
全球最大AI模型硬體設施鍊成術
為了打造頂級大語言模型Llama 3.1,Meta建置超過2.4萬個GPU與3千臺GPU伺服器的AI運算基礎設施,並克服一系列挑戰,足可作為未來超大規模AI設施營運經驗的參考範本
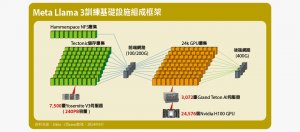
【2.4萬個GPU結合6千個CPU,打造當前全球最高規格AI運算環境】探索Meta Llama 3模型訓練的硬體基礎架構全貌
基於開放策略,Meta釋出當前炙手可熱的Llama 3大語言模型,也公開訓練這套模型的硬體基礎架構細節,使外界有機會瞭解這種超大規模AI運算設施的真實設置場景
文 /|2024-08-16

【GPU是大型AI運算架構中最脆弱環節,自動化偵測與故障排除技術是確保維運關鍵】超大規模AI運算設施的維運挑戰
足夠的系統規模,只是執行Llama 3這類應用的必要門檻,而不能保證運算工作能順利進行,並獲得期望的成果,想要讓這類超大規模AI基礎設施充分發揮效益,還需要仔細的調校,並維持足夠的穩定性
文 /|2024-08-16
按讚加入iThome粉絲團追蹤