
在去年5月底ISC超級電腦大會之後,英特爾預告併購Habana Labs而得到的AI加速器Gaudi系列,將推出第三代產品,到了12月中該公司舉辦的AI Everywhere發表會,執行長Pat Gelsinger首度公開展示Gaudi 3晶片,並預告2024年將依照原先的時程推出。



今年4月英特爾召開的Vision年度用戶大會期間,Gaudi 3正式發表,將於第二季上市,初期將透過Dell、HPE、聯想、Supermicro 這4家伺服器廠商供應。


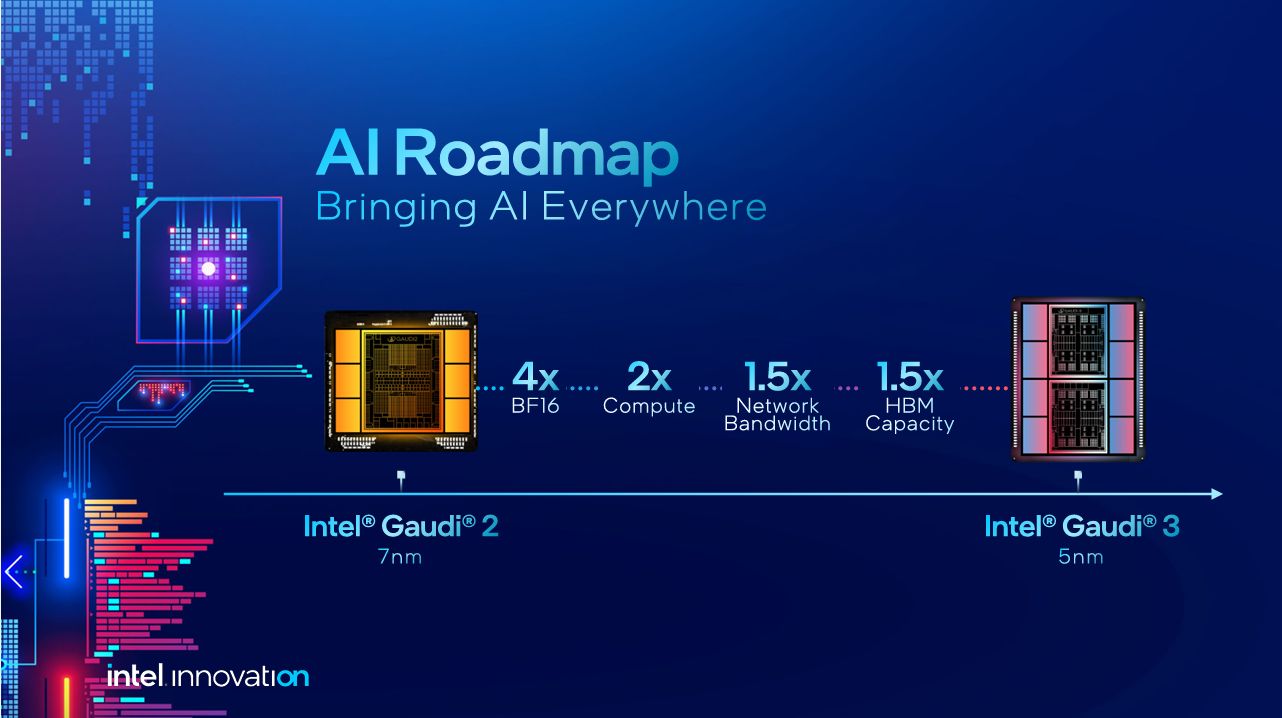
相較於既有的Gaudi 2,Gaudi 3在BF16矩陣乘法運算的表現暴增至4倍(1,835 TFLOPS對上432 TFLOPS),FP8矩陣乘法運算的表現提升至2倍(1,835 TFLOPS對上865 TFLOPS),記憶體頻寬增加至1.5倍、2倍(HBM頻寬3.7 TB/s對上2.46 TB/s,SRAM頻寬12.8 TB/s對上6.4 TB/s)。

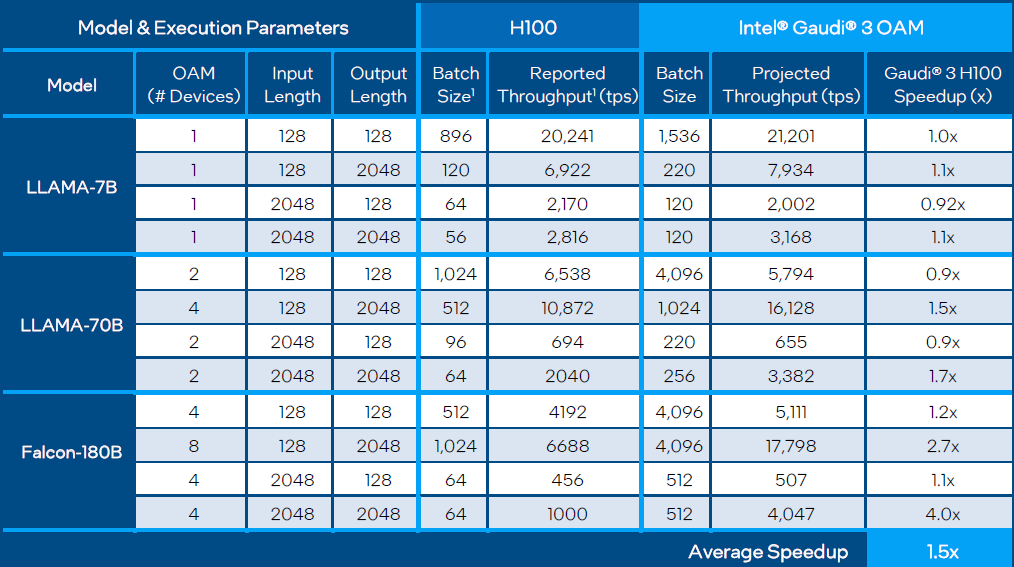
那麼,比起市面上最搶手的資料中心GPU產品Nvidia H100,Intel Gaudi 3的勝算在哪裡?
