
Hugging Face
AI資源平臺Hugging Face上周公布SmolVLM二款新多模態模型,SmolVLM-256M及SmolVLM-500M,前者號稱是全球最小的多模態及影片語言模型(video language model,VLM)。
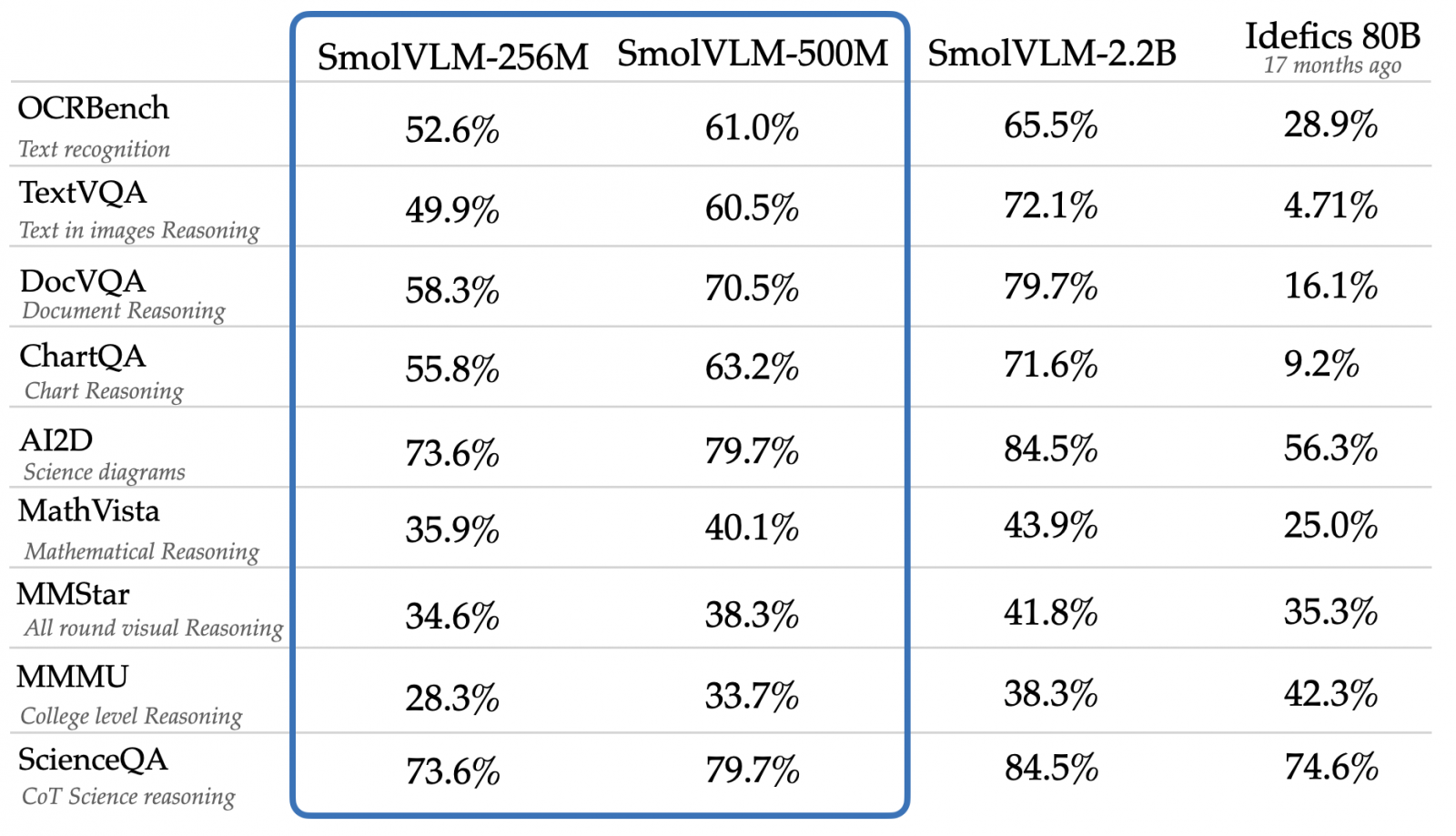
Hugging Face團隊去年訓練2款80B參數的VLM,再縮成8B模型,然後縮小成SmolVLM 2B模型。然後他們決定再進一步縮小,著重效率、混合資料以及在不同需求間取得折衷。成果是強大但體積極小的多模態模型,包括SmolVLM 256M與SmolVLM 500M,各有基礎模型和指令微調模型。這些模型可以直接載入到transformer MLX和ONNX上。
作為SmolVLM家族的新成員,256M及500M都是使用SigLIP為圖片編碼器,以SmolLM2為文字編碼器。他們在多項標竿測試超越一年半前才釋出的Idefics 80B模型。其中256M是最小型的VLM及多模態模型,它能接受任何序列的圖片和文字,生成文字輸出。SmolVLM能勝任多種多模態任務,包括生成圖片描述或短影片字幕、PDF或掃瞄文件問答,以及回答關於圖表的問題。輕巧架構的架構讓它適合行動裝置上應用,同時維持強大效能。它以不到1GB的GPU RAM就能在單一圖片上執行推論。
圖片來源/Hugging Face
需要更高效能的組織可以選擇SmolVLM-500M模型。500M在文件理解DocVQA和多模態推理標竿測試MMMU的表現不輸之前的2B。這模型對提示回應能力更佳,適用部署於組織營運環境。500M模型也是相當輕巧高效的模型,在單一圖片上推論僅需1.23GB的GPU RAM。二款模型微調後表現更佳。
兩款模型都是以Apache 2.0授權開源。研究團隊提供了transformer和WebGU二種示範。所有模型和示範都公布於此。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10