處理器技術的進展已成為當代個人電腦與伺服器發展的重大關鍵,隨著x64架構、多核心處理器的普及,以及製程的持續改良,以伺服器平臺的選擇來說,不論從效能、省電、價格等觀點來採購時,都比過去有更多的選擇。
提升製程技術,選擇更多
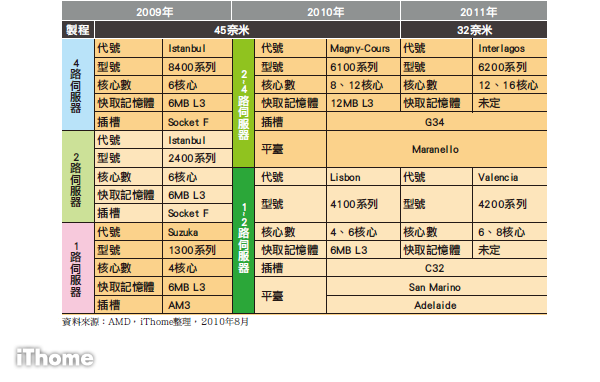
2009年時,AMD在單路、2路與4路伺服器市場上,發布了代號為的Suzuka與Istanbul Opteron處理器。其中,Suzuka是針對1路,而Istanbul則是針對2路與4路伺服器。
Istanbul 是從上一代的Shanghai改進而來,最主要差異在於從4核心增加為6核心;處理器型號從2路的2300改為2400,4路的8300改為8400。在 其他方面,它們都同樣採用45奈米製程,平均處理器功耗(ACP)同樣使用Socket F(1207腳位)插槽,L3快取記憶一樣是每個核心6MB,並且延續了處理器直接連結架構(Direct Connect Architecture)。
而針對單路伺服器,型號為1300的Suzuka處理器,與Istanbul同樣是45奈米製程、內建6MB的L3快取記憶體與75瓦ACP,不過核心數只有4核心,且使用Socket AM2+的處理器插槽。
而目前AMD最新的伺服器處理器,將原本Suzuka與Istanbul改為Lisbon的4100系列,以及Magny-Cours的6100系列處理器。
Lisbon 是針對1路與2路伺服器所推出的處理器,與前一代的Suzuka及Istanbul一樣,都是45奈米製程,不過核心數可分為4核心與6核心兩種,每核心 內建6MB L3快取記憶體,支援雙通道的UDIMM與RDIMM DDR3記憶體,Socket改為新的C32處理器插槽。而Magny-Cours則是內建8核或12核心,針對2路與4路伺服器的處理器,除了擁有大量 的核心數目之外,這系列處理器還支援目前最多的記憶體4通道,並改用G34處理器插槽。
在2011年,AMD將推出下一代新處理器,代號分 別是12核與16核的Interlagos,以及6核與8核心的Valencia。這兩個系列都採用AMD新的Bulldozer架構,透過執行緒的增 加,強化處理器運算速度,且L3快取記憶體增加為12MB,且Interlagos將延續使用與Magny-Cours相同的主機板平 臺:Maranello;而Valencia則與Lisbon同樣採用San Marino的主機板平臺。
從Istanbul到Magny-Cours的變化,我們可以看出處理器的核心數目增加之外,製程技術也不斷加強,從45奈米提升到32奈米,而且在下一代的處理器中,還採用新的Bulldozer架構,在AMD的處理器中,首次加入了多執行緒強化處理器運算速度。
而Intel在今年初發布了採用32奈米製程,名為Westmere系列的處理器,同樣承襲Nehalem的主要架構。
由 於製程技術的提升,讓相同大小的晶片內可置入更多的處理器核心,因此Westmere系列中,就有6核心的處理器,例如Xeon W3680、E5650與X5680等。而且這系列處理器內建的快取記憶體,比前一代Nehalem內建的8MB L3還多,增加到12MB的L3快取記憶體,並且全面支援DDR3記憶體,最高可支援的記憶體總數,則是比前一代多出一倍,高達288GB記憶體。