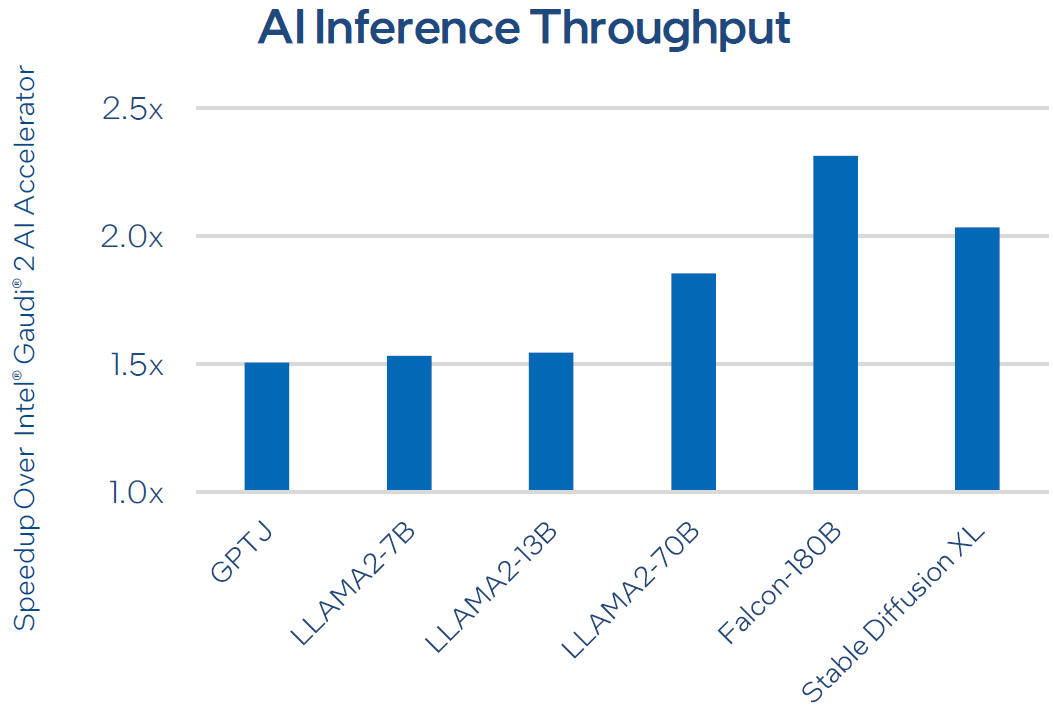
英特爾預估這款新一代AI加速器,用於常見的大型語言模型的訓練(Llama2-7B、Llama2-13B、GPT3-175B),平均耗費時間縮短50%;用於常見的大型語言模型的推論(Llama2-7B、Llama2-13B、Falcon-180B),平均吞吐量可領先50%,能源效益超越的比例是40%。

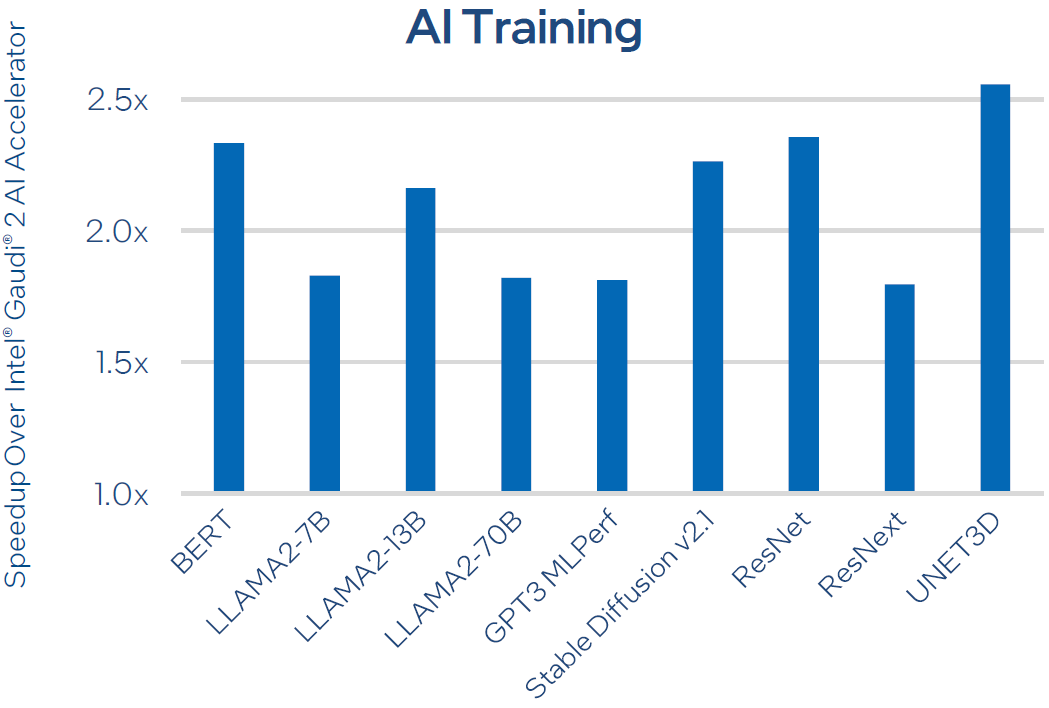
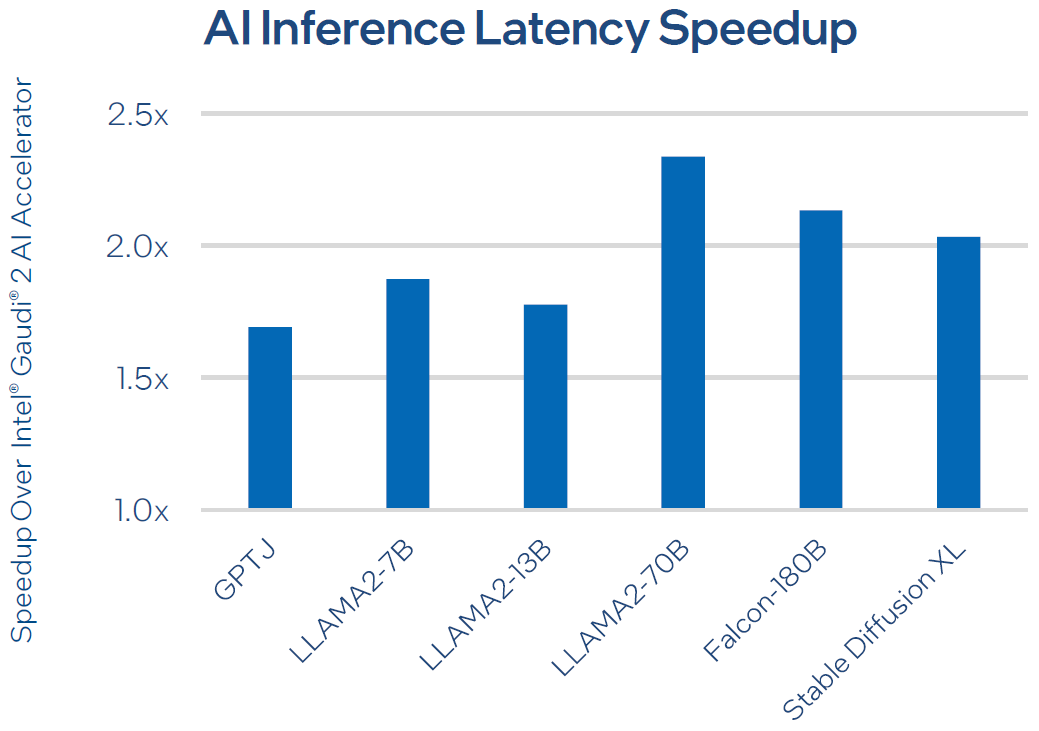
而就網路存取效能而言,每個Intel Gaudi 3的尖峰I/O吞吐量也比Nvidia H100高,差距比例為33%(1,200 Gb/s對上NVLink的900 Gb/s)。
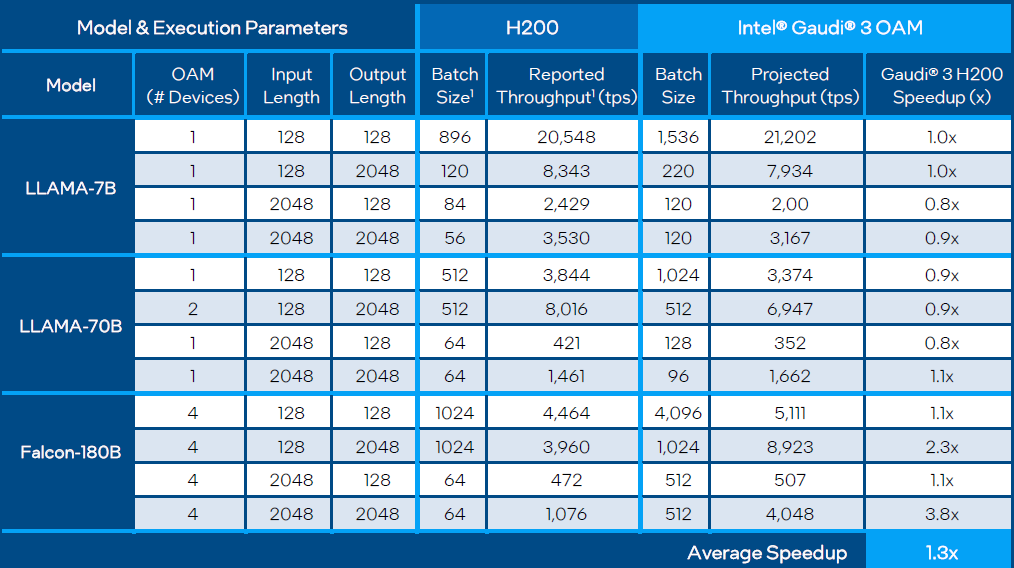
相較於Nvidia即將推出的H100加強版H200,由於其配備容量更大(141 GB)、速度更快的高頻寬記憶體(HBM3e),來勢洶洶,Intel Gaudi 3的AI運算效能仍能繼續勝出嗎?根據英特爾的預估,用於常見的大型語言模型的推論(Llama2-7B、Llama2-13B、Falcon-180B),速度領先幅度可達到30%。
