
去年9月,Nvidia(輝達)發表新的GPU架構Ada Lovelace,並推出消費型娛樂產品GeForce RTX 4090與4080,到了今年1月底,基於這個架構,他們正式推出專業繪圖桌上型工作站GPU產品RTX 6000 Ada Generation,以及資料中心GPU產品L40。而在3月下半舉行的GTC 2023春季大會,Nvidia接續推出更多採用此架構的產品。
以專業繪圖GPU而言,他們發表多款用於筆電工作站的產品,像是:機型名稱後面冠上Ada Lovelace的RTX 5000、RTX 4000、RTX 3500、RTX 3000、RTX 2000;
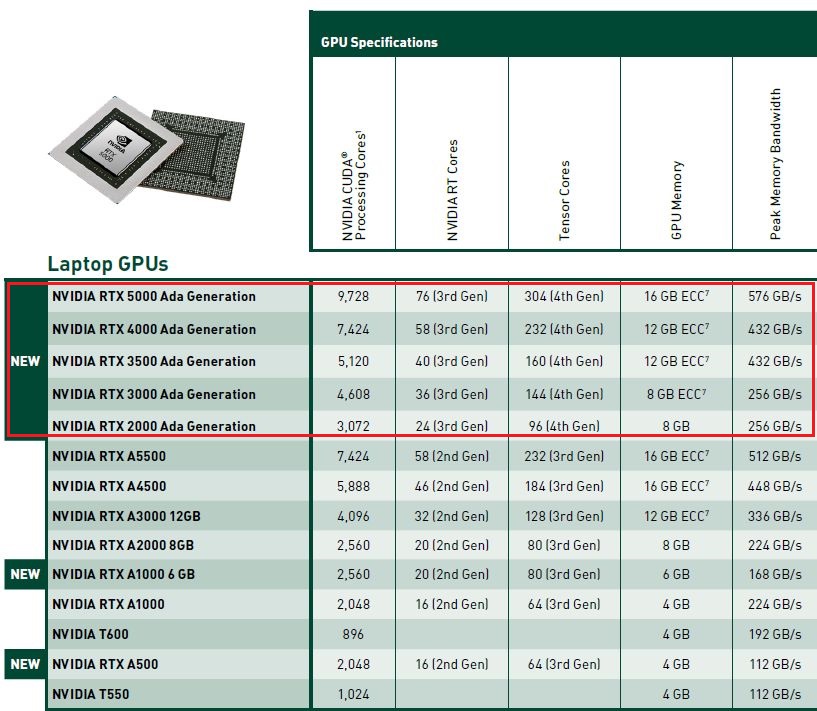
針對桌上型工作站,新增一款強調外觀尺寸較緊緻的RTX 4000 SFF;而在資料中心GPU的部分,Nvidia推出第二款採用Ada Lovelace架構的新機型L4,也是我們目前想先整理的產品。

若從公有雲業者來看,Google Cloud Platform預告將推出新的GPU執行個體服務G2,當中將採用Nvidia L4,
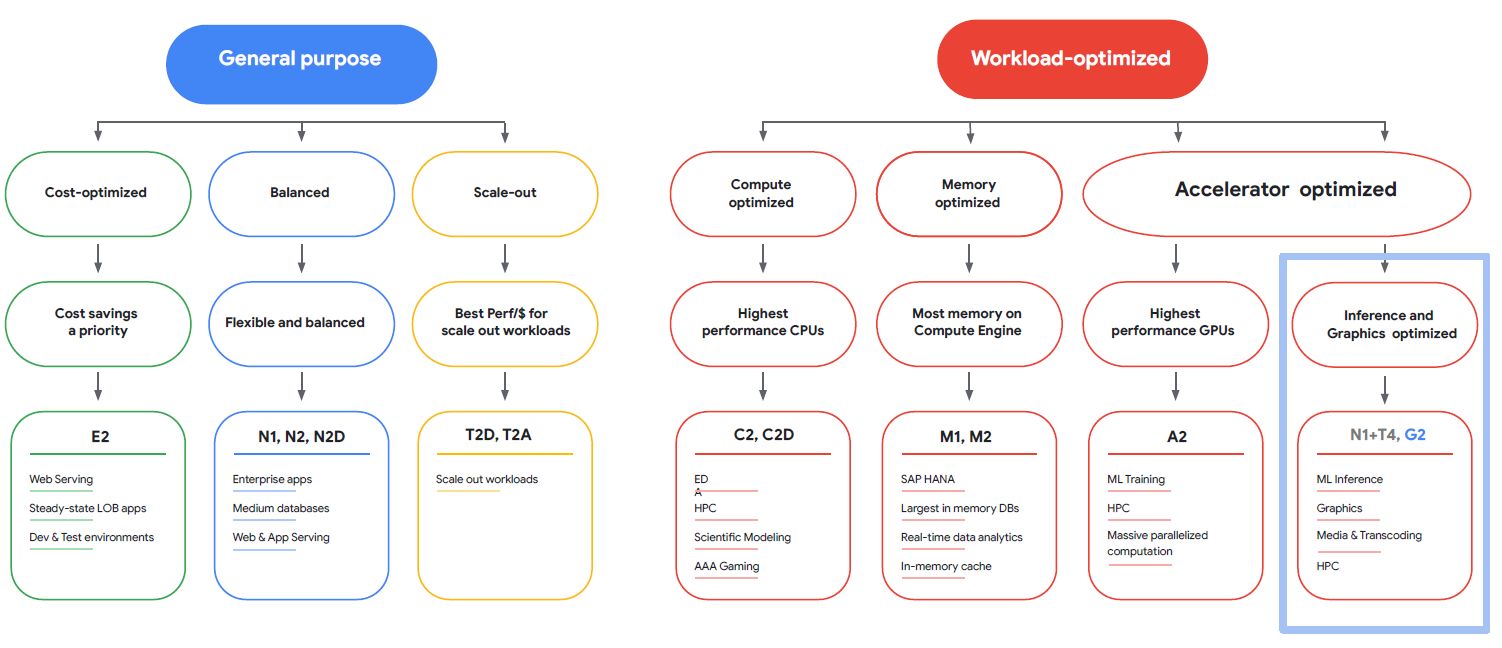
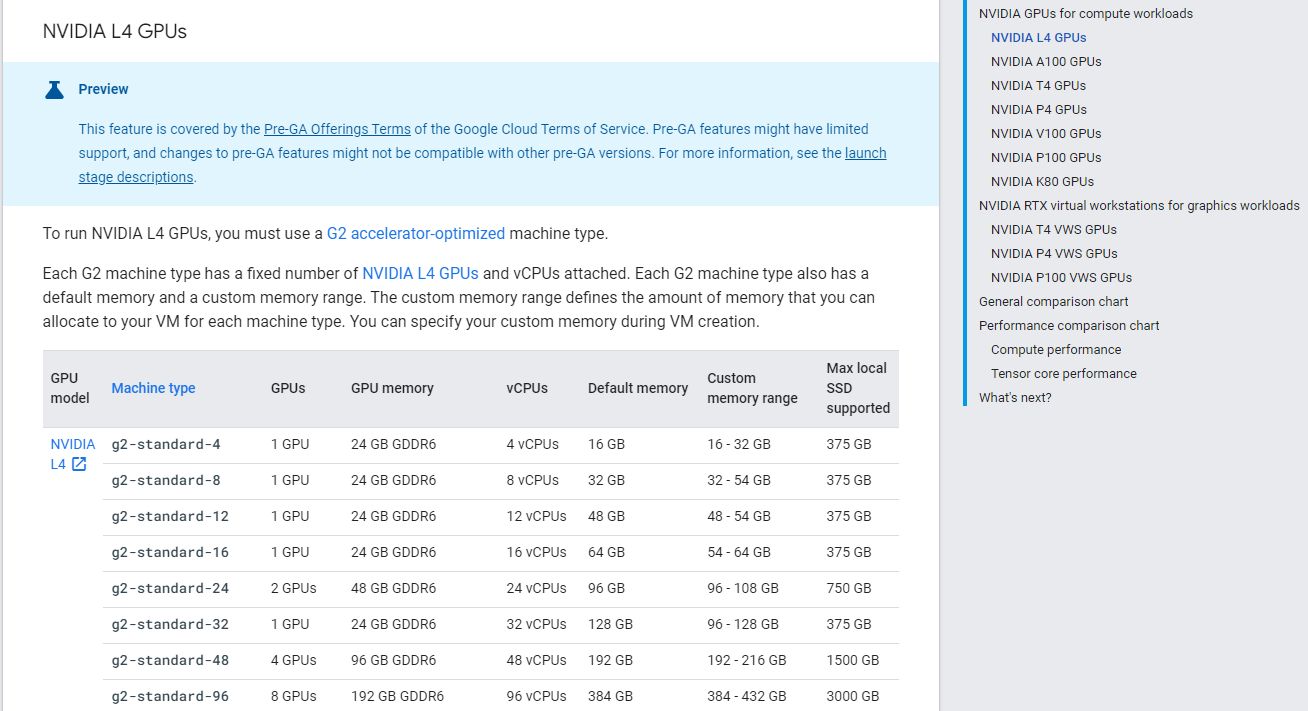