受到製程技術提升的影響,我們還可看到另一個關鍵的改進,那就是耗電量。我們以Intel 45奈米製程的5500系列,與32奈米製程的5600系列的規格相比,就可看出新一代的製程技術帶來的節電效果。
去 年製作伺服器採購特輯時,所測試的Xeon E5520處理器,與今年新一代的E5620相比,雖然兩個處理器的熱設計功耗(TDP)都是80瓦,且核心與執行緒數量如出一轍,但是E5620的時脈 比E5520高出一些,而且如前面所說加強的技術,以及新增的功能,都讓相同熱功耗設計的處理器,呈現完全不同的效能。因此新的製程技術,讓處理器在相同 的耗電量下,可達到更高的效能。
不過AMD今年仍使用45奈米製程,預計明年的Interlagos與Valencia將會使用32奈米製程。
以多核心及執行緒提升運算效能
觀 察近來AMD處理器的發展,我們可以發現AMD與Intel的處理器,多工的處理方式不盡相同。例如,Intel發展的多執行緒架構(Hyper- Threading),在一顆處理器內擁有4核、或是最新的Xeon 5600系列的6核心,其中每個核心都有2個執行緒,也就是每顆處理器都有8個或12個執行緒;而AMD的Opteron則是朝實體核心數量發展,例如目 前研發代號為Magny-Cours的6100系列處理器,就內建實體6核心,而針對1路伺服器的4100系列處理器,則內建有4個實體核心。而且,在下 一代的Valencia與Magny-Cours,則讓核心數增加到6至8核心,以及8至12核心。
AMD不斷的在處理器內增加更多的核心,原因是它們認為實體核心的運算效能,會比使用虛擬的執行緒的運算效能更佳。
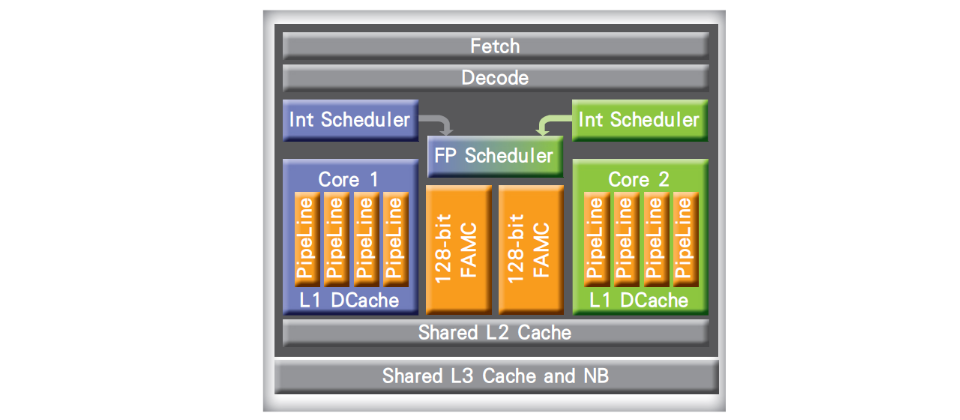
不過他們在2011年即將發表的Bulldozer架構處理器,在增加核心數的同時,還結合了2個實體核心,讓平行運算的過程中,可使用兩個實體核心共同運算,而且它們的L2與L3快取記憶體也是共享,讓平行運算架構可用兩個核心運算。
依照Intel的標準來看,包含2個核心的Bulldozer只能算是擁有雙執行緒的單核心處理器,例如內建16核心的Interlagos處理器,對Intel來說,就是8核心、16執行緒的處理器。
每 個Bulldozer除了擁有2個核心所組成,可共同運算的雙執行緒模組之外,還因為每個核心都擁有由4條管線(Pipeline)所組成的整數運算單 元,因此Bulldozer中,都有2個由4條管線所組成的整數運算單元,另外還有2個128位元,可合併為256位元的浮點運算單元。再加上共用的L2 快取記憶體,因此Bulldozer之中的每個整數運算單元會被當作一個物理核心,就如同Intel的超執行緒一般。
在Intel方面,雖然使用了超執行緒的技術,但是在實體核心數目的發展也沒有停下腳步,在去年推出新一代的Nehalem架構處理器,採用45奈米製程,並且依照單路、2路與4路伺服器等不同市場,分別推出3500、5500與7500系列處理器。
而在今年初,Intel又進一步推出新一代的3600與5600系列,採用32奈米的製程技術,將原本5500系列內建的核心數目,增加到6核心,執行緒也增加為24執行緒。
