雖然只要用Windows就能建立一個Hadoop的實驗環境,然而Windows版本存在著許多小問題,像是Cygwin的路徑與Java Runtime認知的Windows路徑不同,因此許多時候,你在下指令的時候,還必須要透過cygpath指令將Cygwin路徑轉換成Windows路徑,相當不便。其次,假設你想要把多臺Hadoop4win串起來,有許多先決條件,像是必須要有不同的電腦名稱、要有相同的使用者名稱跟檔案存取權限。因此,一般我們在提供商業運轉的Hadoop環境時,仍舊會採用Linux版本。
雲端運算的五大基礎特徵中,第一點是「隨需自助服務」,其背後隱藏著「標準化」與「自動化」的精神。本文為了讓每位讀者能有標準化的實作環境,免除不同Linux版本造成的操作問題,此次採用的是中華電信hiCloud的Ubuntu 10.04虛擬機器當作示範架設Hadoop叢集版的環境。底下將示範如何在十臺Ubuntu 10.04的虛擬機器上,建置一個Hadoop叢集。由於Hadoop安裝的指令繁瑣,筆者這裡提供一個自動化的安裝腳本程式,各位可至http://github.com/jazzwang/hicloud-Hadoop或http://hidooop.sf.net下載原始碼。以下我們用圖解的方式,說明如何使用hicloud開啟十臺虛擬機器,並設定成Hadoop叢集。
Step 1
連線至hicloud.hinet.net並點選右上角「客戶登入」
Step 2
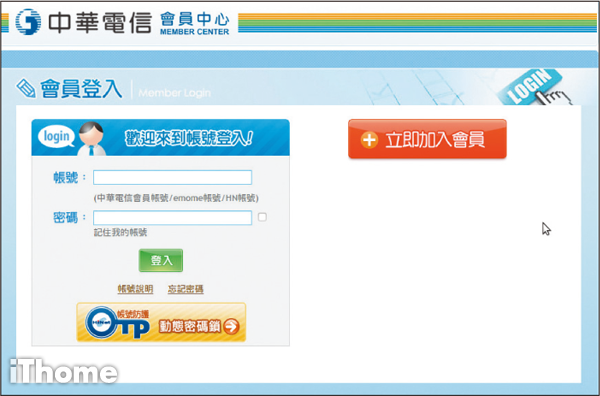
若你不是中華電信用戶,先加入會員,然後用取得帳號登入

