
華為團隊發表更輕更小的自然語言處理模型TinyBERT,推論速度比Google BERT快9.4倍。
華為
重點新聞(1004~1010)
華為 TinyBERT NLP
更小更快!華為發表TinyBERT準確度不輸Google BERT
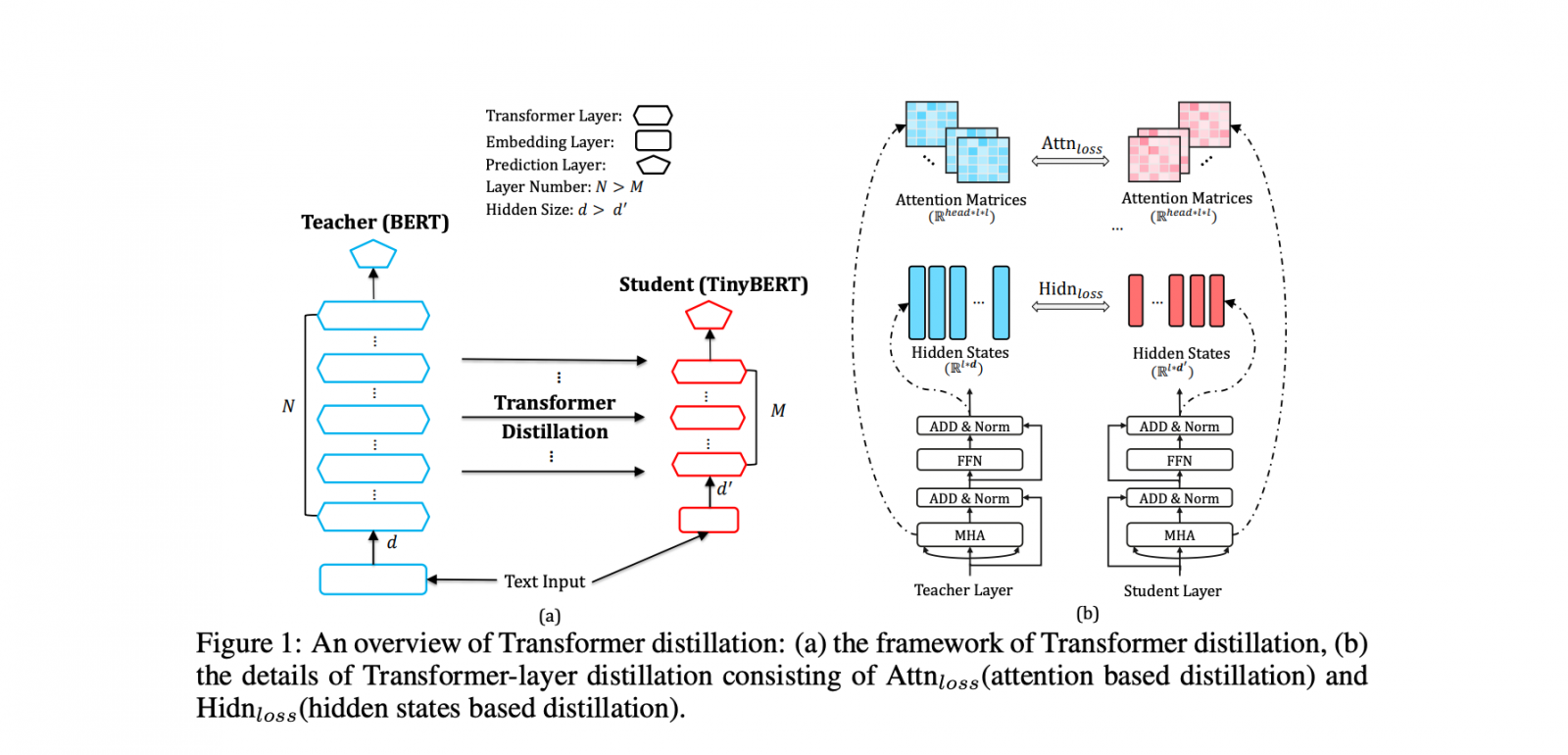
華為日前發表自然語言處理(NLP)預訓練模型TinyBERT,不僅比Google BERT模型小上7.5倍,推論速度更快上了9.4倍,對硬體資源有限的使用者來說是新選擇。一般來說,預訓練模型的準確度遠高於從零開始、利用有限的資料集來訓練的NLP模型,但是,正因為預訓練模型採用巨量資料和參數訓練而成,因此難以轉移到硬體資源有限的裝置上運行,就連Google去年發表、公認最優秀的BERT模型也是。
為了保持準確度並壓縮BERT模型大小,華為開發了知識提煉(KD)和師生框架,也就是將從大型老師網路學習到的語言特徵,轉移到小型的學生網路,來模仿老師網路的行為。至於KD,雖然在許多領域已有研究,但鮮少用於NLP。華為研究員自創的KD有兩個重要概念:Transformer提煉與兩階段學習框架,透過Transformer提煉,可有效從老師BERT模型中提煉出語言模式,而兩階段學習框架的特殊之處,則在於在大型文本語料庫和下游微調過的TinyBERT之間,增加一個通用的TinyBERT,以便將知識轉移到以任務為導向的下游TinyBERT中。(詳全文)
DeepMind GAN TTS
DeepMind用GAN-TTS來產生高逼真的語音
DeepMind日前發表一項研究成果,團隊利用對抗生成網路(GAN)來進行文字轉語音(TTS)任務,產生逼真度高的語音音檔。文字轉語音是一種將文字轉換為類似人類語音的輸出過程,最常見的生成網路就是WaveNet,但由於WaveNet一次只能靠一個音頻樣本來照順序生成語音,不適用於平行運算,也因此,團隊選擇平行性高的GAN來提高TTS效率。
DeepMind的GAN-TTS模型由一個生成器和一系列鑑別器組成,生成器負責產生原始音檔,鑑別器則負責分析這些音檔。DeepMind指出,生成器的輸入值為序列型人類語音音檔和音高(Pitch)訊息,然後要學習利用語音音檔的語言特徵和音高訊息來產生原始音檔,接著,DeepMind利用隨機窗口鑑別器(RWD)來分析音檔真實度,以及音檔與目標語言的對應程度。為了評估模型效果,DeepMind使用平均意見評分(MOS),將GAN-TTS與先前的研究比較,結果顯示,GAN-TTS可生成高保真語音,最佳模型的MOS得分為4.2,只比SOTA等級低0.2分。(詳全文)
TensorFlow 2.0 Keras 深度學習
TensorFlow 2.0正式版釋出,與Keras更緊密整合
開源深度學習函式庫TensorFlow團隊日前終於正式發表TensorFlow 2.0。這個版本強調易用性,加強與Python開源神經網路函式庫Keras的整合,並且簡化API,降低了功能重複(Duplication)。
在與Keras的整合部分,開發者可透過TensorFlow 2.0使用Keras的建模API,像是序列式(Sequential)、功能式(Functional)和子類別(Subclassing)等。而這些API可與Eager Execution功能一起使用,Eager Execution是TensorFlow的命令式程式開發環境,能立即執行程式碼評估操作,讓開發者快速對程式碼除錯並進行迭代。另外,Keras 模型建置API也可以結合tf.data,建置可延展的出入工作流程。(詳全文)
Google 量子運算 深度RL
Google用深度強化學習加速量子運算
Google日前發表一項優化量子運算的方法,利用深度強化學習(Deep RL)來優化量子位元誤差值的預測。Google指出,量子位元(qubit)是量子運算的基本單位,但量子位元有許多難以操控的特性,比如控制電子的缺陷會影響量子運算保真度,進而影響量子裝置的應用。
為進一步控制量子位元,研究員首先要建立實體的量子控制過程模型,以便精準預測誤差值。這很重要,因為在運算過程中丟失的量子訊息,不僅會造成錯誤,還會降低量子運算的表現。Google研究員因而開發了一套優化工具,來提高新量子控制成本函數。他們採用了信賴區間強化學習(也就是策略型深度強化學習方法),可在控制軌跡中使用非局域的特徵,而非像是大海撈針般去嘗試各種解法。Google表示,實驗結果顯示,深度強化學習方法在各項測試基準中表現良好,而且對樣本雜訊具有良好的韌性。(詳全文)