並 且延續或增進上一代Nehalem系列中的多種規格與技術,例如5500系列支援記憶體總數為144GB,而Westmere的5600系列則增加一倍, 達到288GB;另外還加大了L3快取記憶體,從8MB提升到12MB。而之前每個處理器中內建的Intel超執行緒(Hyper-Threading) 與Turbo Boost超頻技術等,也是一樣都不少。
超執行緒技術,只要應用程式有支援,就可讓單一處理器核心使用類似虛擬化的方式,讓處理器同時執行多個平行運算工作。
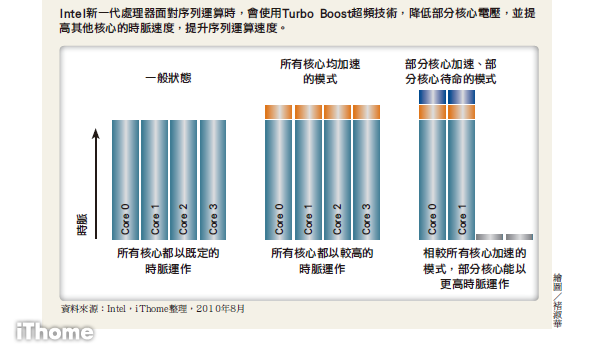
另 一個超頻技術Turbo Boost與超執行緒的平行運算不一樣的地方,在於Turbo Boost是針對無法同時運算的序列運算。它的加速運算方法,是降低4核心處理器之中的兩個核心時脈,也就是降低它們的電壓,將另外兩個核心電壓與時脈加 高,藉由時脈速度的提高,加速序列運算的速度。而且在增加時脈的時候,Intel的處理器還會主動偵測目前電壓與時脈速度,並且評估是否可以讓時脈速度再 往上提升,或是應減慢時脈以保護處理器。
藉由這種自動切換運算需求的超執行緒與Turbo Boost技術,Intel的目的就是讓處理器,變的更加聰明,會因應需求而切換功能。
直接溝通架構(Direct Connect Architecture)
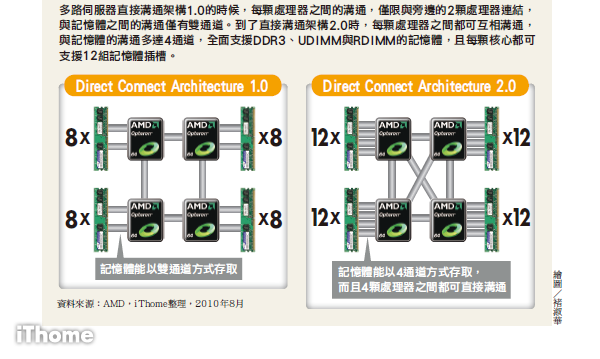
在 AMD的Istanbul架構中,多路伺服器之間的連結,是採用AMD的直接溝通架構1.0,可讓處理器之間直接溝通,且可以降低記憶體與處理器的I/O 延遲,並加速這些元件之間的傳輸速度。不過以4路處理器來看,採用1.0的直接溝通架構時,每顆處理器都只能與相連的另外2個處理器做溝通。因此,今年 AMD更新的直接溝通架構2.0,讓所有處理器之間都可做溝通,也就是說,4路伺服器內部的每顆處理器,都可與另外3個處理器直接做溝通。而且,1.0的 直接溝通架構最多僅能支援6核心處理器,而2.0則可支援到16核心。
而且,新一代的直接溝通架構還加強了處理器之間的傳輸速度,從原本 的,4.8GT/s增進到6.4GT/s;在記憶體方面,每顆處理器可支援的記憶體插槽數量,從1.0的8 DIMM增加到12 DIMM,並且首度支援了DDR3記憶體,同時支援UDIMM與RDIMM,在記憶體搭配的選擇上更豐富。
在多路伺服器的架構上,Intel的7500系列處理器擴展性也有改善,從可以2顆處理器串接,共用32組記憶體插槽,組成一個2路模組,並且可持續擴展處理器數量到最多256顆7500系列處理器。這樣的擴充模式可透過多顆處理器來分擔運算負荷,加速整體運算效能。
新增指令集
指 令集,就是將原本需要透過多行軟體指令解碼的動作,改由硬體解碼。而AMD的Interlagos所採用的Bulldozer架構,將會相容於目前 Intel處理器已經支援的指令集,例如SSE4.1、SSE4.2、AES與CLMUL等,而且也把SSE5的指令集內建在其中,不過他們將這個指令集 拆為XOP、FMA4與CVT16等3個指令集,並且相容於Intel的AVX指令集。
在Intel方面,Xeon系列全部處理器都支援 MMX、SSE、SSE2等指令集,以及Intel進階加密標準新指令(AES-NI),這個指令集之中包含7種新的指令,加速資料的加密與解密,讓資料 在存入時就以加密的形式儲存,確保資料的安全性。另外,在下一代的Sandy Bridge系列中,還會新增針對密集浮點運算所制定的指令集:先進向量擴充指令集(AVX)。