Step 3
點選上方「雲運算」
Step 4
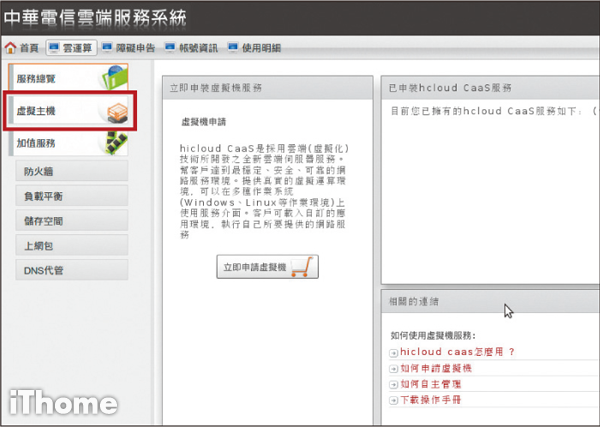
點選左方「虛擬主機」

Step 5
點選左上角「申請」

Step 6
確認同意中華電信hicloud租約選擇「Linux微運算型XS」,按「下一步」
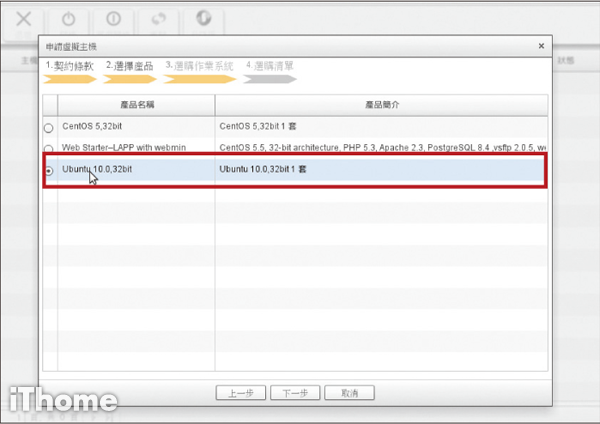
Step 7
選擇「Ubuntu 10.0,32bit」
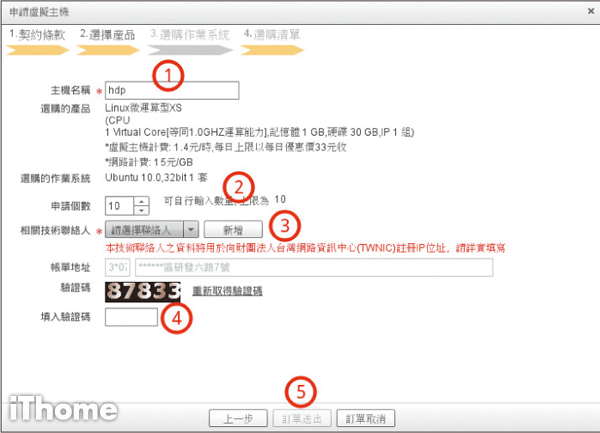
Step 8
用hdp命名,產生10臺虛擬機器
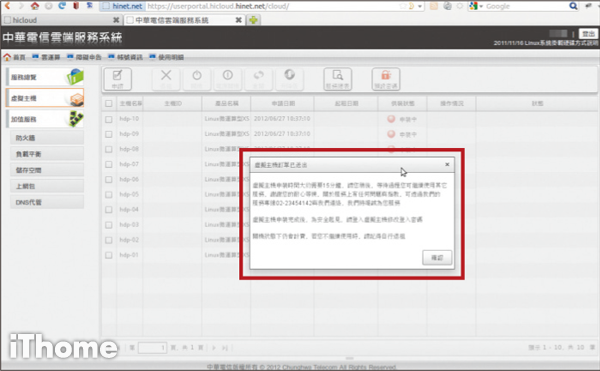
Step 9
等待申裝狀態變為「已申裝」
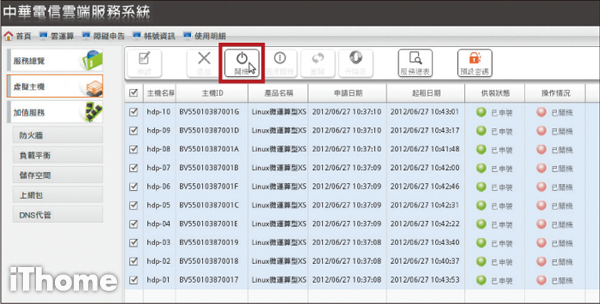
Step 10
確認供裝狀態變為「已申裝」點左上角「全選」,並選「開機」
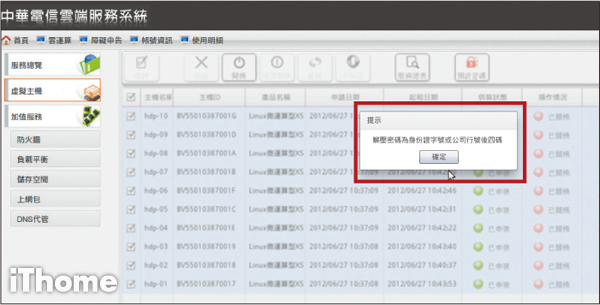
Step 11
點選右上角「預設密碼」,將password.zip儲存到桌面

