
臉書首先利用Pose2Pose類神經網路,來建立人物動作姿勢,來匹配搖桿的訊號,做出反應;再用另一套類神經網路Pose2Frame描繪出人物的外觀,結合新場景和人物動作畫面,產生出新影片。
重點新聞(0419~0425)
臉書 Vid2Game 影片生成
臉書發表影片生成AI,可擷取真實影片中人物來設計遊戲
臉書AI研究院日前發表一套影片生成AI,可從真實影片中擷取人物,再根據搖桿訊號來產生相應的人物動作姿勢,最後結合新場景,產生出新的短片。
進一步來說,臉書AI研究院先從影片中擷取出人物,為了控制人物動作,研究員先用自家設計的Pose2Pose類神經網路,以自動回歸機制(Autoregression)建立人物動作姿勢,來匹配搖桿的訊號,做出反應。接著,再用另一套類神經網路Pose2Frame描繪出人物的外觀,產生動作遮罩(Mask)後,再將給定的新場景結合人物動作畫面,產生一段新的影片。臉書AI研究院表示,這是打造個人化遊戲體驗的前瞻研究,未來可望從日常影片中,就能隨意設計出一套遊戲。(詳全文)
Google MorphNet 模型優化
Google發布優化神經網路模型技術MorphNet
Google AI研究團隊最近發表一項專門優化神經網路模型的技術MorphNet,並將相關的研究成果發表成論文。MorphNet是利用現有的神經網路當作輸入值,並產生一個更小、更快、效能更好的全新神經網路模型。Google已將MorphNet這項技術用來設計生產規模的網路,將神經網路變得更小、更準確,同時,Google也將MorphNet技術用TensorFlow實現,並在GitHub開源釋出。
MorphNet技術是針對現有的神經網路架構進行優化,優化的過程主要經過縮小(shrinking)和擴增(expanding)兩階段的循環處理,在縮小的階段中,MorphNet會利用稀疏正規化的分類方法(sparsity regularization),來辨識低效率的神經元,並將這些神經元從網路中修剪掉。在擴增階段,Google利用寬度乘數(width multiplier)來統一所有層數的擴增,重新分配計算資源。此外,使用者可以在縮小階段後,停止執行MorphNet,來降低神經網路所需的資源。(詳全文)
牛津大學 機器人 ANYmal
牛津大學設計新「行走」AI,幫4腳機器人在崎嶇路面走得更穩
來自牛津大學和法國國家科學研究中心的團隊,日前發表一套新演算法,可幫助4隻腳的機器人選擇穩妥的立足點(也就是接觸面),好在崎嶇不平的路面上前進,更實際應用至自家機器人ANYmal上。
團隊分2步驟來找出新的立足點,也就是先生成機器人引導軌跡,再順著軌跡產生每個立足點。在第1步驟中,團隊透過一套模型來分析環境、辨識可行走的接觸面,並避開靠近邊緣的表面。接著,同套模型會為機器人建立一條「可行走」的引導路徑,讓機器人的四肢順著這條路徑前進。團隊表示,他們的AI系統在任何環境下產生約50步的規畫路徑,7秒內就能完成。不過,他們也提到,目前動態模擬的成功率仍不夠高,還無法在真實世界中部署無人監督的機器人,這也是團隊未來的努力方向。(詳全文)

Mozilla Pyodide 資料科學
Mozilla推出瀏覽器Python直譯器,提供完整資料科學主流套件
Mozilla公開了能夠在瀏覽器上執行的Python直譯器Pyodide。Pyodide是一項實驗性的Python計畫,不需要遠端kernel,就能夠在瀏覽器上運行。Mozilla指出,Pyodide是能完全在瀏覽器上運行的標準Python直譯器。Pyodide的靈感來自Mozilla的另一個計畫Iodide,Iodide是一款在瀏覽器上執行資料科學的運算工具。但是,瀏覽器普遍使用的語言JavaScript缺少了成熟的資料科學函式庫,也缺少許多好用的數值運算功能,像是運算子超載(operator overloading)。
