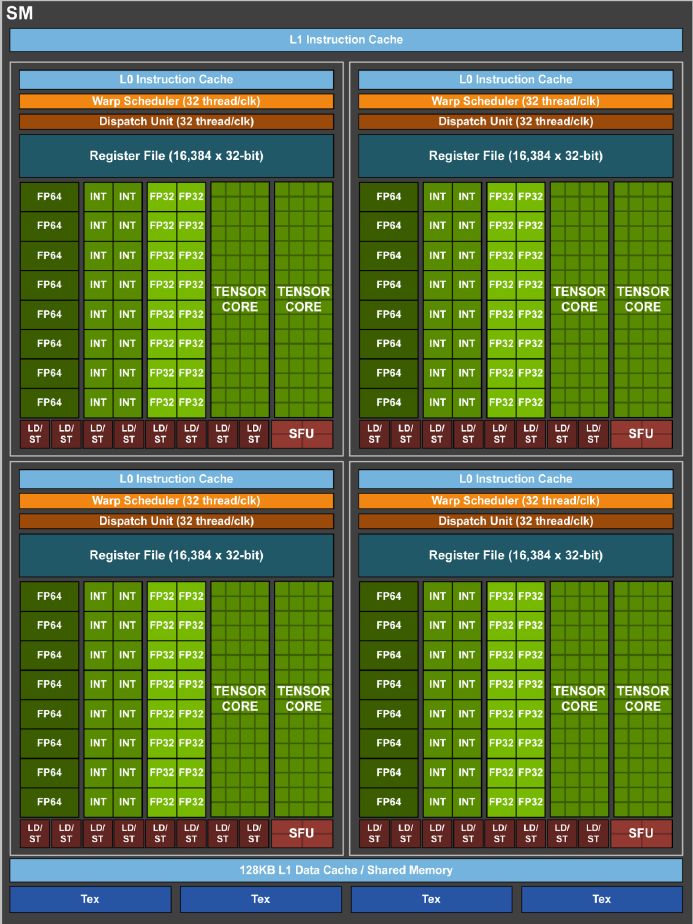
關於A100的資料型別處理能力,又以本次新增的TF32最受矚目,當GPU處於這樣的運算模式下,可加速深度學習框架與高效能運算的FP32資料處理,,相較於V100的FP32 FMA運算,速度可加快10倍,再搭配稀疏性處理,可提升至20倍。
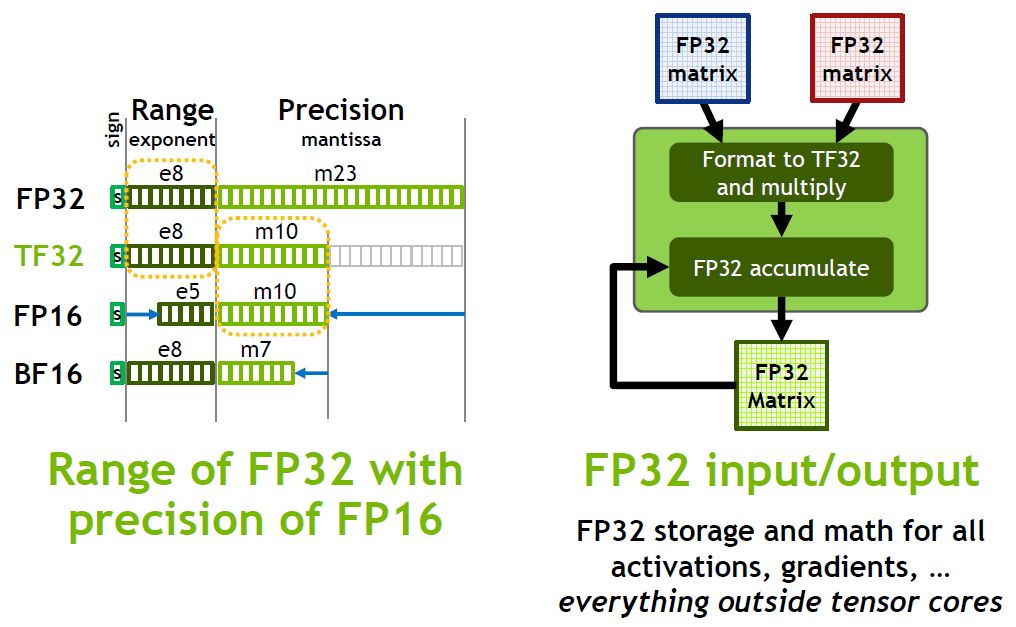
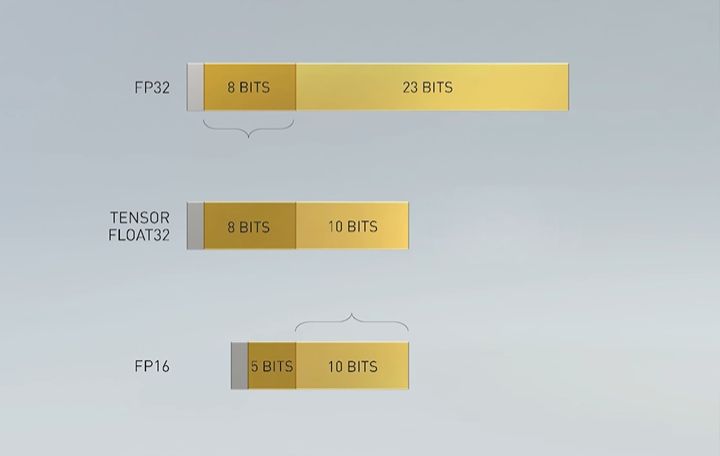
這一代Tensor Core也支援新的BF16與FP32的混合精度運算,性能如同FP16和FP32混合精度的運算。至於INT8、 INT4、Binary的加速處理上,Nvidia也完成對於深度學習推論的支援,以INT8為例,A100可得到V100的20倍效能。而在高效能運算領域的應用上,A100 Tensor Core提供的FP64遵循IEEE的標準,若以V100的FP64效能為準,可得到2.5倍的效能。
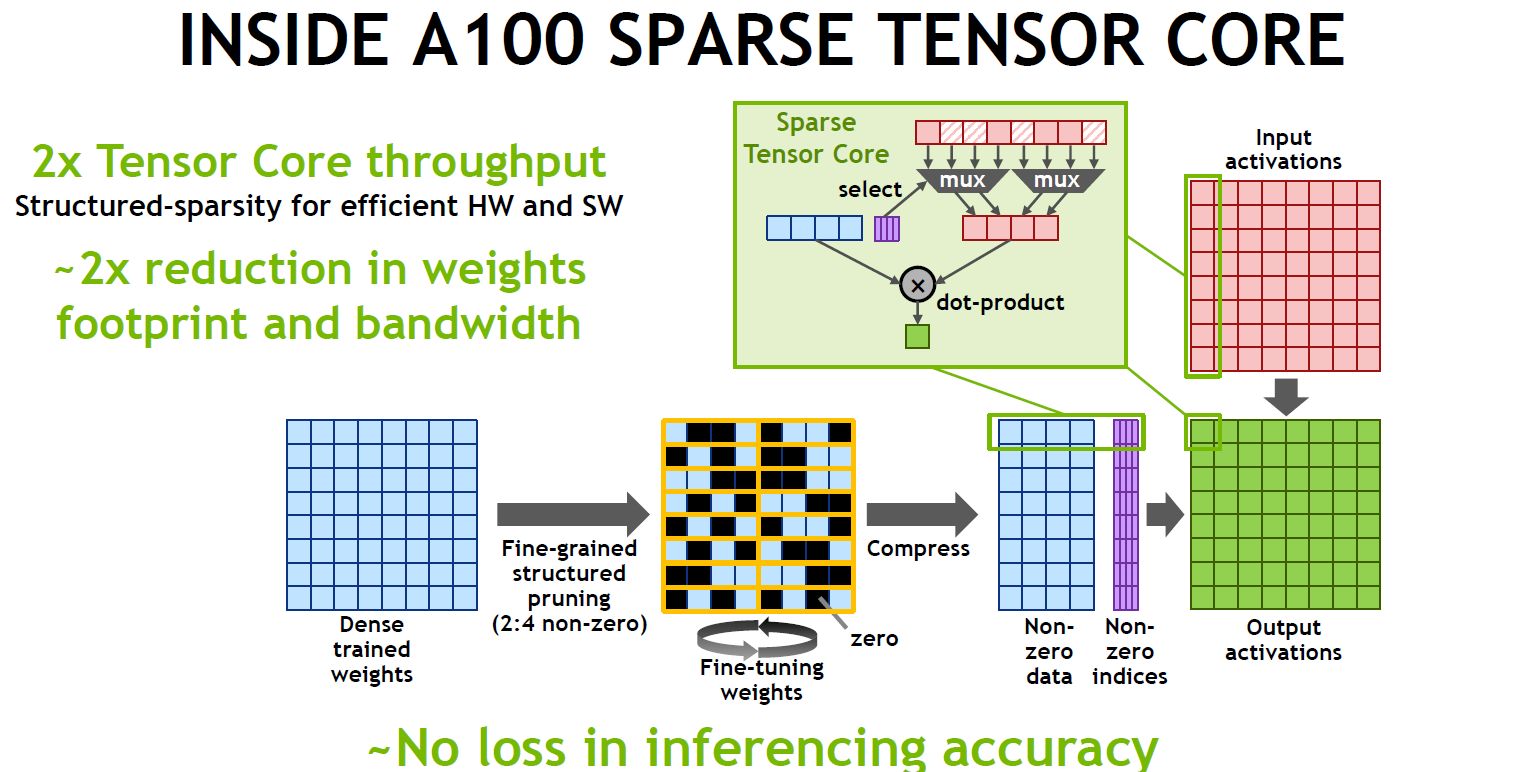
關於稀疏性的處理也是A100相當重要的運算特色,Nvidia導入了細致、結構化的作法,能將深層神經網路的運算吞吐量提高1倍。這種作法會以2:4的非零模式來修整訓練權重,而權重也會經過壓縮處理,可因此減少資料量與所需頻寬,而A100也能忽略為數值為零的資料,將數學運算的吞吐量提高1倍。