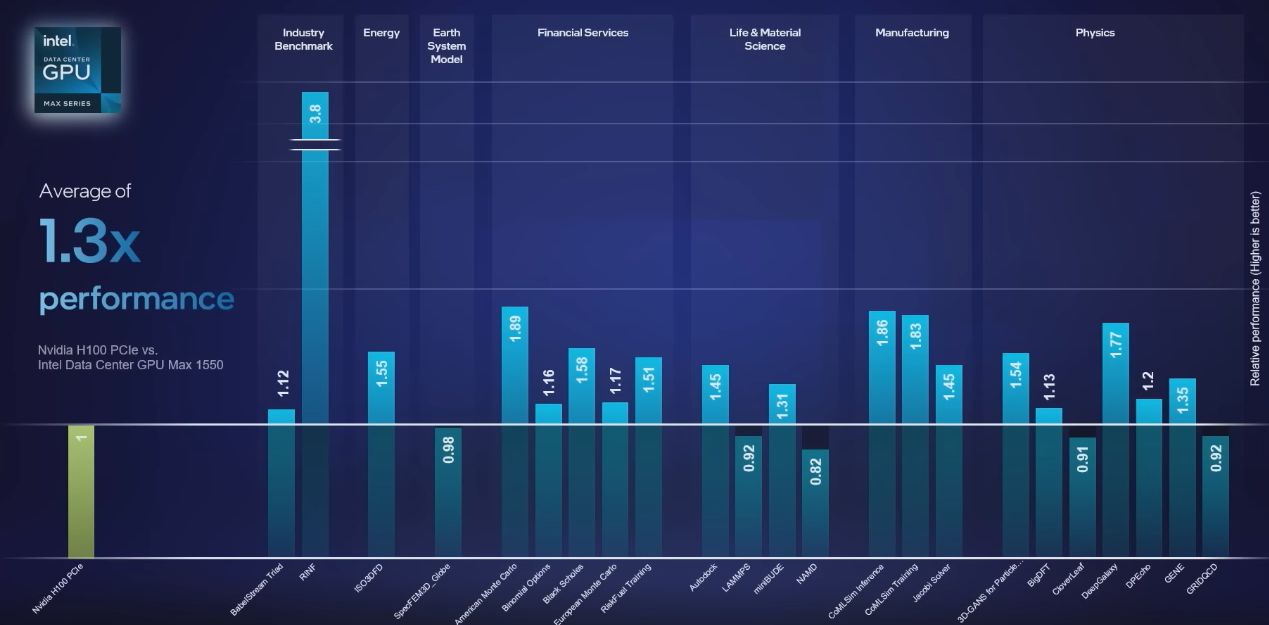
在此之前,市面上陸續出現多款加速運算產品向Nvidia H100 GPU下戰帖。例如,英特爾2022年發表的Data Center GPU Max,2023年5月他們表示,針對多種工作負載,平均可領先Nvidia H100 PCIe的幅度為30%;11月他們揭露Data Center GPU Max 1550,針對多種高效能運算工作負載,平均可領先36%。
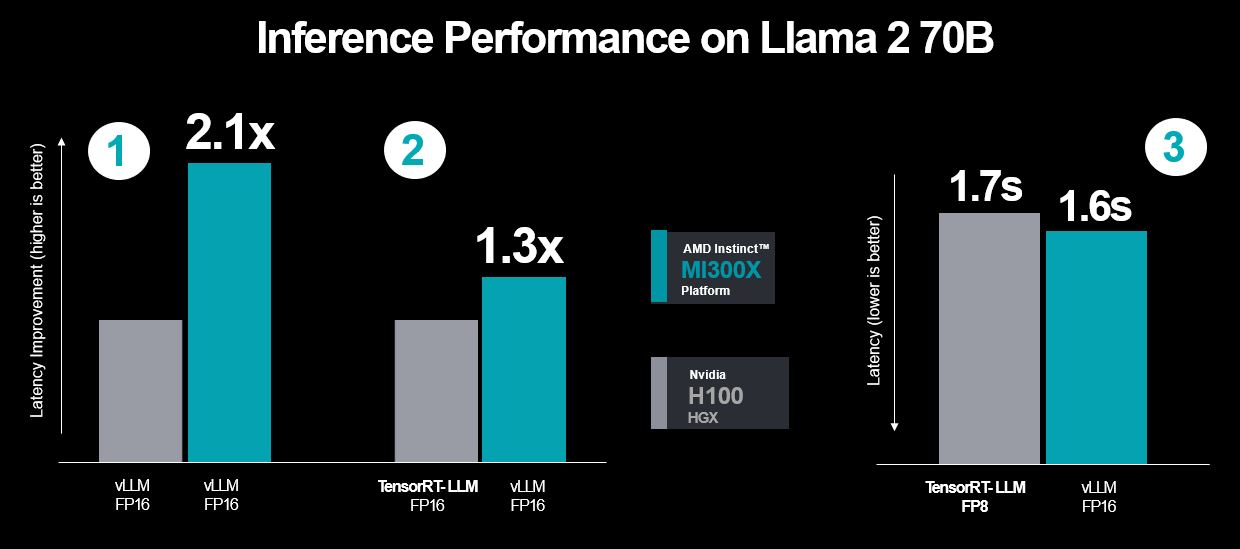
AMD 2023年12月發表的Instinct MI300X,號稱在執行大型語言模型BLOOM-176B的推論,吞吐量可達到Nvidia H100的1.6倍,若用於Llama2-70B,延遲改善度達到1.4倍,套用後續的調校可增長至2.1倍,
至於英特爾Gaudi 2,2022年5月推出,11月曾與預覽版本狀態的Nvidia H100比較效能,在ResNet-50 的AI訓練時間上,Nvidia H100領先幅度為11%,而在 BERT的AI訓練時間上,Nvidia H100領先幅度為59%;