目前GCP此項服務已進入非公開預覽階段,先在us-central1、asia-southeast1、europe-west4這三個區域提供服務。
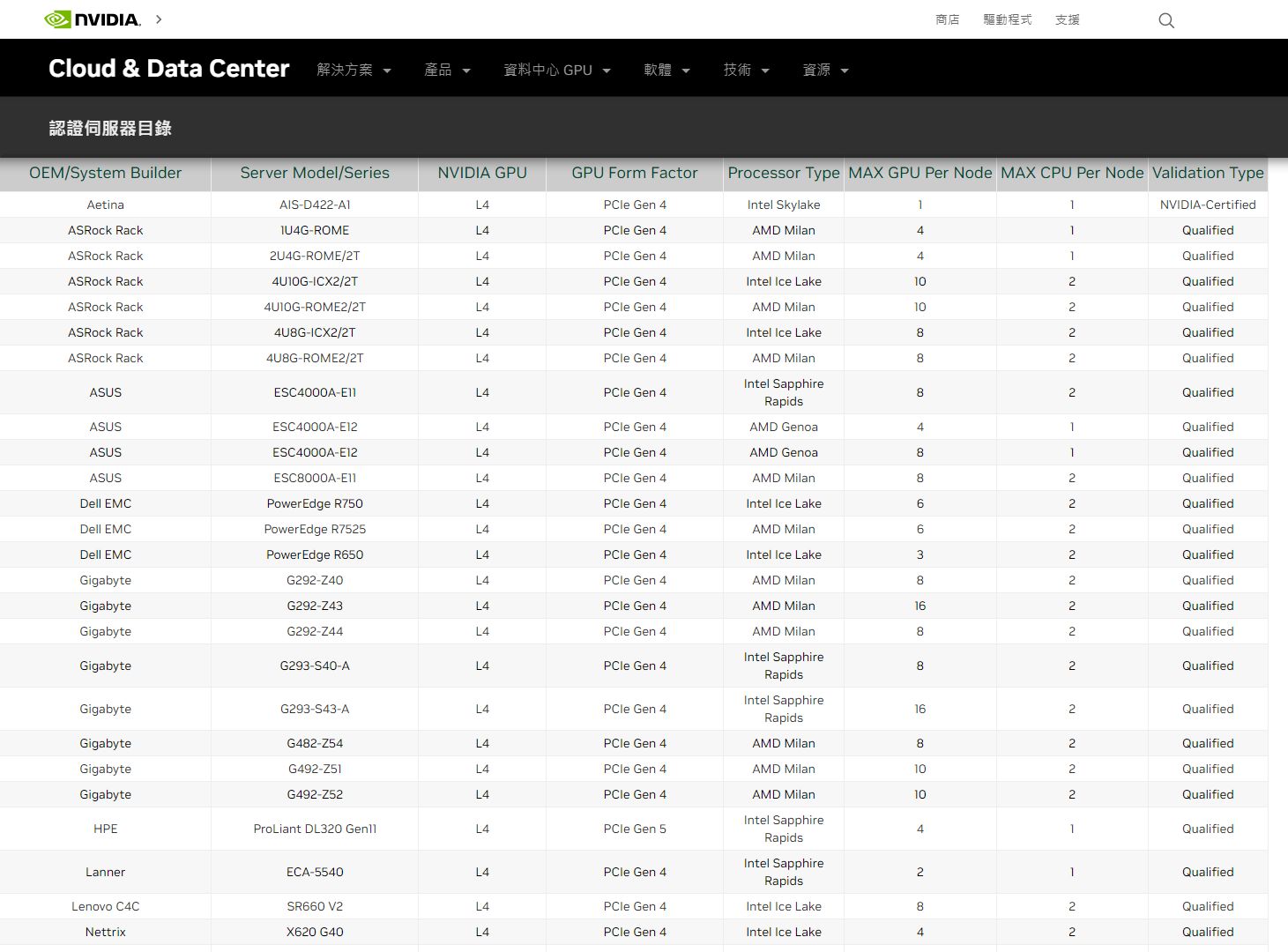
而在伺服器方面,Nvidia宣布超過30家廠商提供這款GPU。根據該公司的認證伺服器目錄來看,有12個廠牌、共40款機型,通過驗證。
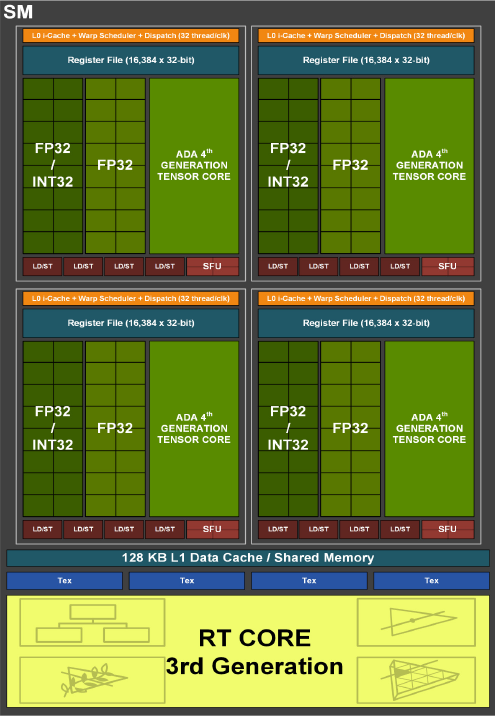
值得注意的是,相較於過去兩波產品發布,Nvidia此次也將Ada Lovelace架構白皮書更新至2.0版——當中除了依循1.01版白皮書,列出首波上市的GeForce RTX 4090(GPU代號AD102)、GeForce RTX 4080(GPU代號AD103),也納入今年第一季陸續登場的L40(GPU代號AD102)、L4(GPU代號AD104),這些GPU都採用同樣的基本架構。
就產品定位而言,L4還有一個任務,那就是接替4年前上市的通用型(universal)GPU產品T4,可因應AI影片處理、視覺運算、繪圖處理、GPU虛擬化/虛擬工作站、生成式AI,以及邊緣運算領域的眾多應用,可協助建立劇院等級的即時繪圖呈現,以及細節更為細緻的場景,提供沉浸式的視覺體驗。