支援第三代NVLink與多執行個體GPU,提供外部擴充與內部虛擬化
A100在提升延展性的部分,也提供兩種作法,首先是支援Nvidia前幾年就發展起來的GPU互連技術NVLink,能讓多個A100統合成一個巨型的GPU,因應更大規模的深度學習訓練處理任務,而且這裡採用Nvidia最新發展的第三代技術,將GPU之間的連結速度提升至前一代技術的2倍。
基本上,第三代NVLink在單對連線上的資料傳輸率為50Gbps(V100是25.78 Gbps),由於每個A100可使用12條的NVLink(V100是6條),所以,總頻寬可達到600 GB/s(V100是600 GB/s),而這些NVLink可連接其他GPU與交換器,以搭配這個GPU而成的整合應用設備DGX A100為例,配置了8個A100,這些GPU彼此可透過支援NVLink的NVSwitch晶片來互連,若是多臺DGX A100之間,也可以透過Mellanox InfiniBand交換器及乙太網路交換器,來彼此連結。

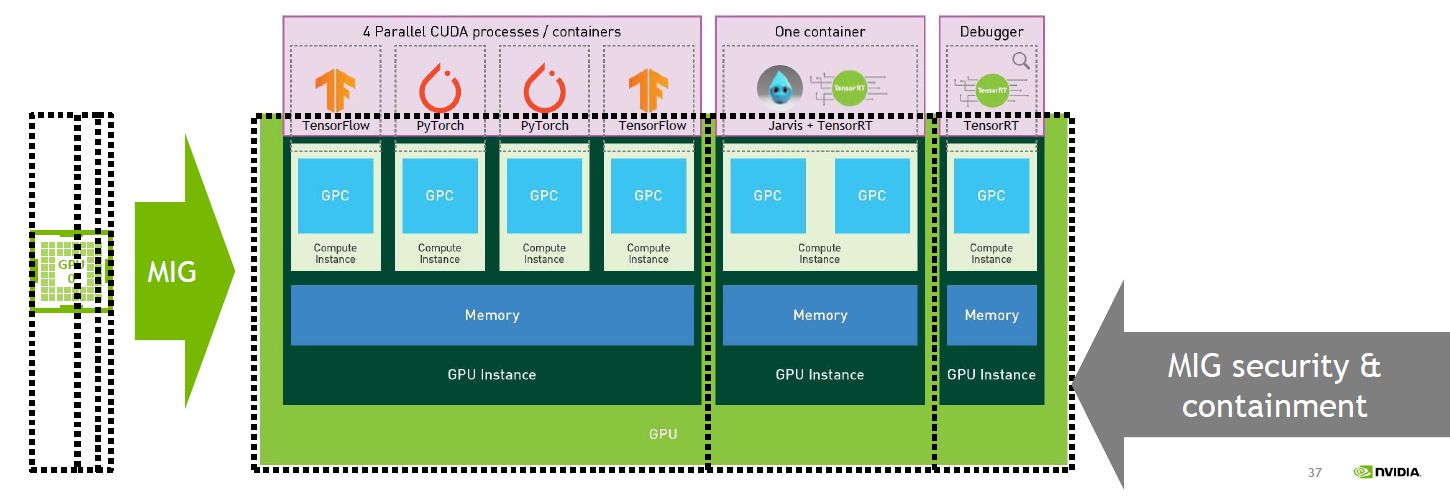
