
Google最新的語音辨識技術,能直接在裝置上放置機器學習模型,讓語音轉文字辨識功能離線作業,以解決網路限制造成的服務延遲,而且該語音辨識模型還能依照使用者語音,逐字輸入字元,就像是用鍵盤輸入文字的情況一樣。
從2014年開始,語音轉錄文字多使用序列到序列的方法,研究人員開始訓練單一神經網路,將輸入的音訊波形,直接映射到輸出的句子,這種序列到序列的方法,是將給定一系列音訊特徵,生成一系列單詞或是拼音系統中最小單位字位(Grapheme)。雖然這種模型大幅提升準確性,但是系統必須分析完整個序列後,才能一併輸出結果,因此系統無法邊聽邊輸出文字,而Google認為這是即時語音轉錄的必要功能。
Google新的語音辨識技術,採用RNN換能器(Recurrent Neural Network Transducers,RNN-T)訓練的模型,這與之前序列對序列的生成模型不同,RNN-T可以連續處理輸入的樣本,並且串流輸出字符,是一個非常適合用於聽寫的技術。在Google的實作中,模型輸出的字符為子母表的字元,RNN-T辨識器會逐個輸出字元,並在適當的地方加上空格。Google表示,要有效地訓練這樣的模型非常困難,但是他們現在可以讓單詞錯誤率低於5%。
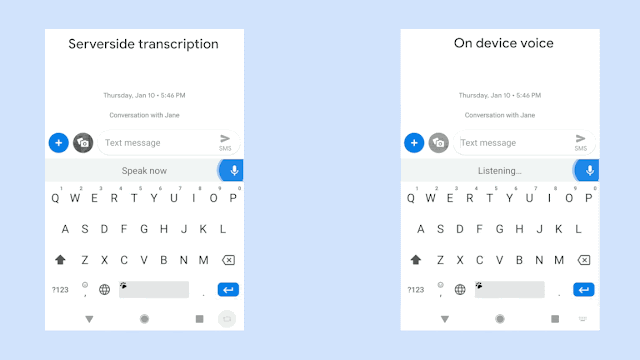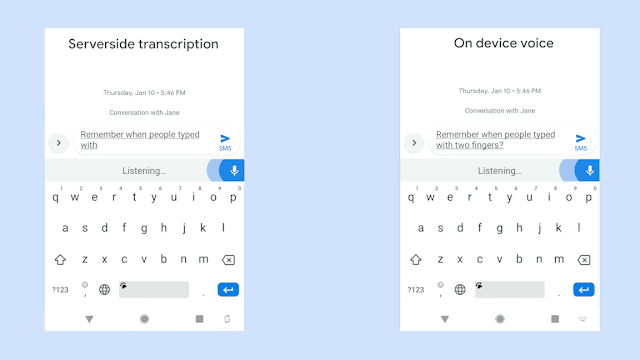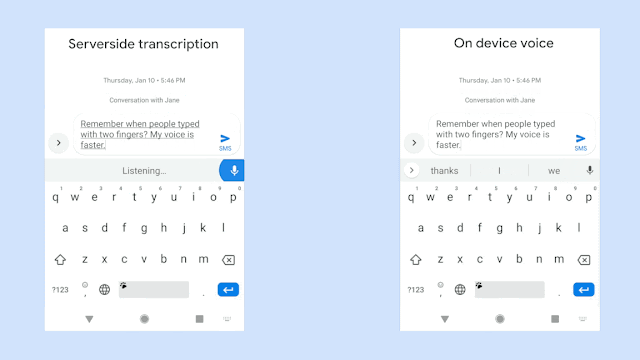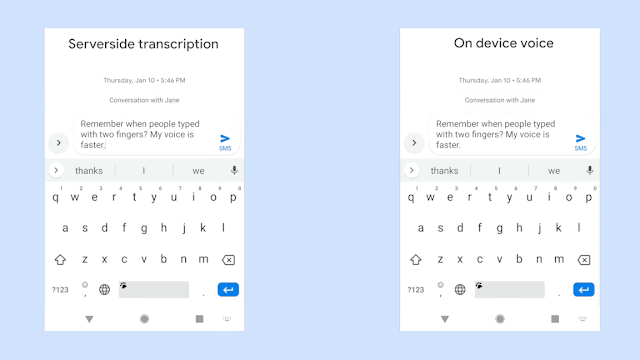
而且為了提高語音辨識的用處,Google在裝置放上新模型,直接在裝置上進行語音辨識分析,以避免網路的延遲和不可靠性。傳統語音辨識服務的效能,部分取決於使用者裝置的網路連線狀況,語音辨識服務必須要將使用者的語音或是從中萃取的資料,從手機端傳輸到伺服器進行分析,再將得到的結果送回手機。
Google解釋,在傳統的語音辨識引擎中,聲學(Acoustic)、發音以及語言模型構成了一個巨大的搜尋圖,當語音辨識器接受到音訊波形,便會在搜尋圖中找出最相似路徑,並讀出該路徑上的字元序列。傳統的搜尋圖容量非常大,儘管應用了複雜的編碼器,生產用模型大小依然接近2GB,而這樣的大小無法放在行動裝置上,因此必須要依賴連線,靠伺服器分析後回傳結果。
不過,現在Google的端到端方法不需要在大型的搜尋圖上搜尋,Google訓練的RNN-T模型只有450MB,就能提供與傳統伺服器模型相同的精準度,但是即便是450MB,對行動裝置來說仍然太過龐大,Google在2016年開發了模型參數量化以及混合核心技術,再加上TensorFlow Lite函式庫中的模型最佳化工具,大幅縮減模型容量。
模型參數化擁有比起訓練的浮點數模型高4倍的壓縮率,執行速度快4倍,Google最終壓縮的模型只有80MB,因此可以放在手機上,提供離線語音辨識服務。目前Gboard語音辨識器僅能在Pixel手機上,使用美國英文。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10