AWS發表一篇跨語言遷移學習技術的論文,將具有足夠訓練資料的語言模型,透過遷移學習轉移至較稀少訓練資料的語言,AWS過去曾將英語語言處理模型轉移至德語,這次則是更進一步,實驗將英語轉移至日語。
由於歐洲語言和日語之間的字符(character)無法配對,這兩種語言之間的轉換較為困難,為了解決這個問題,AWS將日語字符和音譯的羅馬字母一起當作日語系統的輸入資料,AWS也執行了額外大量的實驗,來找出英語模型的哪些部分可轉移至日語。
AWS的實驗中使用了兩個公開資料集,比對羅馬拼音化日語文字的轉移模型和用相同資料訓練從頭訓練的模型,在這兩個資料集中,轉移模型的F1 score都分別改善了5.9%和7.4%,表示模型更穩固。
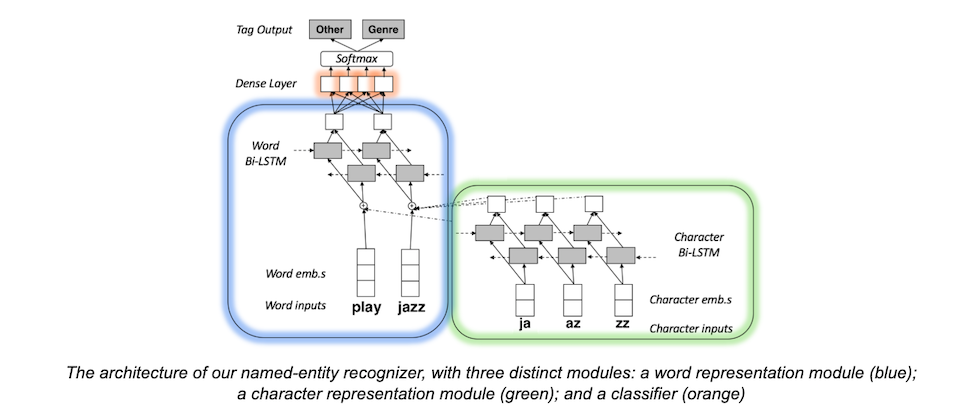
AWS英語和日語轉換模型的目標是辨識名稱實體(entity),或是辨識語句中的名稱類別,像是歌曲名稱、運動隊伍名稱或是城市名等。模型的輸入資料包含詞向量和字符向量兩種類型的向量,這些向量是由神經網路生成,將輸入的語言資料用向量或是字串表示,這些向量投射到多維度的空間後,能夠指出資料之間的相似度,在自然語言理解系統中,像是名稱實體辨識器,通常是兩個詞向量相似度越高,也代表著兩種有相似的語意。
而產生字符向量的網路首先會將字詞拆分城多個元件,像是兩個字母、三個字母等,字符向量空間的相近度能夠顯示字詞子元件的相似度,字符向量通常能夠作為詞向量有用的補充,因為字符向量可以使機器學習系統,針對不熟悉字詞的意義,根據字根、字首和字尾產生的猜測。
在AWS的語言模型中,每個輸入詞的字符都會分別送入雙向長短期循環神經網路(bi-LSTM)中,該網路會依序處理輸入資料,因此每一個輸出都能夠反應之前的輸入和輸出資料,接著,AWS將該網路輸出的字符向量和詞向量,一起放入另一個雙向長短期循環神經網路中,這個網路按照順序處理輸入語句的單詞,產生一個豐富的向量表示輸出,因此輸出夠找出每個輸入單詞的字根、詞綴(affix)、本意和語句中的上下文資訊。最後再將該輸出資料放到另一個分類實體名稱的網路中。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