另一種是A100新增的GPU分割技術,稱為多執行個體GPU(Multi-instance GPU,MIG),能讓GPU切割成7個獨立的執行個體,以便進行深度學習的推論處理,也能改善GPU伺服器的使用率。
這種作法可支援多租戶與虛擬化GPU環境,尤其是雲端服務業者的需求,針對用戶端或應用系統,例如虛擬機器、容器、處理程序,提供進階的錯誤隔離及服務品質確保(QoS)機制。
MIG除了能讓多個GPU執行個體同時在一個實體的A100執行,也能它們支援CUDA應用程式的執行,繼續維持CUDA程式設計模型,而不需重新設計。
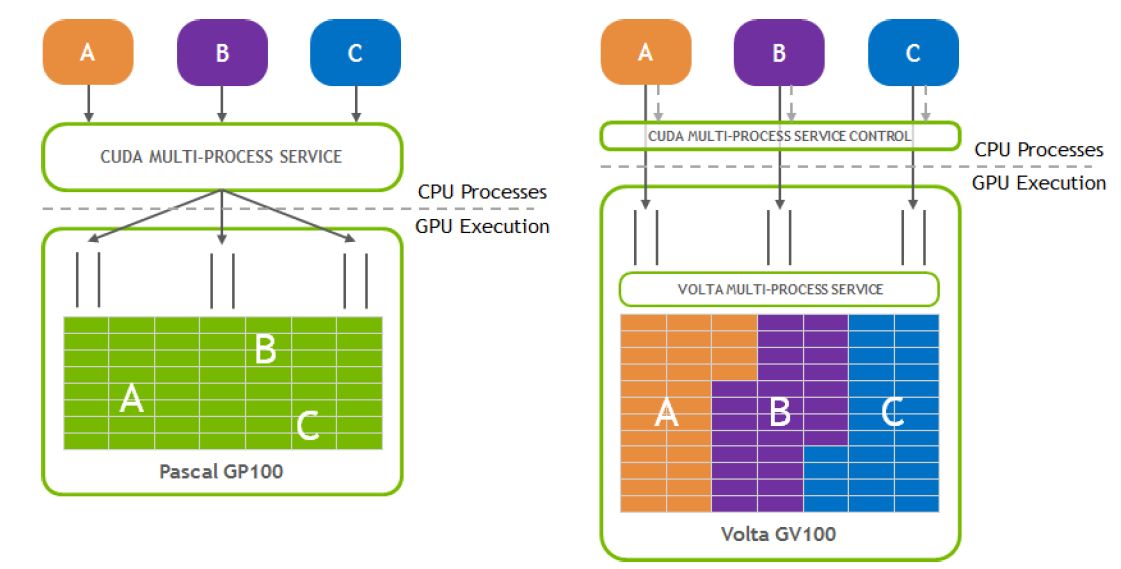
不過,MIG的出現也並非偶然,早先Nvidia在CUDA的API當中,就實作了多重處理服務(Multi-Process Service,MPS)的架構,能同時執行具有多個處理程序的CUDA應用程式,也被稱為軟體型態的MPS;到了2017年問世的Volta架構與Tesla V100 GPU,增設了硬體加速的MPS支援,能讓多個應用程式同時執行在個別的串流複合處理器(Streaming Multiprocessor,SM),可提供更大的吞吐量與更低的延遲。然而,此時的記憶體系統資源,是由所有應用程式共享,有些應用程式可能會因為記憶體頻寬要求高,或對於L2快取提出過高請求,而干擾其他應用程式的執行。之所以這樣,Nvidia表示,主要是因為當初設計GPU跨應用程式共享時,他們的作法是針對單一使用者的狀況,而不是多使用者或多租戶使用者。