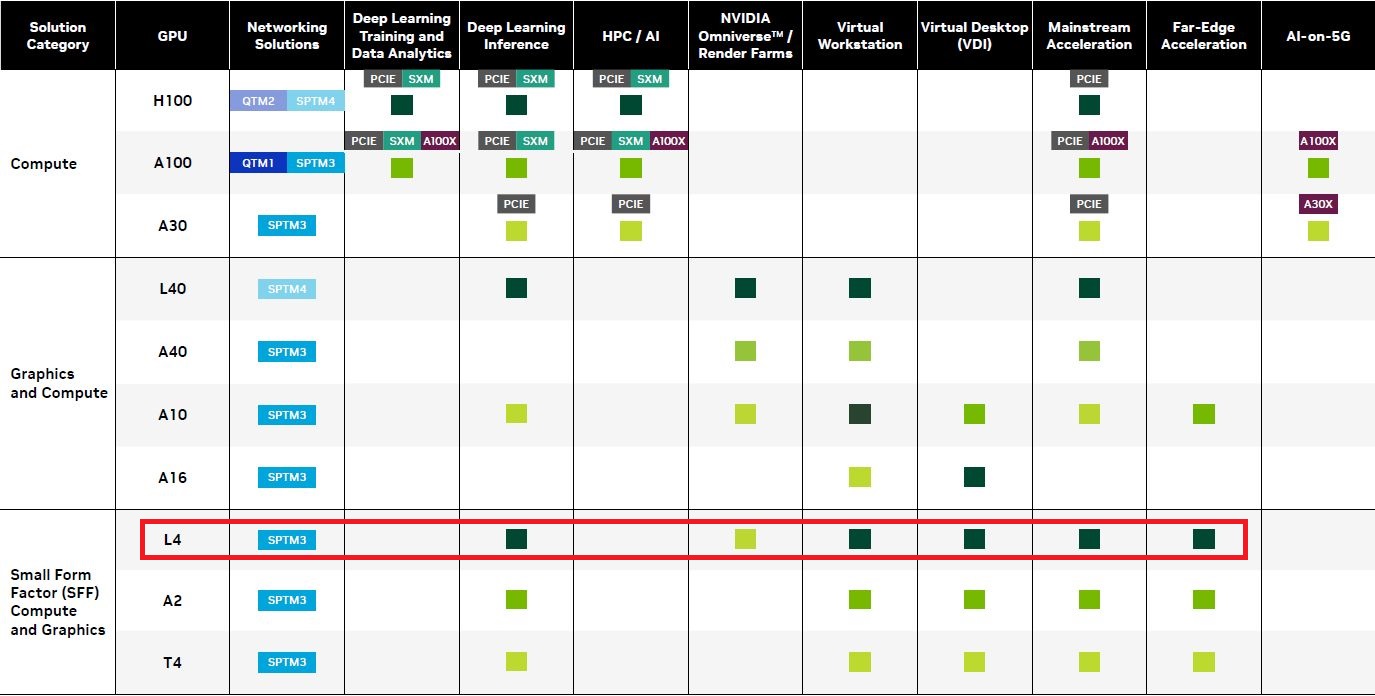
Nvidia表示,T4受到廣泛採用,目前是Nvidia出貨量最大的資料中心GPU(the highest-volume NVIDIA data center GPU)。雖然他們未公布數量,然而,三大公有雲業者都設有可搭配T4的執行個體服務(AWS Amazon EC2 G4dn系列、Azure NCasT4_v3 系列,以及GCP全球18個區域資料中心提供可搭配T4的執行個體服務);伺服器方面,根據Nvidia認證伺服器目錄網頁所示,目前有39個廠牌、旗下總共有444款機型。
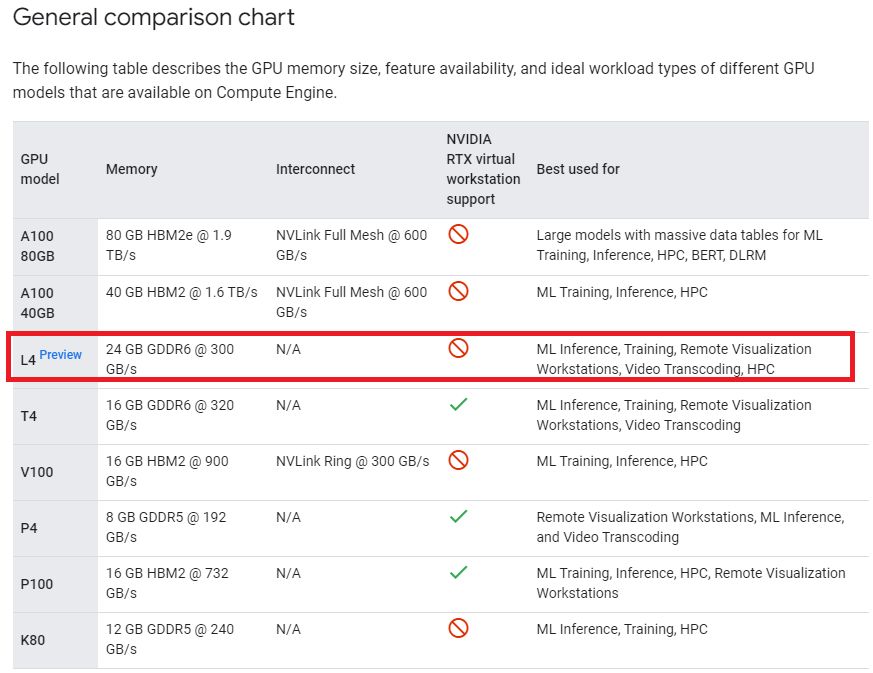
以軟硬體配備而言,Nvidia今年最新推出的L4有何特色?這款GPU內建7,424顆Ada Lovelace架構CUDA核心(T4為2,560顆Turing架構CUDA核心),232顆第四代Tensor核心(T4為320顆第二代Tensor核心),58顆第三代RT核心(T4為40顆第一代RT核心),24 GB GDDR6記憶體(T4為16 GB),以及採用PCIe 4.0介面(T4為3.0)。
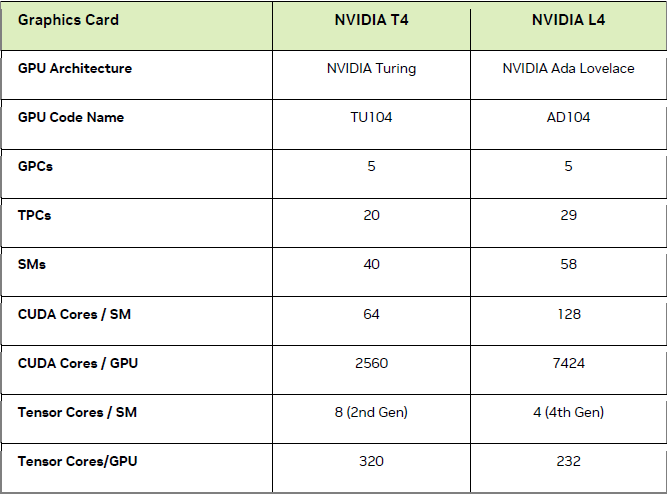