工業局 AI Hub AI產業化
工業局推AI Hub一站式服務,要當AI產業化推手
經濟部工業局與資策會、北市電腦公會、中華民國資訊軟體協會、台灣區電機電子工業同業公會聯手,共同成立AI Hub,提供從需求評估、解決方案、應用實例到客製化隨需服務一站式服務,以加速AI產業化、產業AI化發展。
AI Hub目前結合百位AI專家、百家企業實證和130個新創團隊、16家公協會及法人,來提供企業AI需求評估、供需媒合、解決方案、應用實例,以打造AI的共享資源平臺,縮短產業導入AI的過程。AI Hub現已整合68個解決方案,包含製程智慧化、裝置智慧化、服務智慧化及軟體智慧化四個領域,未來將朝100項解決方案發展。此外,AI Hub也設立了智慧化產品市集,集結50多項AI產品,另也設置演算法平臺專區,已有30多個演算法上架。 (詳全文)
癱瘓 布朗大學 英特爾
癱瘓者有望靠AI技術重新站起來!布朗大學與英特爾合作要以AI接通中斷的神經訊號
美國布朗大學研究團隊聯手英特爾、Micro-Leads Medical和羅德島醫院,展開智慧脊柱介面(Intelligent Spinal Interface)開發計畫,要幫助脊髓損傷的患者,恢復肢體運動與膀胱控制的能力。智慧脊柱介面的構想,是要記錄大腦往下傳遞到脊髓損傷部位的訊號,並利用智慧脊柱介面彌補脊柱損傷造成的神經迴路空白,以驅動下方脊髓,同時從受傷脊髓下方來的訊號,也能夠往上傳遞刺激或是驅動上方的部位。
這個專案的關鍵,就是要用AI來解讀脊神經訊號。布朗大學認知科學研究團隊將和英特爾AI團隊合作,要找出數學上的抽象,並整合現代機器學習基礎架構,理解脊髓的運作方式並設計模型,以開發出高效率且通用的系統。Micro-Leads Medical將提供高解析度的脊髓刺激技術HD64,來增加治療部位的範圍和精確度。(詳全文)