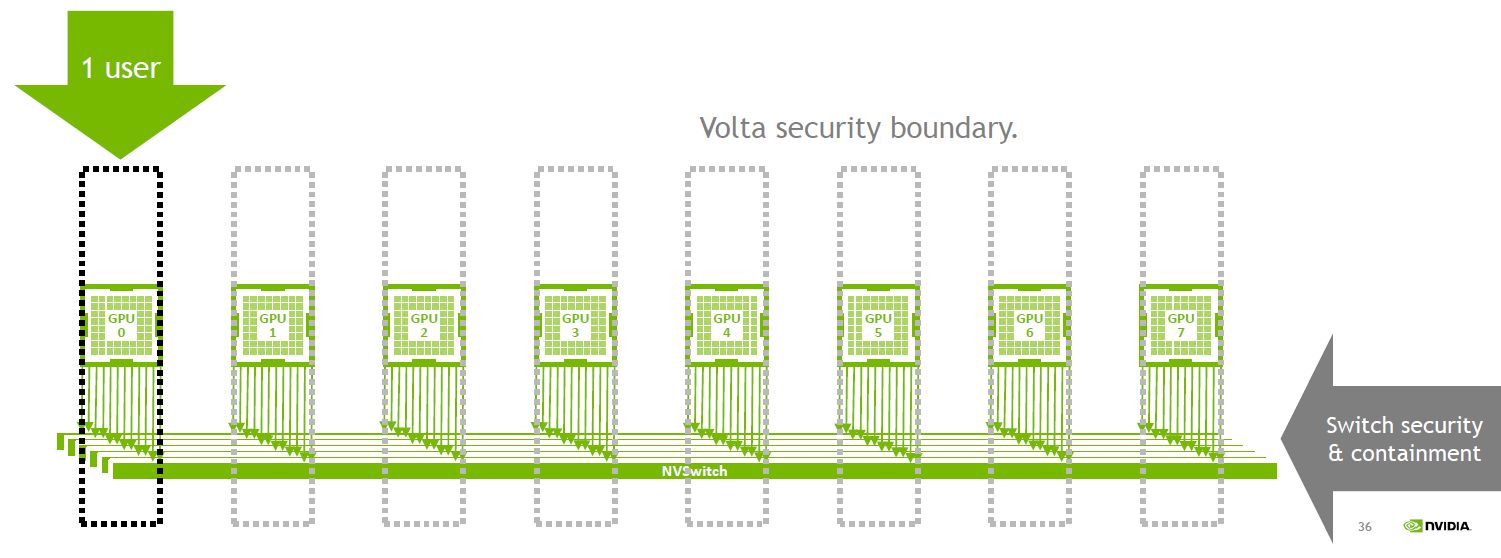
到了A100,Nvidia發展出MIG的機制,可將單顆GPU分成多個GPU執行實體,每個實體的串流複合處理器,獨立、隔離於整個記憶體系統之外,晶片上的交錯閂連接埠、L2快取槽、記憶體控制器、DRAM位址匯流排,都是配置給個別的GPU執行個體,如此可確保個別使用者的工作負載,能夠在可預期的吞吐量與延遲狀態,以及相同的L2快取配置與DRAM頻寬狀態下執行。
開始採用PCIe 4.0,支援Magnum IO與Mellanox Interconnect
自從AMD在2019年推出第二代EPYC處理器平臺,PCIe 4.0介面開始出現在市面上的伺服器,但Nvidia一直都沒有推出支援這個介面得GPU加速卡,直到今年他們發表A100才打破了這個狀況。
有了PCIe 4.0之後,A100現在可以坐擁31.5 GB/s的I/O頻寬,在此之前,Nvidia GPU可能會受限於PCIe 3.0的15.75 GB/s。除此之外,A100也支援PCIe規格延伸的IO虛擬化技術SR-IOV,能讓多個處理程序或虛擬機器共用單一PCIe連線。
在I/O的部份,A100也支援Nvidia在2019年11月發表的Magnum IO軟體平臺,以及Mellanox旗下的InfiniBand與乙太網路互連解決方案,以便加速多節點之間的網路連結。

Nvidia表示,Magnum IO的API整合了運算、網路、檔案系統、儲存,可提升多GPU運算架構、多節點加速系統的I/O效能,而且,它能連接CUDA-X程式庫,可涵蓋人工智慧、資料分析、圖解呈現等廣泛的工作負載類型,來提供I/O加速的功效。
產品資訊
Nvidia A100 Tensor Core GPU
●原廠:Nvidia
●建議售價:廠商未提供
●處理器製程:TSMC 7nm N7 FinFET
●I/O介面:PCIe 4.0
●外型:SXM4
●GPU架構:Nvidia Ampere
●GPU核心:6912顆CUDA核心、432顆Tensor Core
●GPU記憶體:40GB HBM2
●記憶體頻寬:1555 GB/s
●運算效能:雙精度(FP64)為9.7 TFLOPS
●支援運算API:CUDA-X HPC 、CUDA、OpenACC
●GPU互連介面:第三代NVLink,50 Gbps
●耗電量:400瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06