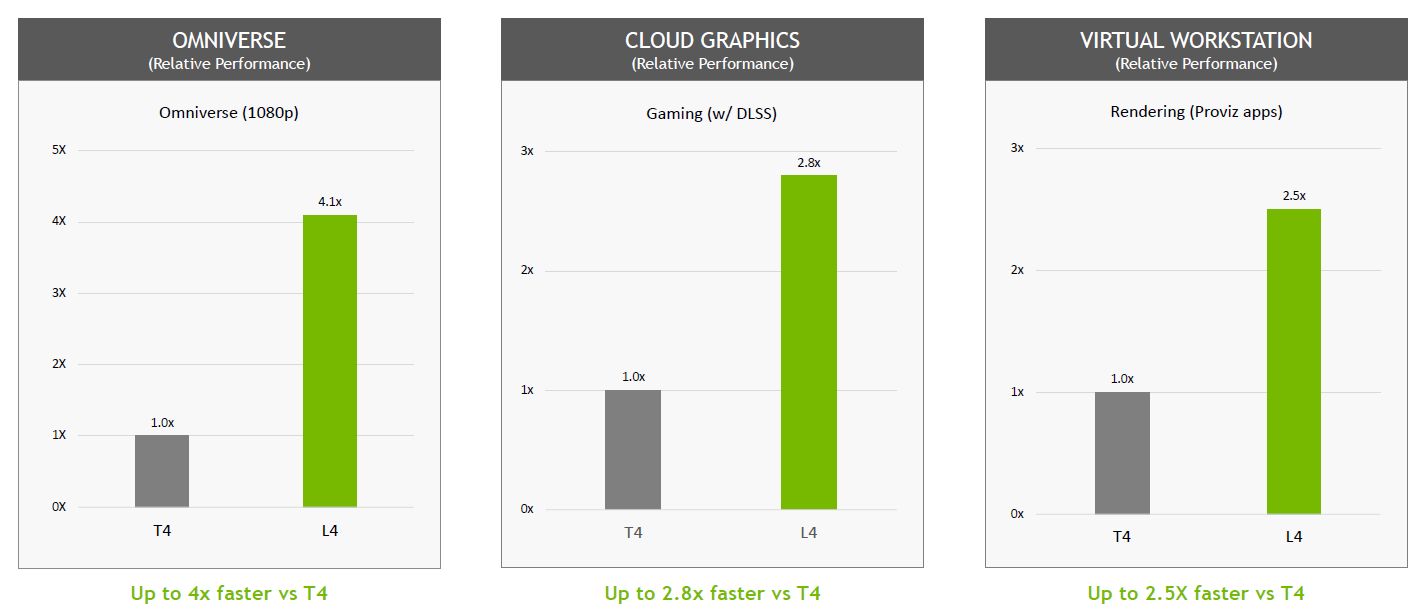
如果用於Nvidia發展的Omniverse元宇宙虛擬環境時,L4的能耐如何?根據他們的測試,在啟用DLSS 3技術的狀態中,對於AI替身(AI-based avatars)即時上色處理作業(Rendering),根據他們的測試,L4的效能可達到T4的4.1倍;若是用於雲端遊戲串流,L4對於光線追蹤技術的處理效能,則是T4的3.3倍,而其關鍵在於L4採用新一代RT核心。
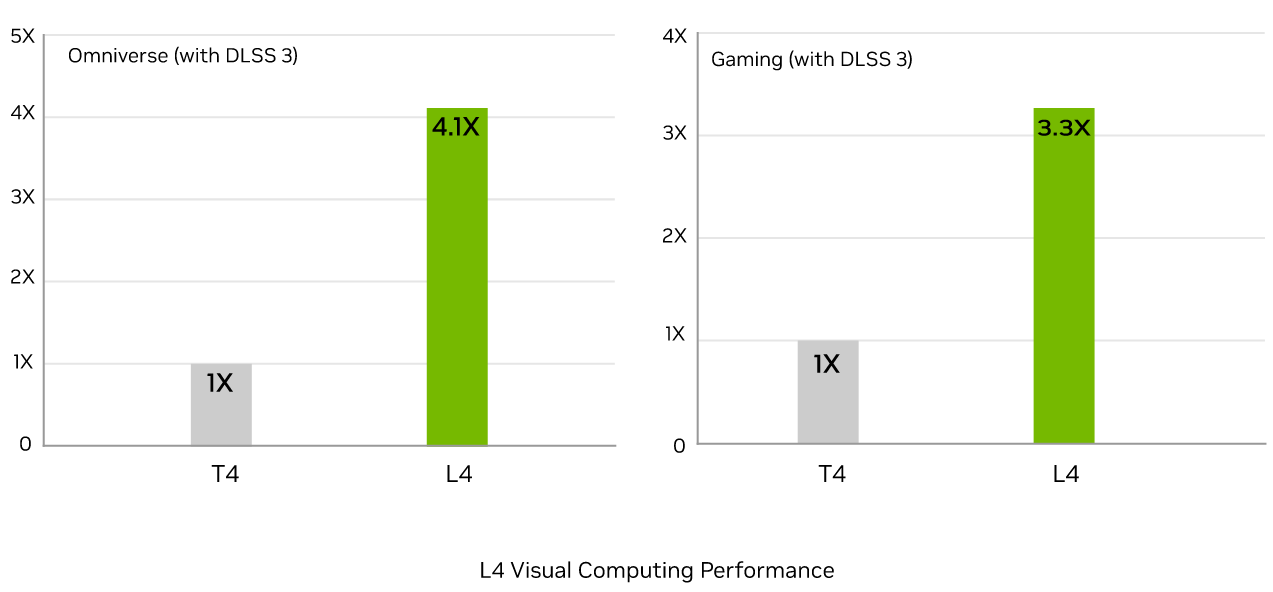
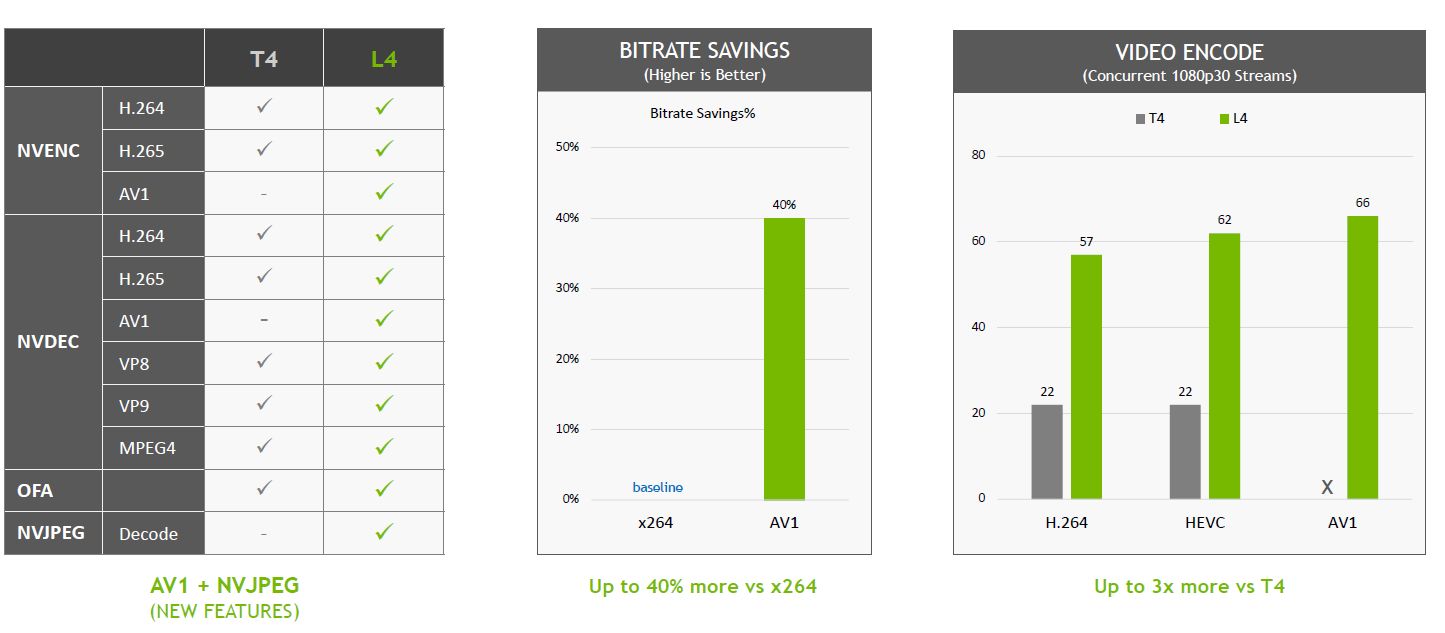
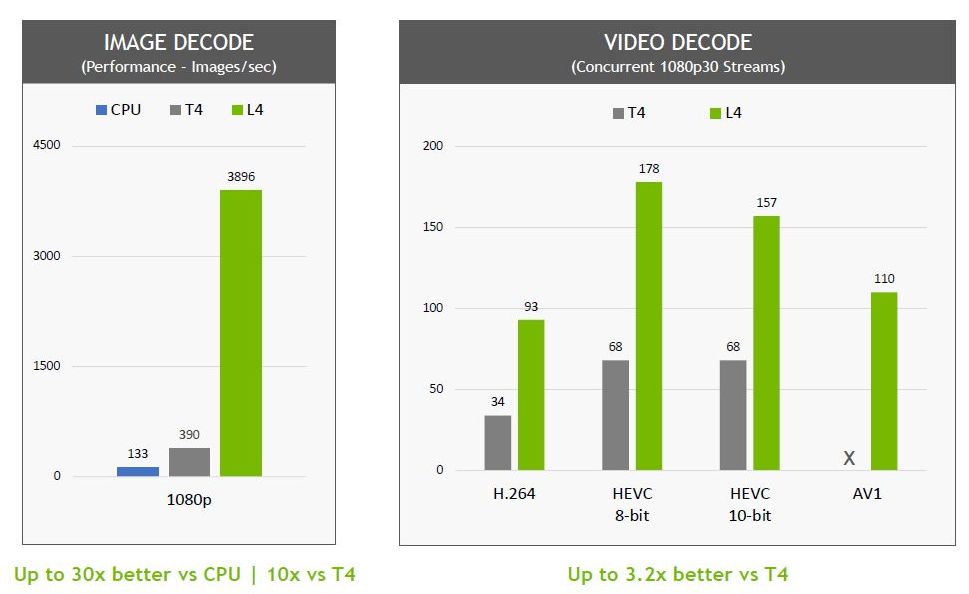
在圖片解碼的處理上,L4可提供10倍於T4的效能,而在視訊解碼的處理,L4可提供3.2倍的效能。
關於多媒體加速的外部用戶成效展現,Nvidia引述參與初期測試的社群網站SnapChat母公司Snap的看法指出,L4在視訊轉碼的效能可達到3倍以上。(Snap目前應該正在使用Nvidia T4,2021年3月該公司工程部落格曾公布AWS EC2 G4與GCP執行個體測試比較結果,使用的GPU正是Nvidia T4)
