
機器學習基準測試套件MLPerf於推出7個月後,根據第一輪由Nvidia、谷歌和英特爾提交的資料,發佈了第一次的結果。MLPerf的結果測量了主要機器學習硬體平臺的速度,包括Google的TPU、英特爾CPU和Nvidia GPU,同時結果也提供了諸如TensorFlow、PyTorch和MXNet等機器學習軟體框架速度的了解。
MLPerf為一個新興的基準測試套件,提供了衡量雲端供應商和內部硬體平臺的效能的方法,其訓練幾準由資料集和品質目標定義,而且同時還為每一個基準使用的特定模型提供了參照實作,雖然MLPerf v0.5包含7個基準測試,但實際上只有5個類別,分別是圖像分類、物體偵測、翻譯、推薦和增強學習。

測量基準是量測將模型訓練到達目標品質所需要的時間,然後將MLPerf時間結果標準化,在單個Nvidia Pascal P100 GPU上執行的未最佳化的參照實作,官方提到,未來的MLPerf基準測試也將包括推理。 MLPerf量測基準分為兩部分封閉與開放,封閉的比較主要測試機器學習硬體和框架,需要使用相同的模型以及Optimizer,而開放則可以使用任意的模型。在第一輪的比較上,各家都選擇先在封閉基準測試較量。
Nvidia在部落格發布了自家測試結果,包括單節點測試以及規模測試,並且提到,他們目前先專注在封閉的基準測量進行比較,因為這樣才是進行有意義的機器學習訓練系統比較,開放量測目的是用於鼓勵網路模型架構和其他演算法方面的創新。

.png)
Nvidia提交了7項基準測試中的6項結果,Nvidia提到,之所以選擇不提交增強學習測試,是因為測試基準是基於策略遊戲Go的實作,而該遊戲最初是在使用Tesla P100 GPU的伺服器上開發,在目前的形式,其含有重要的CPU元件,因此規模的擴展受到了限制。最終Nvidia放棄了增強學習基準測試。
Google同樣也在部落格發布了其在MLPerf上的結果,並宣稱其平臺最容易進行機器學習訓練的擴展,並且以晶片相比,其TPU擁有19%的效能優勢。Google提到,在多個MLPerf測試的競爭效能中,證明TPU(Tensor Processing Units)和TPU Pods是適合大規模訓練機器學習模型的系統。
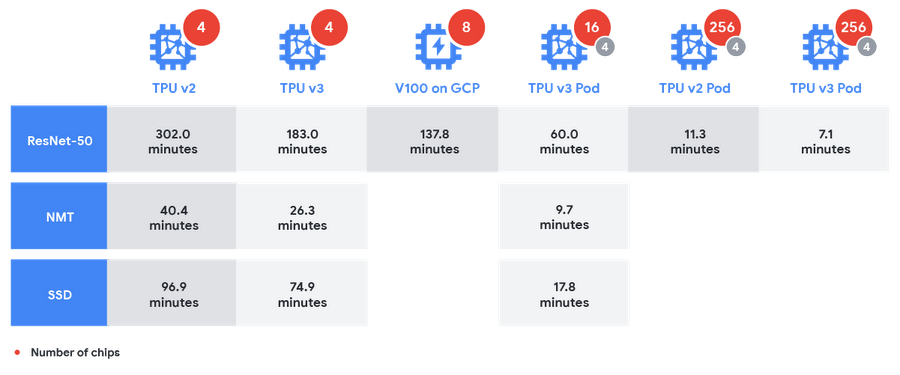
Google比較了自家1/64th TPU v3 Pod與Nvidia的DGX-2機器的絕對訓練時間,其運行標準的圖像分類網路ResNet-50,TPU v3 Pod共花了60分鐘,而DGX-2則花了73.9分鐘。DGX-2包含16個V100 GPU,而1/64th TPU v3 Pod擁有用於訓練的16 TPU v3晶片與4個用於評估的TPU v2晶片。

熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02