Step 12
用預設密碼解壓縮password.zip,將CSV格式的密碼檔案匯入Excel,選擇「逗號」分隔。
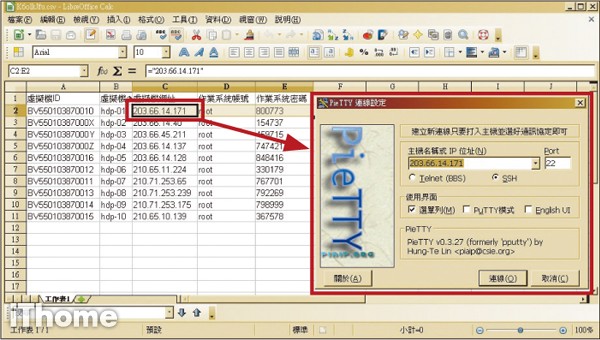
Step 13
從密碼表中挑選第一臺用PieTTY連線到該臺虛擬機器
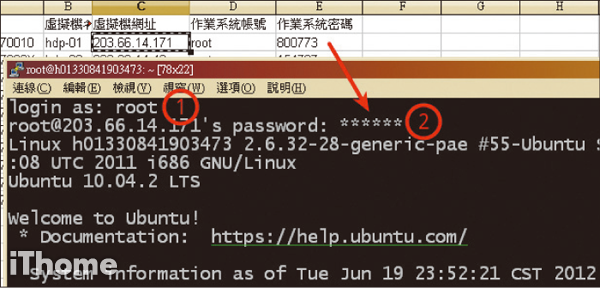
Step 14
預設使用root帳號登入,密碼根據你的密碼表輸入六碼預設密碼
做到這邊,我們已經把十臺虛擬機器開機。從hiCloud介面上確認每一臺虛擬機器都已經進入「已開機」的狀態,接著使用你慣用的SSH連線軟體,這裡我們使用的是PieTTY,可以自http://ntu.csie.org/~piaip/pietty/ 下載。由於hicloud-Hadoop自動安裝腳本是針對Linux環境撰寫的,因此我們直接挑選其中一臺來進行安裝。你也可以在自己的Linux環境上執行以下的步驟。在執行hicloud-Hadoop自動安裝腳本前,有一些前置作業:(1)產生SSH連線用的金鑰;(2)安裝Perl的Expect.pm函式庫,因為我們會使用Expect來幫忙你自動填入預設密碼,登入另外九臺虛擬機器,並進行Hadoop安裝作業。現在你在登入第一臺虛擬機器的PieTTY視窗內中輸入以下兩個指令:

接下來,讓我們下載hicloud-Hadoop自動安裝腳本,並且解壓縮安裝檔。然後在hicloud-Hadoop目錄底下建一個conf子目錄。

接著,使用記事本先編輯兩個檔案,一個叫master,一個叫slave。可用PieTTY或WinSCP上傳這兩個檔案到hicloud-Hadoop/conf 底下,或參考底下的作法在conf底下建立兩個設定檔。
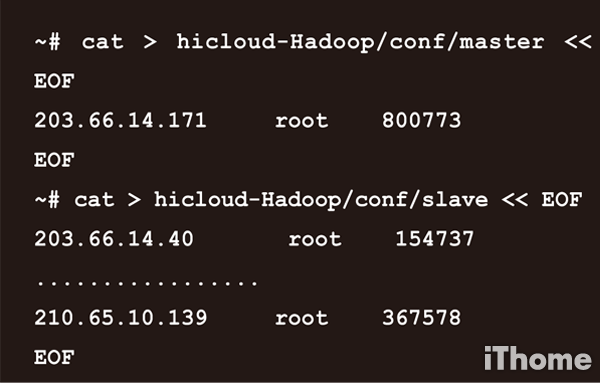
以上的IP、帳號、密碼三個欄位,你可以直接從CSV貼到記事本,加入中間的空白,在貼到命令列。最後切換到hicloud-Hadoop目錄,然後執行 install-ubuntu 自動安裝腳本。

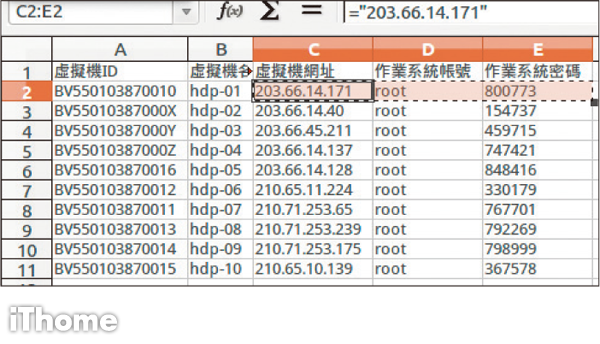
Step 15
從密碼表中挑選第一臺的IP、帳號、密碼貼到記事本,補上空格,然後轉貼到master