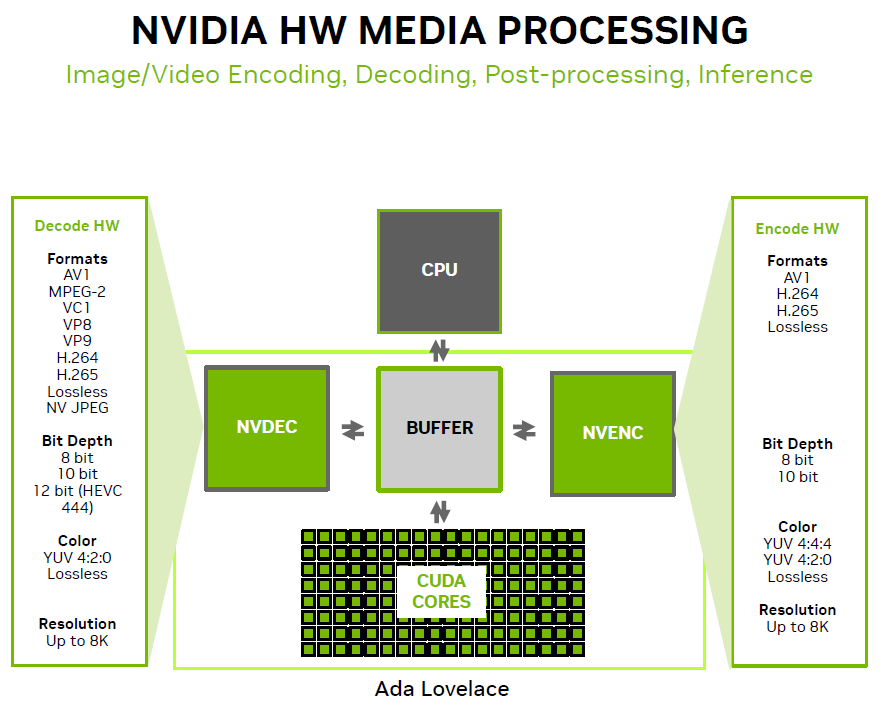
在生成式AI的應用上,若以T4為基準,新推出的L4可提供2.7倍的效能,由於內建的GPU記憶體容量增加50%(L4為24 GB,T4為16GB),所以,可處理更大尺寸的圖片生成處理(解析度最高為1024 x 768)。
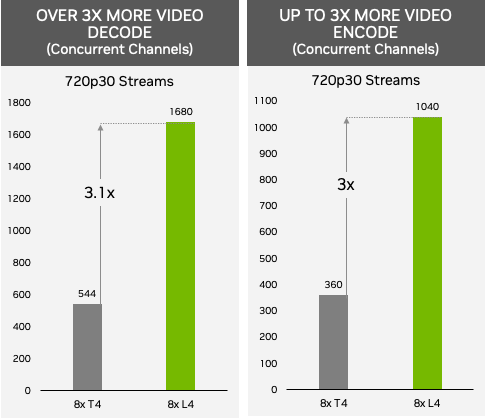
關於AI影片即時處理的需求,像是對數百萬觀眾進行視訊串流播放,或是提供沉浸式AR或VR體驗等應用,若由搭配8張L4的伺服器來提供服務,根據Nvidia的測試,可同時播放的720p30解析度手機視訊串流頻道,能提供1,000個以上(AV1編碼1,040個,H.264解碼1,680個),若搭配8張T4的伺服器,可同時播放的手機視訊串流頻道數量只有三分之一(H.264編碼360個,H.264解碼544個)。
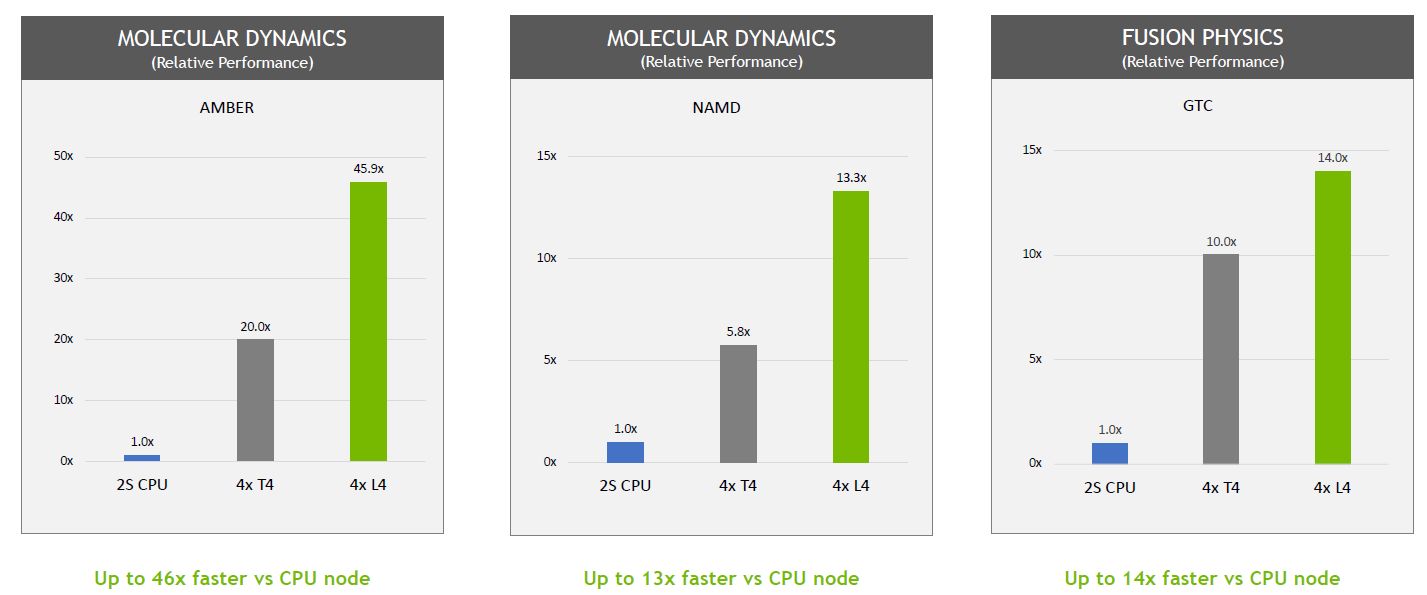
針對視覺運算(Visual Computing)、高效能運算(HPC)的多種應用需求,L4最高可提供4倍以上的效能。
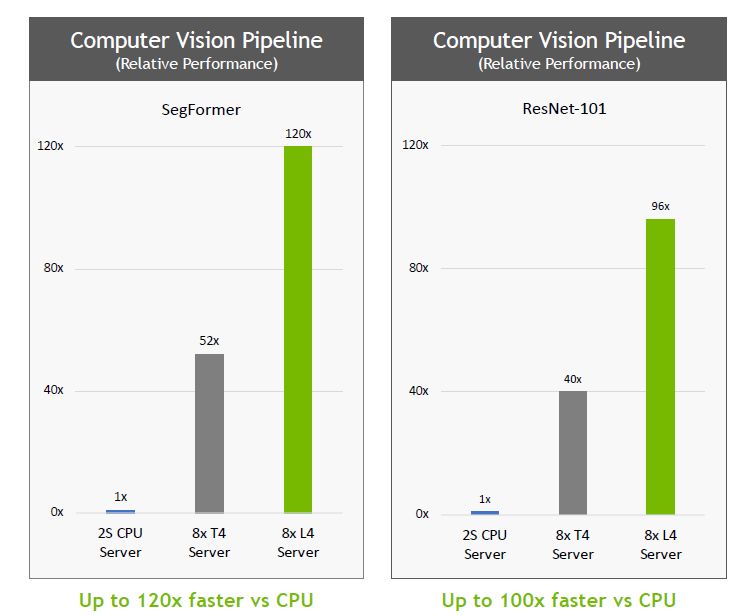