由以上這些功能,我們可以看出,結合超執行 緒與Turbo Boost超頻的技術,讓Intel處理器在面對不同的運算資料時,都可切換適當的模式,加速這些序列運算,或是平行運算等不同運算模式。另外,在加上越 來越多的指令集內建在其中,讓許多常見的運算功能都能夠透過指令集運算,讓處理器核心不用花費太多時間在瑣碎的運算中。
越來越聰明,與計算能力越來越強的處理器
將來的處理器,勢必在效能上會越來越強,問題在於,AMD與Intel要如何達到這樣的目標?
目 前,我們可以看出AMD持續的朝實體核心的數目發展,因為他們認為實體核心的運算效能,比虛擬化的執行緒更佳,因此在處理器的發展上,持續增加實體核心數 量,並且加強多路伺服器處理器之間的溝通,讓處理器在各自擁有多核心的同時,還可共享資源,讓多處理器架構的系統在運作效能上,就像是一個擁有數十個核心 的處理器一般。
另外,在個人端的處理器,他們也開始結合繪圖晶片驚人的平行運算效能,將平行運算的內容傳送給繪圖晶片(GPU),並透過可 程式控制GPU內部的多個平行運算核心及記憶體,用來處理非圖形的平行運算,所組成的新組態:通用型GPU(General Purpose GPU,GPGPU),讓原本針對圖形運算的繪圖晶片開始分擔處理器的運算,甚至更進一步的把繪圖晶片整合在處理器內部,變成Accelerated Processing Unit(APU),也就是說,將來的APU內部,將包含一個運算核心、一個可程式化向量運算引擎、記憶體控制器、I/O控制器、視訊解碼器以及匯流排介 面等多種功能與控制器。
雖然,目前這樣的處理器僅出現在個人端,不過我們可以預見伺服器的處理器也將會整合這樣的設計,針對不同的運算內容,使用針對純量的運算核心,或是使用向量的繪圖核心作不同的運算,藉此提高整體的運算效能。
而Intel方面,將持續發展超執行緒與Turbo Boost,兩種針對平行運算與序列運算的技術。
雖然兩家處理器廠商的目的都是相同的,那就是提供更高的運算速度與效能,但是Intel發展的方向與AMD卻不大一樣,因為他們的方式,是讓處理器能自動選擇與切換運算模式。
以 當前Intel的Xeon處理器而言,內建了針對序列運算而提升時脈速度的Turbo Boost,以及平行運算的超執行緒技術,讓Intel的處理器在面對各種資料類型時,都能切換運算模式,加速各種運算的速度,讓系統的效能提升。另外, 日益增進的製程技術加上省電技術,讓處理器可減少耗電量,或是在相同耗電量提供更佳的運算效能。
就像今年Intel推出的32奈米Xeon Westmere 5600系列處理器,除了部分產品核心增加為6核心之外,其他同系列處理器雖然核心與執行緒的數量,與前一代的Xeon 5500系列一樣,維持在4核心8執行緒,但是時脈速度略微提高,讓處理器在相同的耗電量之下,擁有更高的運算速度。
AMD Opteron處理器發展藍圖

Intel Xeon處理器發展藍圖
Intel Turbo Boost技術的工作原理
AMD Direct Connect Architecture架構的比較
AMD Bulldozer的處理器核心架構

熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09