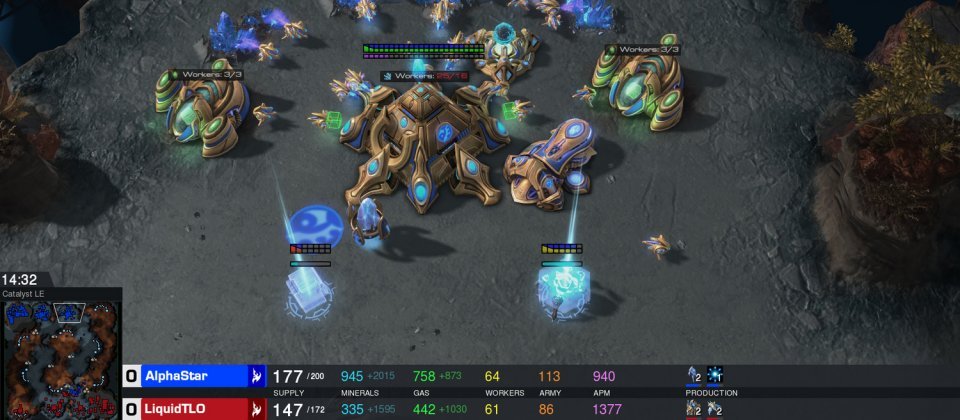
Deepmind的人工智慧AlphaStar,在2018年12月19日一系列的星海爭霸 2(StarCraft II)測試賽中,以5比0打贏世界頂尖職業玩家,Deepmind現釋出了訓練人工智慧的細節。
Deepmind提到,遊戲一直是測試和評估人工智慧效能的重要方法,而即便人工智慧遊玩Atari、馬力歐甚至是Dota 2等遊戲已經有很大的進展,人工智慧在操作星海爭霸 2上,仍然難以克服其複雜度。暴雪娛樂公司的星海爭霸 2,被認為是極具挑戰的即時戰略遊戲之一,而且過去即便是讓電腦作弊,在遊戲規則上動手腳,賦予電腦特殊能力,都難以與專業玩家匹敵。
不過現在,Deepmind的人工智慧AlphaStar,已經能以深度神經網路完整遊玩星海爭霸 2,而且還能碾壓世界排名前十的職業玩家。該神經網路透過監督式學習和增強學習,直接以原始遊戲資料進行訓練。星海爭霸 2有許多種玩法,但在電子競技中,最常見的形式是進行5場1對1的錦標賽,玩家可以選擇各有特色的蟲族、神族或人類種族。
AlphaStar以神族與頂尖人類玩家交手,第一次是與德國頂尖玩家Dario Wünsch(代號TLO)進行對戰,AlphaStar以5比0贏得了比賽,Dario Wünsch對人工智慧的強度感到驚訝,並表示AlphaStar使用了過去他沒想過的策略。第二次則是與世界排名前十強的職業神族玩家Grzegorz Komincz(代號MaNa)進行對戰,依然以5比0取得完勝,Grzegorz Komincz表示,AlphaStar在每場遊戲都採用不同的策略,並且以非常人性化的方式進行遊戲。
