近日Google雲端服務加強許多深度學習、機器學習應用相關的功能,先是擴充虛擬主機硬體規格,推出主打大記憶體容量的ultramem規格VM,讓使用者能進行高效能運算,同時,公有雲平台的先占式GPU、TPU也在近日陸續上線,企業可以花費比隨需服務更便宜的價格,使用GPU、TPU資源。而這一次Google則是宣布,公有雲GPU服務現在正式與Kubernetes引擎(GKE)整合。
目前GCP旗下的GPU硬體共有3種選擇,從價格較入門等級的K80,至中階P100及高階V100,讓使用者可以按需選擇。想要使用新功能的使用者,現在Google也有提供300美元免費試用額度。
這次發布後,企業在GKE環境中運作的容器應用程式,便可以搭配GPU服務,執行CUDA工作負載,「可以借力GPU大量處理能力,同時免去管理VM的工作」,Google表示,此服務也可以搭配日前正式上線的先占式GPU服務使用,降低企業進行機器學習運算的成本。現在此功能,也已經和Google雲端監控服務Stackdriver整合,使用者可以觀察,現在GPU資源的存取頻率、GPU資源的可用量,或者GPU的配置狀況。
此外,在Kubernetes環境中使用GPU服務的企業,也可以一併使用Google Kubernetes引擎的一些現有功能。像是搭配Node資源池功能,讓現有Kubernetes叢集上的應用程式可以存取GPU資源。當企業應用規模彈性改變時,則可以選用叢集擴充功能,系統可以自動擴充內建GPU的節點,當基礎架構中沒有任何Pod需要存取GPU資源時,系統就會自動關閉這些擴充節點,GKE也會確保節點上的Pod,都是需要存取GPU資源的Pod,避免沒有GPU需求的Pod被部署至這些節點運作。而系統管理員可以利用資源配額功能,當多個團隊共用大規模叢集時,限制各使用者能存取的GPU資源。
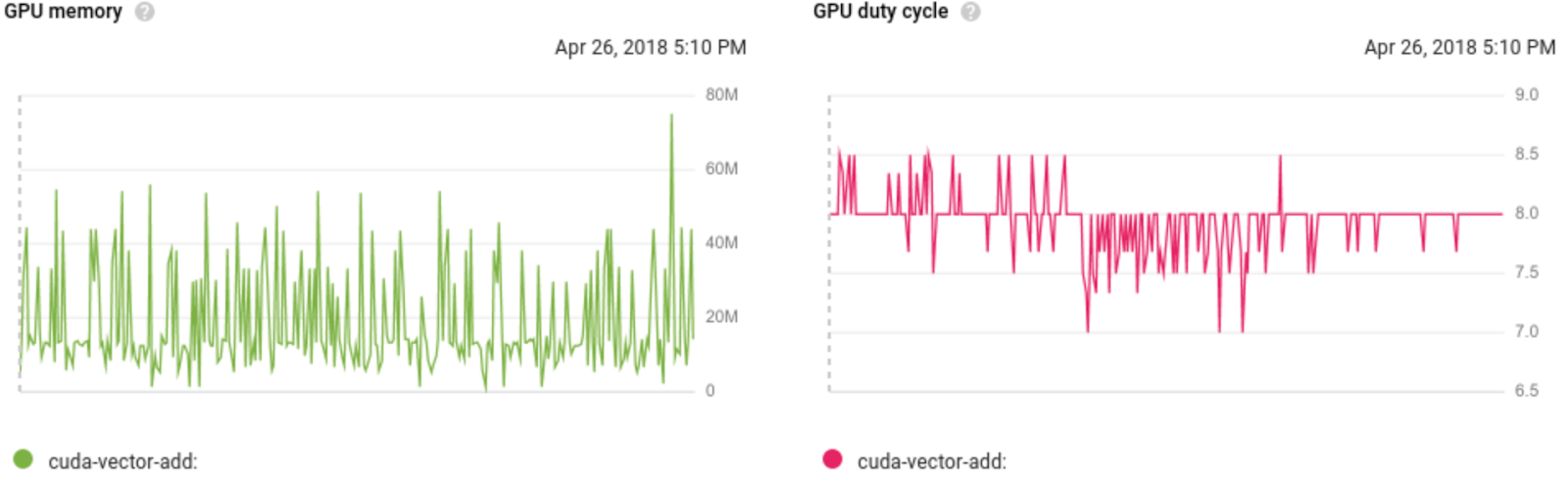
現在此功能,也已經和Google雲端監控服務Stackdriver整合,使用者可以觀察,現在GPU資源的存取頻率、GPU資源的可用量,或者GPU的配置狀況。圖片來源:Google
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09