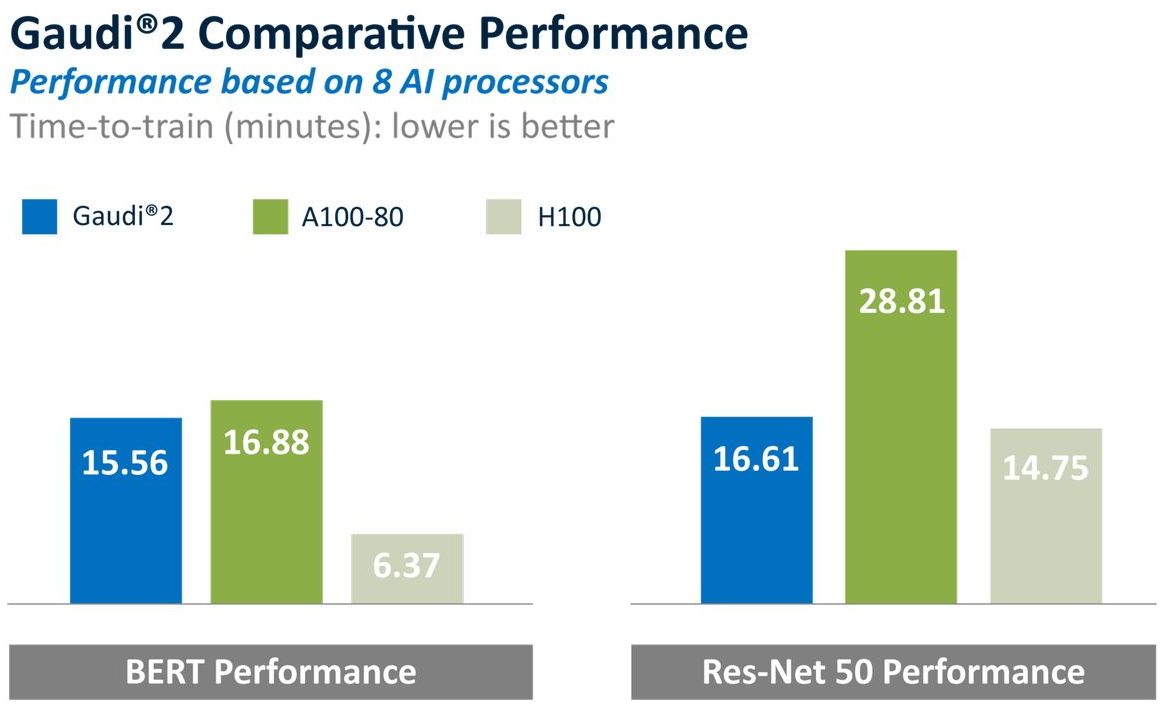
2023年5月,開放原始碼AI社群Hugging Face表示,若使用上架在此的Optimum Habana 1.7版,處理視覺—語言模型BridgeTower的速度可達到Nvidia H100的1.4倍。
Intel Gaudi 3內建數量更多的新一代矩陣乘法引擎與張量處理器核心,配置更大容量的高頻寬記憶體,支援的大量網路介面也升級至200GbE規格
就產品製作與組成方式而言,Intel Gaudi 3導入更先進的台積電5奈米製程(Gaudi 2導入台積電7奈米製程),並採用Intel與Habana Labs共同發展的第五代異質AI加速架構。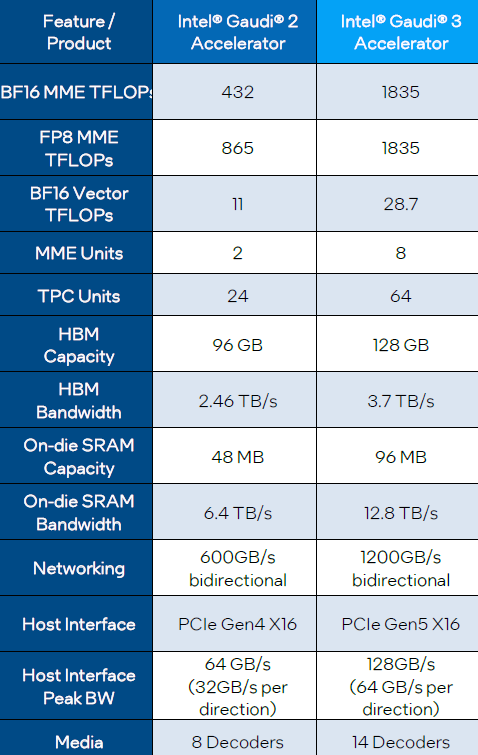
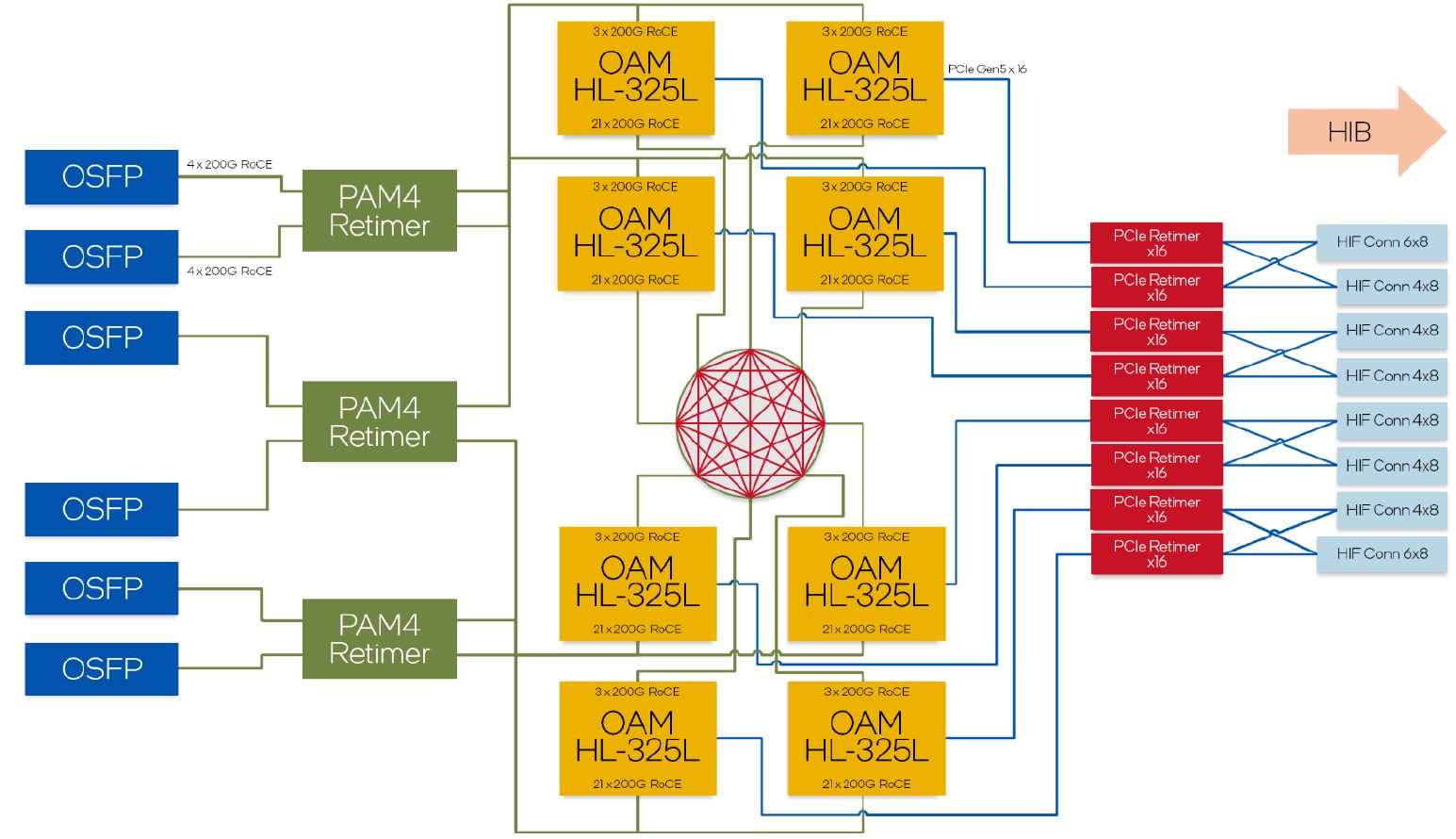
以單顆晶片而言,Intel Gaudi 3改為內建兩顆運算晶粒,當中各自囊括4個矩陣乘法引擎(MME)、32個具備完整可程式化功能的張量處理器核心(TPC)、可支援12個200 Gb/s連線頻寬的乙太網路介面,以及48 MB容量的動態隨機存取記憶體(SRAM)。而在兩個晶粒之外,這裡還設置8個16 GB容量HBM2e記憶體晶片,以此組成128 GB容量的統一存取記憶體。