Pyodide能讓使用者使用完全標準的Python,也能存取瀏覽器網頁的API。雖然Pyodide並非第一套在瀏覽器上執行的Python直譯器,但Pyodide提供了完整的資料科學主流套件,比如NumPy、Pandas、Scipy和Matplotlib。(詳全文)
小馬智行 自駕車 演算法
中國自駕車新創利用動態尋路演算法,來優化自駕車點到點道路測試
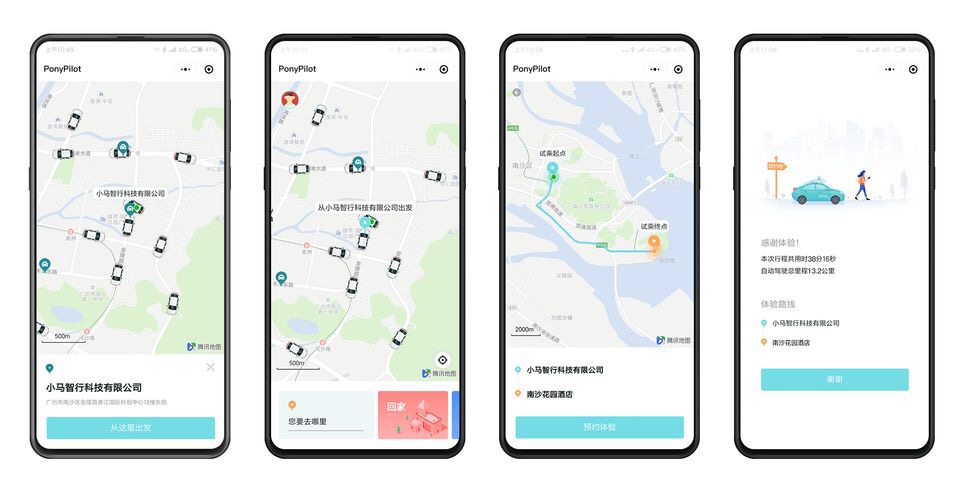
中國自駕車新創小馬智行(Pony.ai)日前於2019年上海車展中表示,已於美國、中國展開1年多的任意點到點自駕車道路測試計畫PonyPilot。為更貼近現實路況,小馬智行並非以固定路線的方式來測試自駕車,而是以任意點到點的方式來進行道路測試。這個做法,讓自駕車必須因應各種突發狀況,為此,小馬智行採用動態尋路(Dynamic Routing)演算法,讓自駕車系統根據車道內狀況,來動態預測路況並優化決策。
在測試期間,小馬智行開發了自駕車試乘App,邀請民眾在指定區域內叫車、試乘。該公司利用測試累積的大數據改善系統,並提升系統面對複雜交通路況和天氣狀況的穩定性。今年除了將擴大城市區域的道路測試範圍,小馬智行也開始研發長途貨運自駕車,公司團隊已完成感測器配置、整合和系統驗證,並於中國主要城市幹道和工業園區進行測試。(詳全文)
哈佛 機器學習 結構預測
哈佛醫學院用新ML方法,使蛋白質結構預測快100萬倍
哈佛醫學院生物學家Mohammed AlQuraishi透過機器學習(ML),來偵測已知的蛋白質結構模式,再將其結果應用到預測別的蛋白質結構上,雖然預測結果對蛋白質折疊的應用還不夠精準,但相比過去傳統的方法,至少快上一百萬倍,這項研究成果也發表於Cell System期刊,相關的軟體和研究結果都在GitHub釋出。
蛋白質折疊在過去幾十年來,一直是一個相當知名的困難計算問題,科學家預測,要確定一種典型蛋白質數千個氨基酸的所有可能結構,可能耗時138億多年。而Mohammed AlQuraishi與同事採用了一種可微分(differentiable)學習的機器學習方法,能根據輸入的資料樣本,向前和向後調整模型本身的元件,來發掘出蛋白質序列和架構之間的關係,這個遞迴基因網路模型就能夠預測出最可能的氨基酸化學鍵連結和旋轉角度。經過數月訓練,預測模型在預測蛋白質結構的表現上,超越了近幾年所有的其他方法。(詳全文)
AWS Alexa 語音辨識
AWS研究團隊找到改善Alexa語音和聲音辨識的新方法
AWS近日發表兩篇論文,解釋如何以機器學習技術,來改善Alexa語音和聲音辨識。首先,AWS開發出一套模型,透過檢視長段音頻來過濾掉非用戶語音的背景聲音訊號,以降低Alexa接收到的電子媒體干擾,比如電視或收音機的聲音。
再來,AWS團隊利用外部資料集,以半監督式學習法來訓練語音事件偵測模型。半監督式學習法是採用小型已標註的訓練資料集,來對照到大型未標註的資料集。AWS團隊特別利用Tri-training模式,也就是以些許不同的資料集,來訓練3個不同的模型,執行同一個任務。AWS團隊提到,這些輸出結果經過池化(Pooling),可以校正半監督式學習常見的問題,也就是改善模型錯誤放大的問題。(詳全文)
圖片來源/TensorFlow、Sam's Club、微軟
AI趨勢近期新聞
1. 臉書用非監督式學習,讓AI在半小時內學會轉換歌手聲音
2. Aruba發布IoT網路探索系統,用機器學習協助分類連網裝置
3. Google發布用於自動語音辨識的資料增強新方法
4. Twitter用ML技術在使用者舉報前,主動找出濫用內容
資料來源:iThome整理,2019年4月
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09