臉書 Hydra 程式開發
臉書開源能簡化複雜應用程式開發的框架Hydra
臉書開源了能簡單配置複雜應用程式的開發框架Hydra,不只能減少開發者複製貼上樣板程式碼(Boilerplate Code),也能動態編寫(Compose)配置,而且Hydra採用了可插拔架構,因此可以與原本組織的基礎設施良好的整合。
Hydra是一個輕量級的框架,可透過編寫和覆蓋配置,來簡化Python應用程式的開發。開發者不必重新撰寫大量的樣板程式碼,像是定義命令列標籤、操作配置檔案以及配置日誌等,就能輕易加入新功能,以符合新的使用案例和需求。Hydra讓開發者可在本地或遠端啟動應用程式,並且使用同一個指令附加不同的參數,就能執行不同的工作,減少相關的腳本支援。Hydra提供了動態命令列頁籤完成功能,幫助開發者探索複雜配置選項,也減少輸入錯誤。(詳全文)
圖片來源/Google、華為、布朗大學
AI趨勢近期新聞
1. 自然語言處理函式庫spaCy 2.2釋出,加入資料增強系統、提升字詞配對速度
2. 法國將成為歐洲第一個以人臉辨識來驗證電子身分的國家
3. AWS機器學習服務Amazon SageMaker開放使用EC2最強GPU執行個體
資料來源:iThome整理,2019年10月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-10

2026-02-09


2026-02-10

2026-02-13