關於Intel Gaudi 3採用的新一代MME引擎,英特爾也透露最顯著的特色是能夠平行處理6.4萬個作業,提供相當高的AI運算速度與效率,足以因應複雜的矩陣運算,進而能提升深度學習效能,而且此元件同樣支援FP8、BF16等多種資料型別,提供1.8 PFLOPS效能。
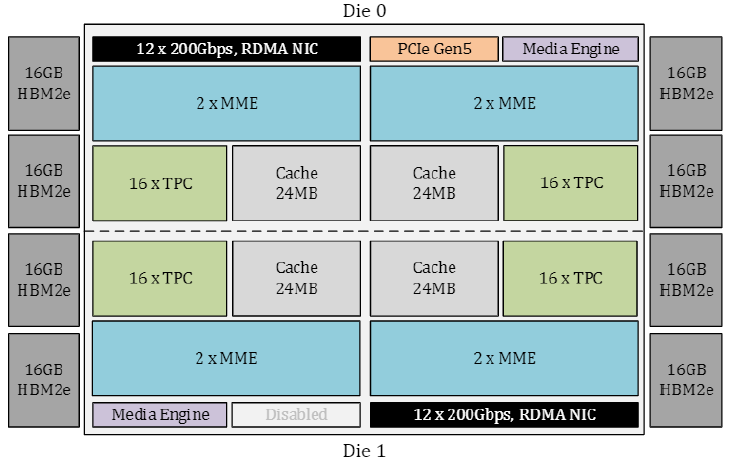
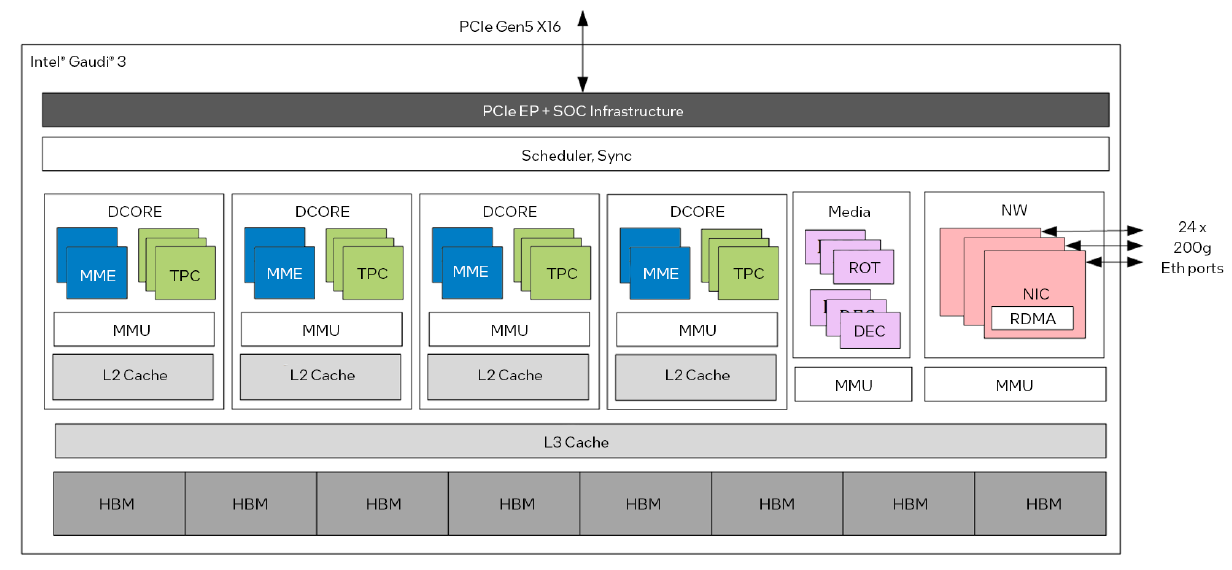
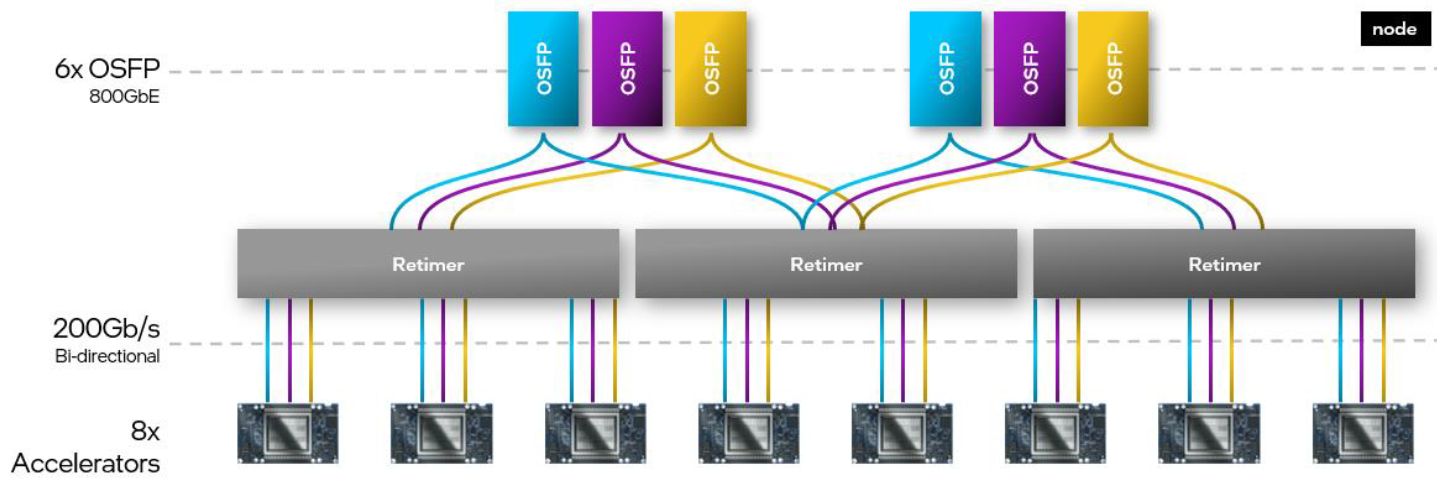
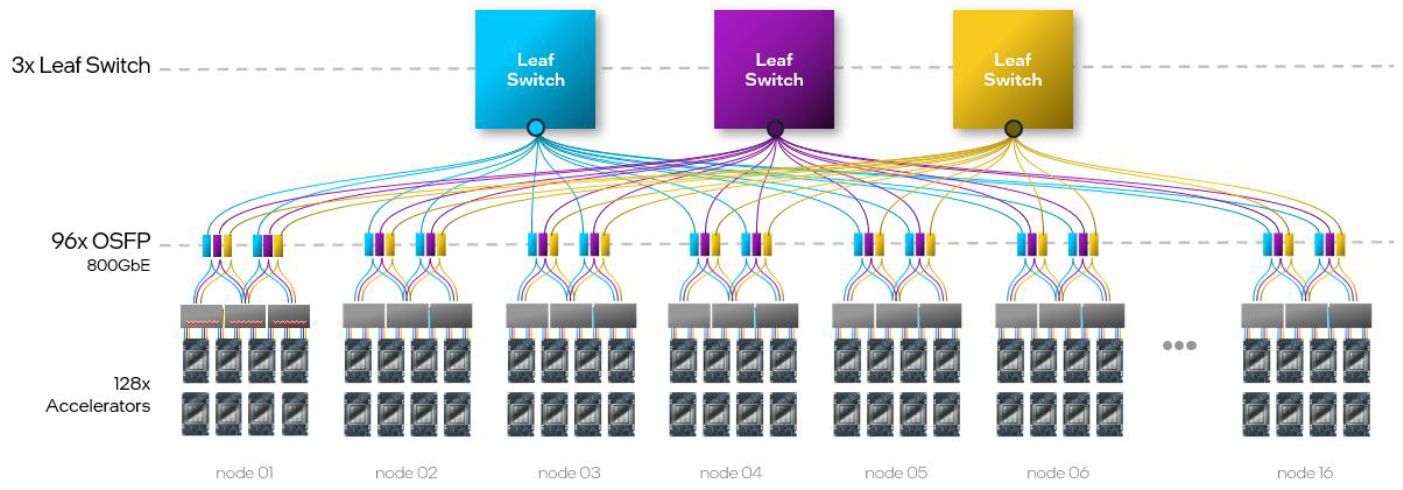
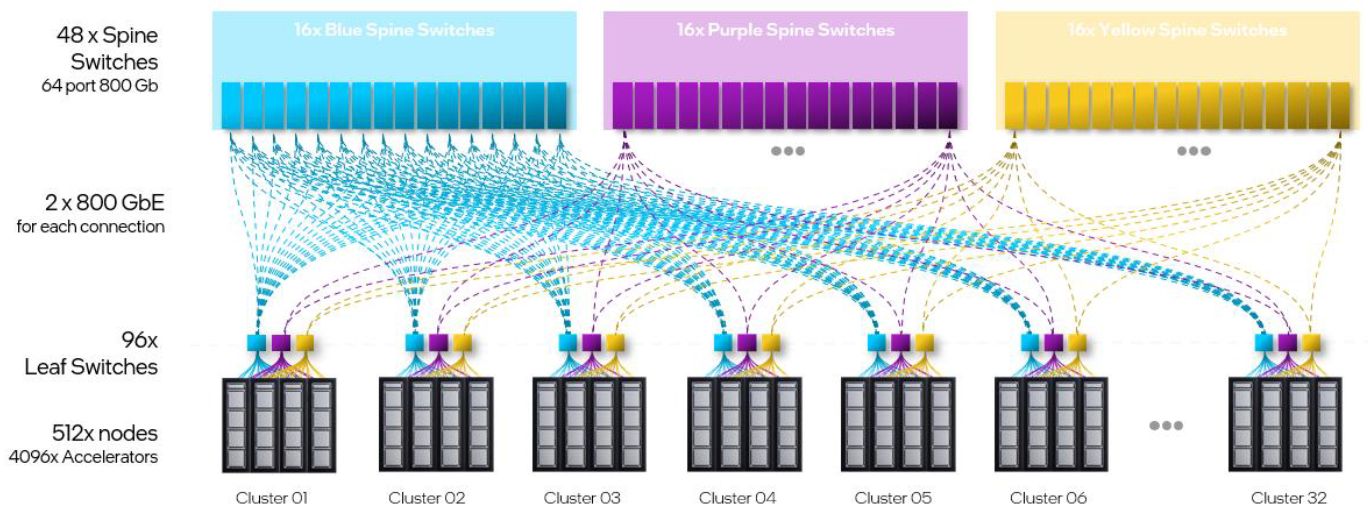
採用開放的網路技術與軟體開發環境,也是Intel Gaudi系列的重要賣點。以前者而言,Intel Gaudi 3內建大量支援超高速乙太網路技術的連線介面,能夠更直接用於大型運算叢集的部署,能夠避免被採用專屬網路技術的廠商綑綁,在執行規模的彈性配置上,可以透過有效率的方式進行縱向擴展(scale up),以及橫向擴展(scale out),將運算叢集的規模拓展至數千臺節點,以因應生成式AI模型工作負載的快速成長。