而在電腦視覺的應用上,L4搭配Nvidia本次GTC大會發表的CV-CUDA程式庫,由於它內建第四代Tensor核心、支援FP8精度,以及提供1.5倍的GPU記憶體容量,因此,可以在進行相關處理的每個環節,例如,影片、畫面輸入伺服器之後,以及從伺服器輸出之前的過程,如解碼、前處理、推論、後處理、編碼等階段,提供強大的運算處理效能。

若以採用英特爾Xeon Platinum 8380處理器的2路伺服器為基準,搭配8張L4的伺服器,可提供120倍的AI影片處理效能,企業與組織可藉此即時分析能力,提供個人化的內容推薦、改善搜尋相關性精準度、偵測物體類型的內容,以及建置智慧型環境空間解決方案。

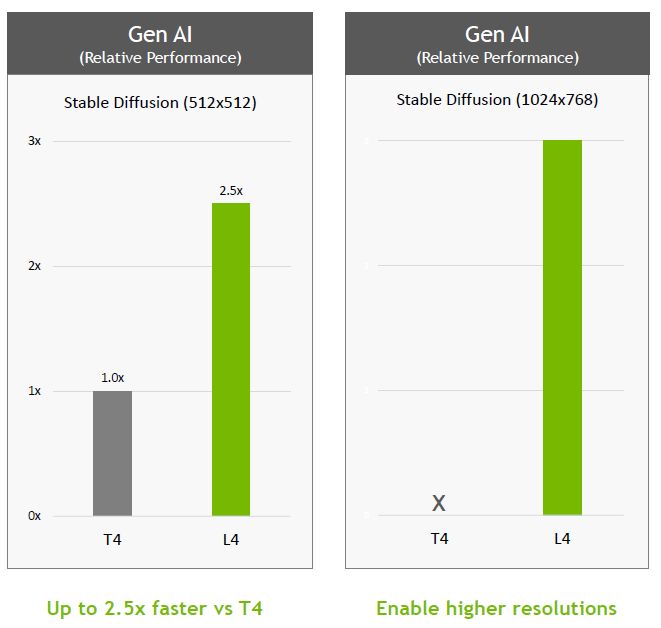
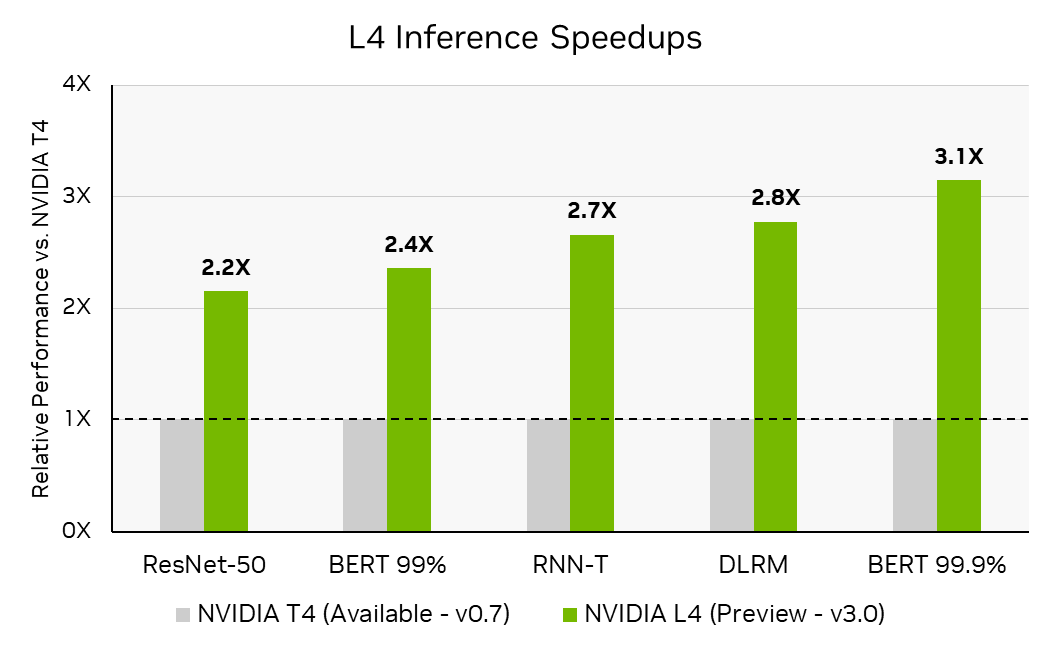
在4月5日公布的MLPerf Inference 3.0基準測試結果中,針對BERT模型精準度層級測試項目,L4的效能可達到T4的3倍,Nvidia認為原因是L4採用的Ada Lovelace架構,囊括支援FP8精度的第四代Tensor核心,而能在高精準度的要求之下,提供優異的效能。