Deepmind提到,人工智慧要贏得遊戲,除了必須謹慎地平衡經濟發展,也需要微觀的對各單位進行細微控制,要在短期與長期目標之間取得平衡以適應意外狀況。星海爭霸中沒有單一最佳策略,人工智慧需要在訓練過程,不斷探索以及拓展戰略知識。
而且不像是圍棋或是西洋棋公開所有遊戲資訊,在星海爭霸 2的關鍵玩家資訊是隱藏的,必須透過偵查探索發現。另一個困難則是,人工智慧需要有長期規畫的能力,並非所有因果關係都是即時發生的,整個遊戲歷程可能長達一個小時才會結束,而這意味著早期採取的行動,或許有很長的一段時間無法獲得回報。
在星海爭霸 2中,人工智慧沒有太多的思考時間,不像傳統棋盤遊戲是輪流進行,人工智慧與玩家都必須隨著遊戲時間推移,不斷地做出動作。人工智慧還需要在大型的動作空間中做出決策,需要即時細微地控制數百個不同的單位和建築物。
由於以上這些困難,星海爭霸成為人工智慧的大挑戰,Deepmind在2016年和2017年跟暴雪娛樂公司合作,釋出了PySC2工具集,其包括至今最大的匿名遊戲重播(Replay)集,Deepmind利用這些基礎,並搭配先進的工程技術和演算法開發出AlphaStar。
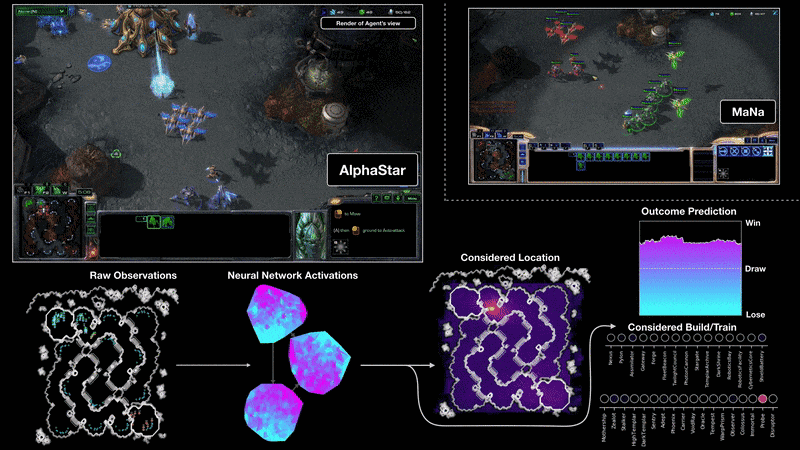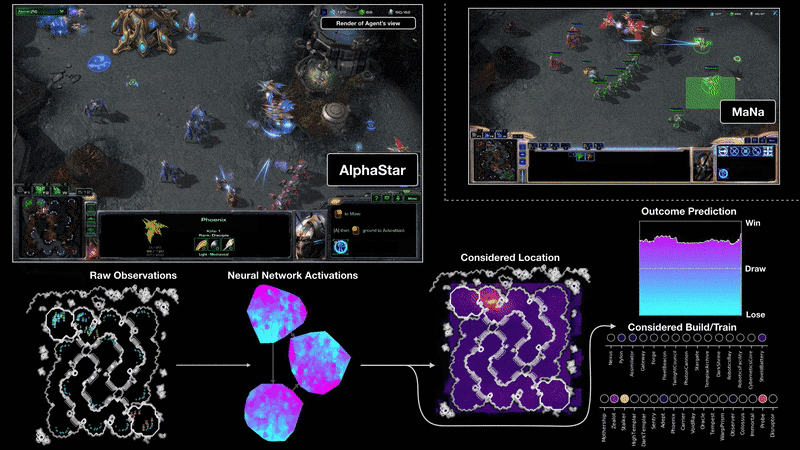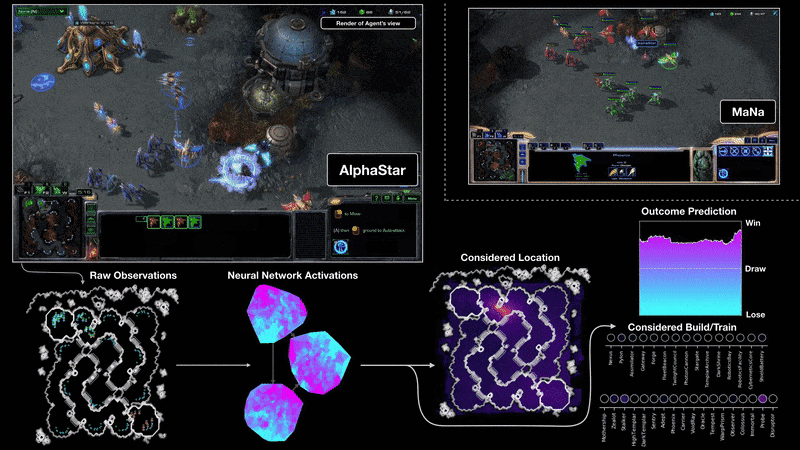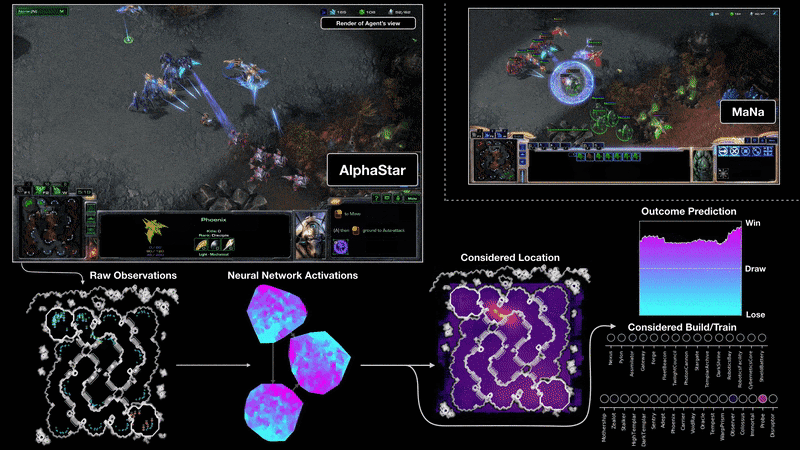
AlphaStar的行為由深度神經網路生成,該神經網路接受原始遊戲介面的輸入資料,並輸出一系列遊戲內指令。AlphaStar還使用了一種先進的多代理學習演算法,這個神經網路最初是由暴雪釋出,能讓AlphaStar模擬星海爭霸天梯排位系統上的玩家對戰,學習使用宏觀與微觀策略。