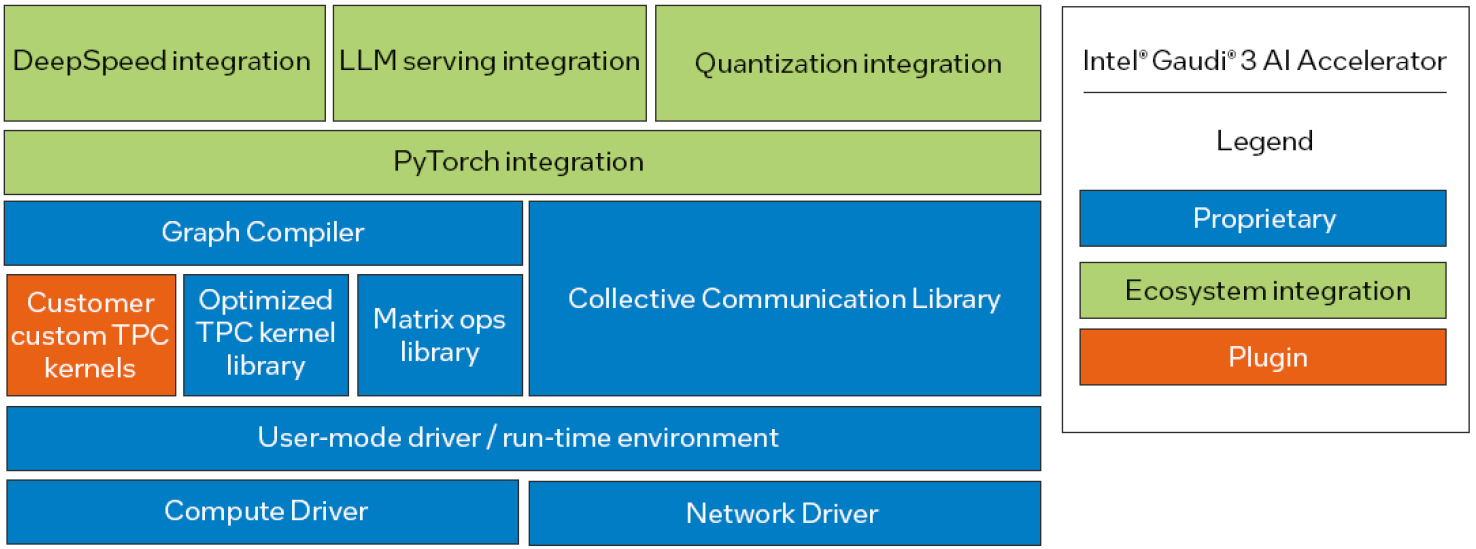
對於AI應用程式開發需求而言,英特爾與Habana Labs提供Intel Gaudi軟體,包含效能最佳化底層元件Graph Compiler、軟體開發套件TPC SDK,以及常用演算法(Paged Attention、Flash Attention)的重新訂製實作。
而且,這項軟體平臺已整合PyTorch框架,以及其他常用的AI軟體套件,像是用於分散式訓練與推論的DeepSpeed,使用Transformer、Diffusers模型的Hugging Face,為了衝高大型語言模型處理吞吐量的vLLM。
在產品外形上,Gaudi 3不只是比照Gaudi 2,同樣提供遵循OAM模組規格的夾層卡,以及內建8臺OAM模組的基板(Baseboard),但這一代額外提供PCIe介面卡,以及匯聚4張PCIe介面卡的載板(Top-Board)。

然而,除了外形的差異,引發全球眾多科技與財經媒體的關切之處在於,英特爾竟然直接表明Gaudi 3區隔為兩大市場供應,分成專門提供中國用戶的款式,以及中國以外用戶的款式,並且特別列出5種款式的上市時程,以及彼此之間的共通點與差異。