另一個因素是L4配備更大容量的L2快取(48 MB),再加上MLPerf Inference 3.0實作兩個重要的軟體最佳化機制:快取常駐(cache residency)、快取持續管理(persistent cache management),而能善用L2快取。以前者而言,當MLPerf工作負載能夠全部載入GPU的L2快取之中,能享有比GDDR記憶體更高的頻寬與更少的耗電量。根據Nvidia的觀察,若以過去將批次處理的資料量設為最大值時的效能為基準,當這個資料量組態經過調校之後,能使整個工作負載完全置入L2快取,最高能獲得40%的效能提升。
而關於L2快取的持續使用特色,是Nvidia在現行主要GPU架構Ampere所開始提供的,開發者可運用這項功能,實現TensorRT的單一呼叫,當中可標記L2快取的子集合,使得這部份資源能優先予以保留,對於推論處理而言,此特色特別有用,因為在這樣的資源常駐管理機制之下,開發者可以在跨模型執行時,對準已重新用於分層啟動(layer activations)的記憶體進行處理,可動態減少GDDR記憶體的寫入頻寬耗用。
而在產品外形與節能減碳的效益上,L4與T4都有類似特性,例如均採用矮版、單槽尺寸的PCIe介面卡外觀,熱設計功耗均在70多瓦(L4為72瓦,T4為70瓦)。
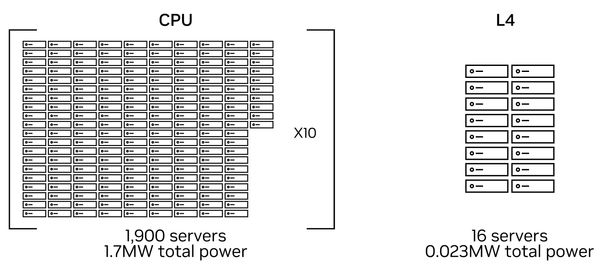