AlphaStar使用這個初始代理人在95%的比賽中,擊敗了遊戲內建的菁英級人工智慧,相當於天梯中黃金等級的人類玩家。而這些被應用在多代理人增強學習的過程中,Deepmind創建了一系列連續的戰隊,戰隊互相對戰,類似於人類玩家在天梯上對戰的情況。這種新形式的訓練方法,採用了基於人數的增強學習概念,創造不斷探索玩法的巨大戰略空間。
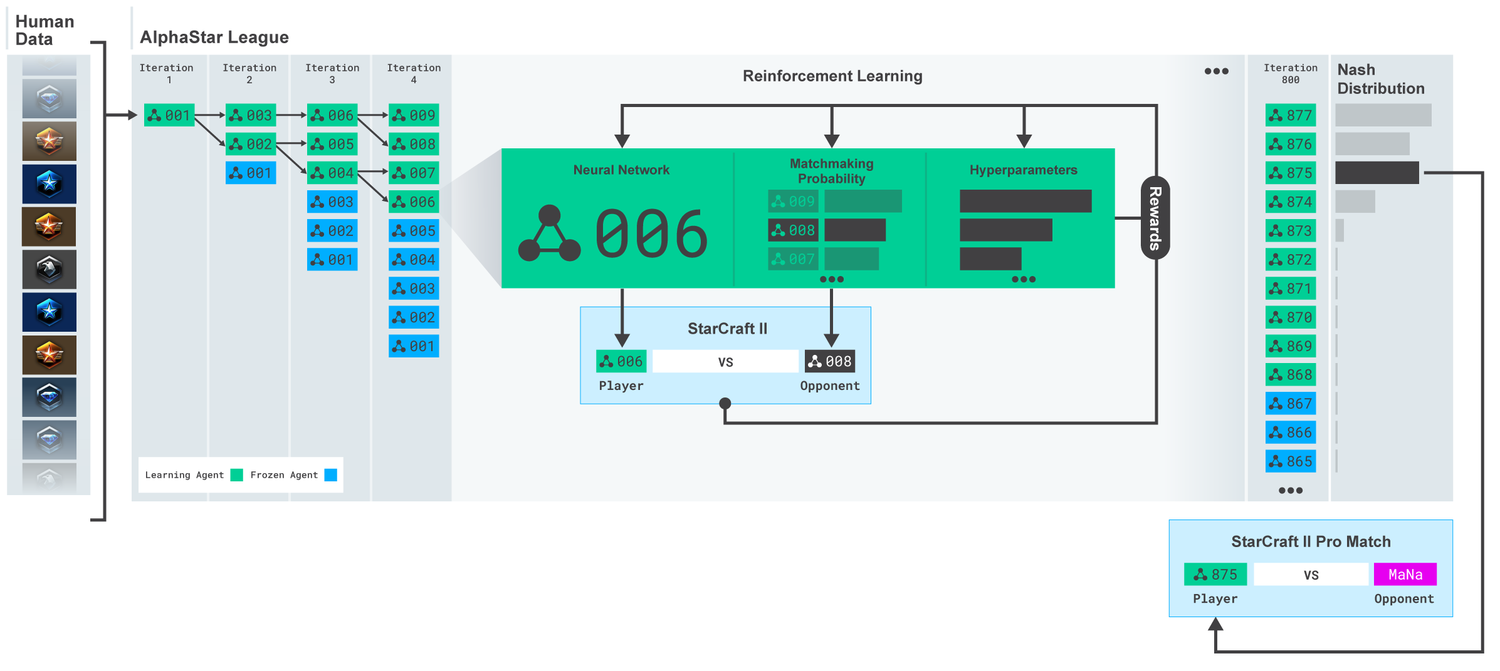
Deepmind提到,隨著戰隊的進步,能夠發展出擊敗早期策略的反制策略,甚至是全新戰術以及微觀管理計畫,像是一開始人工智慧喜愛使用神族的光砲或暗黑聖堂武士進行快攻,但這種充滿風險的策略在訓練過程被放棄,取而代之的是優先擴大基地,生產更多工人強化經濟實力,或是犧牲兩個先知單位,破壞對手的工人以壓制其經濟發展。這個策略發展的過程,跟玩家發現新策略的方式相似。
AlphaStar在手速上並沒有作弊,星海爭霸職業玩家平均每分鐘動作(APM)可達數百個,現有機器人的APM約在數千到數萬間,但是AlphaStar的平均APM約為280,明顯的低於職業玩家,Deepmind表示,AlphaStar動作數更低表示每個動作都更加準確,平均觀察並執行動作的延遲約在350毫秒。
Deepmind使用Google的TPU v3訓練AlphaStar,並建立了一個高度擴展的分散式訓練系統,支援執行數千個星海爭霸執行實體以訓練代理人,AlphaStar戰隊執行14天,每個代理使用16個TPU,訓練期間每個代理都經歷了長達200年的星海爭霸遊戲時間,最終的AlphaStar代理包含最有效的策略組合,可以在電腦以單個GPU執行。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-09

2026-02-06