例如,現在若要採購OAM外形的Gaudi 3,中國以外的用戶可選擇3月上市的HL-325L;中國用戶只能選擇HL-328,英特爾預計6月供應;若要採購支援液冷的OAM外形Gaudi 3,中國以外的用戶可選擇HL-335,英特爾預計10月供應。
若要採購PCIe介面卡外形的Gaudi 3,預計9月上市,中國以外的用戶可選擇HL-338,中國用戶只能選擇HL-388。
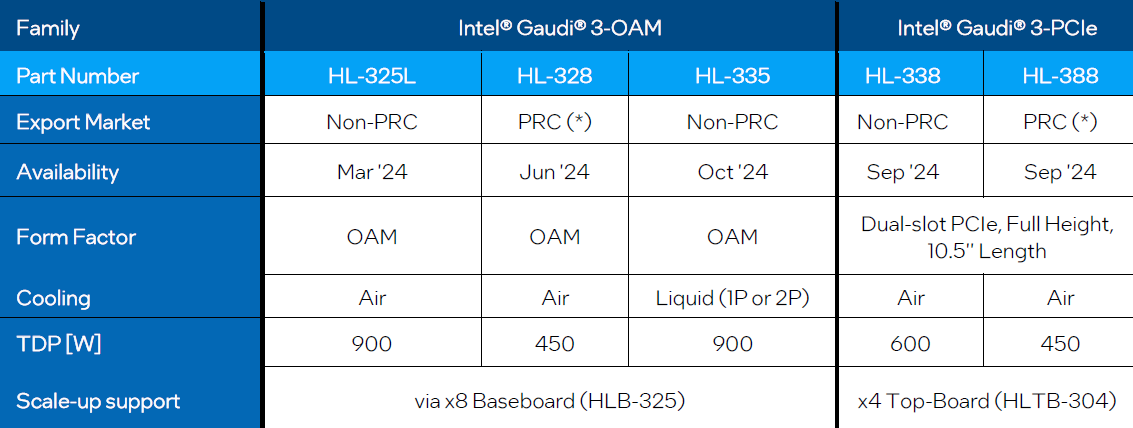
這5款的相同之處在於HBM記憶體的容量(128 GB)、尖峰存取頻寬(3.7 TB/s)、介面(1024位元 x 8 stacks)、類型(HBM2e),末級快取記憶體(SRAM)容量(96 MB),主機連接介面(PCIe 5.0 x16),以及多媒體解碼器(支援HEVC/H.265、AVC/H.264、VP9、JPEG)。
而被認定為中國市場專用版的HL-328、HL-388,英特爾標示的最大差異在於熱設計功耗較低,例如,同為OAM外形,HL-325L與HL-335熱設計功耗為900瓦,HL-328卻只有450瓦;同為PCIe介面卡外形,HL-338熱設計功耗為600瓦,HL-388只有450瓦。
這樣的規格差異,顯然是為了符合美國對於AI晶片的出口管制規定。根據科技媒體The Register的推算,Gaudi 3若要賣到中國市場,勢必要大幅削減運算效能,可能會透過縮減核心數量、時脈執行速度,或其他限制效能的手段,才能達到這樣的要求。
產品資訊
Intel Gaudi 3
●原廠:英特爾
●建議售價:廠商未提供
●產品外形與款式:OAM夾層卡HL-325L、HL-328、HL-335,基板HLB-325(連接8張HL-325)、HLTB-304(連接4張HL-338),PCIe介面卡HL-338、HL-388
●製程:TSMC 5奈米
●I/O介面:PCIe 5.0 x16
●核心架構:64個第5代張量處理器核心、8個矩陣乘法引擎
●記憶體:96 MB SRAM搭配128 GB HBM2e
●網路埠:24個200 GbE
●耗電量:OAM夾層卡HL-325L為900瓦,基板HLB-325為7,600瓦,PCIe介面卡HL-338為600瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-09

2026-02-09