基於L4具有高能源效益的特色,Nvidia強調,搭配Nvidia L4的少量伺服器,足以取代基於CPU的大量伺服器。根據他們的評估,原本需1,900臺的純CPU伺服器進行電腦視覺處理,以及PyTorch推論,共耗費167.7萬瓦的電力,足以供應近2千個家庭1年電力所需,相當於17.2萬棵樹成長10年以上所能減少的碳排放量;若換成搭配8張Nvidia L4的GPU伺服器,並且使用Nvidia發展的CV-CUDA進行前處理與後處理,以及TensorRT推論平臺,只需用到16臺伺服器,總電力耗費可大幅降至2.3萬瓦。
產品資訊
Nvidia L4
●原廠:Nvidia
●建議售價:廠商未提供
●架構:Ada Lovelace
●代號:AD104
●CUDA核心數量:7,424個
●Tensor核心數量:232個(第四代)
●RT核心數量:58個(第三代)
●內建記憶體容量:24 GB GDDR6
●記憶體頻寬:300 GB/s
●視訊處理引擎:2個編碼器、4個解碼器、4個JPEG解碼器
●連接介面:PCIe 4.0 x16
●支援NVLink:否
●FP32單精度浮點運算效能:30.3 TFLOPS
●外觀尺寸:單槽矮版
●耗電量:72瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10