Step 16
從密碼表中挑選剩下的IP、帳號、密碼貼到記事本,補上空格,然後轉貼到slave
等自動安裝腳本執行完畢後,你會看到類似底下的訊息。此時,點選兩個網址,就會看到Hadoop的HDFS NameNode與MapReduce JobTracker網頁。
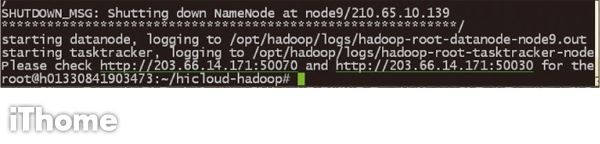
Step 17
安裝完畢的最後一行會顯示50070與50030的兩個網址
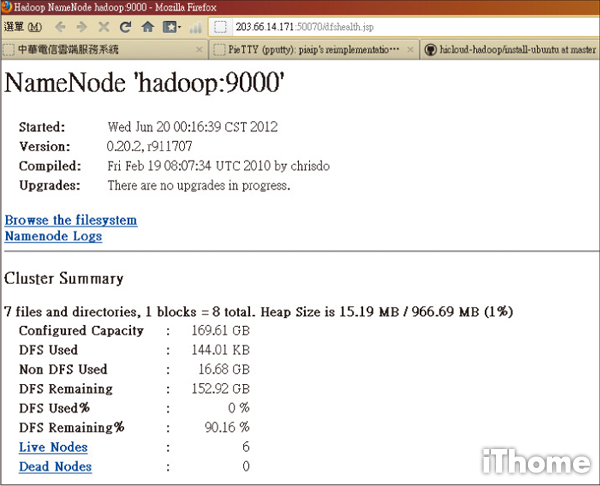
Step 18
50070的HDFS頁面

Step 19
50030的MapReduce頁面

Step 20
練習完畢後,務必退租,免得收到帳單會很痛!

花了28塊(10臺*2小時*1.4元)就可以練習Hadoop叢集部署
做到這邊,各位讀者應該可以繼續在hiCloud的這10臺虛擬機器上練習在Hadoop4Win的指令。不過這裡要提醒的一件很重要的事情:「相較於Amazon EC2有開機才計價,hiCloud是從申裝開始計費,退租才停止計費,就像你租用手機門號一樣,不管有沒有開機都會計費」。因此建議你如果口袋不夠深的話,練習完麻煩一臺一臺把虛擬機器退租吧!虛擬機器租金每小時14元,一節課程大約兩三個小時,整個練習費用跟買杯超商咖啡差不多,這就是雲端帶給各位的新學習環境。
倘若你手邊有兩臺以上的實體機器,或者多核心效能強大的伺服器,不妨安裝VirtualBox虛擬化軟體,在一臺電腦上建立兩至三臺Ubuntu 10.04的Linux環境,各位聰明的讀者可以透過上述的步驟來安裝你專屬的Hadoop叢集,就算是一個小型的私有雲了。
眼尖的讀者可能會發現hicloud-Hadoop的NameNode、MapReduce截圖只有看到六臺DataNode與TaskTracker,那是因為腳本程式還沒執行完畢就先截圖了。正常而言,你會看到九臺(因為第一臺不當DataNode與TaskTracker)。
目前hicloud-Hadoop 0.0.1版本是循序安裝,因此機器愈多,安裝時間愈長。未來將加入多執行緒的程式碼,讓安裝流程能同時進行。對hiCloud這種按時計費的公有雲而言,如何節省安裝時間變得很重要。未來hiCloud若能讓使用者建立自己專屬的虛擬機器範本,相信能有效降低各位讀者荷包的負擔。
其次,中華電信的計價模式還包含網路流量,因此如何減少網路傳輸也是採用公有雲服務應該要思考的第二個重點。目前的腳本每一臺虛擬機器都會重複下載Java與Hadoop安裝檔。若能把Hadoop安裝檔先存在同一個公有雲提供的「儲存服務」,讓資料來自於「內部網路」而非「網際網路」,不納入流量計費,那也是對用戶有利的計價模式。
最後,若能夠把要處理的事情變成自動化,計算完就關閉虛擬機器,以上這些考量就是在雲端時代程式設計師應該具備的「雲端精算師」精神,擁有節省成本的思考模式將是你未來在職場上的新競爭力!

《作者簡介》
王耀聰
國家高速網路與計算中心副研究員,也是國網中心軟體技術組副組長,從事雲端運算基礎架構的研發,包括Hadoop雲端運算平臺與Xen虛擬化叢集部署工具的開發,也是經營臺灣Hadoop使用者社群的重要推手。
相關報導請參考「Hadoop巨量運算活用術」
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05