
李宗翰攝影
【美國拉斯維加斯現場報導】機器學習是當前企業發展AI應用的重要技術基礎之一,在AWS今年re:invent大會的第二天,該公司執行長Andy Jassy所發表的主題演講,也證實了這股技術應用趨勢,正在持續發展、擴張當中,因為,該類雲端服務目前正是AWS成長最快的業務應用,他表示,AWS目前已擁有數萬名採用機器學習服務的用戶,而且,他們的用戶數量之多,是市占第二雲端服務廠商的兩倍。

隨後,Andy Jassy也針對AWS提供的各種機器學習服務,區隔出三大類型,逐一介紹最新進展。它們分別是:位於底層的機器學習框架與基礎架構,居中的機器學習服務,以及上層的人工智慧服務。
以底層而言,Andy Jassy自豪地表示,全球有85%的TensorFlow框架,是在AWS的雲端服務環境當中執行,而在執行機器學習訓練的處理作業上,若以幾種針對AWS環境最佳化調校的主要機器學習框架,搭配AWS提供的GPU執行個體P3,來進行Mask R-CNN深度學習模型的訓練,比起用戶自行搭建硬體設備來執行相關作業,可節省2成左右的處理時間。
位於中間層的AWS機器學習解決方案,主要是全代管機器學習服務SageMaker,它是在2017年舉行的re:Invent大會推出,資料科學家與開發人員可運用這套雲端服務,輕鬆地進行機器學習模型的建構、訓練與部署。到了2018年,SageMaker已陸續增添50種以上的功能。
在2019年底舉行的re:Invent大會上,AWS繼續發布SageMaker相關的新功能,其中最受眾人矚目的部分,就是用於機器學習的整合式開發環境(IDE),名為SageMaker Studio,並基於這套工具,提供Notebooks、Experiments、Autopilot、Debugger、Model Monitor等特色,支援開發與部署機器學習模型的自動化執行、整合、除錯、監控的操作。
處於最上層的人工智慧服務(AI Services),AWS提供不需要懂得機器學習技術運作方式的功能項目。早先他們陸續推出影像辨識(Rekognization)、語音辨識(Polly、Transcribe)、文字辨識(Translate、Comprehend、Textract),以及對話機器人(Lex)、個人化推薦(Personalize)、預測(Prediction)等服務,今年,他們提供了更多與企業日常業務運作更密切相關的功能項目,像是詐騙偵測(Fraud Detector)、程式碼檢視與剖析(CodeGuru)、往來客戶聯絡分析(Contact Lens for Amazon Connect)、企業內部搜尋(Kendra)。
因應機器學習開發流程各階段的需求,率先推出網頁版IDE工具
在今年re:Invent大會推出的機器學習各項新功能當中,SageMaker Studio無疑是針對開發人員與資料科學家的重要特色,號稱能大幅提升生產力。
基本上,它提供了單一操作介面,能讓用戶著手進行機器學習模型的建立、除錯、訓練、部署、監控、維運,並提供多種功能,像是:伸縮式腳本套用、實驗測試管理、模型自動建立、除錯、組態剖析,以及模型飄移偵測。

整體而言,在這套整合式開發工具當中,開發人員可以查看原始程式碼、相依性、文件,以及用於行動App的圖片等應用程式資產,整理出彼此之間的組織結構。同時,他們也能建立專案資料夾,管理資料集與用於自動化執行的筆記本,並與其他人共同討論筆記本的設計與後續處理的結果。

以目前上線的SageMaker Studio而言,AWS也在本次用戶大會上,特別強調下列5種內建的功能特色。
Notebooks
SageMaker Notebooks所提供的功能,主要是可一鍵操作的Jupyter notebook,能搭配AWS EC2將相關環境快速建置起來。這項服務包含了執行或重新建立機器學習流程所需的各種要素。在這之前,開發人員若要檢視或執行筆記本,需在SageMaker上建置一個運算執行個體,才能支援筆記本所設定的自動化應用程序。假如開發人員需要更多運算力,在那樣的狀態當下,他們必須啟動新的執行個體、將筆記本傳輸過去,再將舊有的執行個體關閉;此外,由於筆記本需搭配運算執行個體來執行,但筆記本通常會存放在開發人員的工作站電腦當中,因此,難以與他人共享與進行反覆的協同作業。

而在SageMaker Notebooks服務當中,提供了可伸縮自如使用的Jupyter notebook,能讓開發人員輕鬆地調高或降低筆記本所需的運算資源(包含GPU加速器),而且這些異動會自動在背景服務當中進行,不會打斷開發者的工作。
開發者不需將時間耗費在關閉舊有的執行個體,以及重新在新的執行個體建立所有的工作。能夠更快開始建立機器學習的模型。AWS強調,只需一個按鍵,開發者就能將筆記本分享出去,系統會自動重新產生指定的環境與程式庫相依性。因此,這樣的機制能簡化多人協同的模型建構作業,開發者能夠將手上的工作交給其他人,並在他們既有的工作之上,繼續建構模型。

Experiments
這套機器學習IDE工具第二個主打的功能,則是SageMaker Experiments,它能協助簡化管理機器學習模型的反覆作業,讓開發者能夠組織與追蹤相關的工作,進而更快培養出高品質的模型。

一般而言,機器學習通常會牽涉到多數反覆處理,目的是為了隔離與測量變更特定輸入之後所產生的漸進變化,開發者在這些反覆處理過程當中,會產生數百種加工物,像是模型、訓練資料、參數設定,但目前他們必須仰賴試算表來追蹤這些實驗,並且手動分類這些加工物(artifacts),以便瞭解實驗如何受到影響。現在有了SageMaker Experiments,能讓開發者管理這些反覆處理,當中將會自動擷取開發者輸入的參數、組態與結果,並將這些資料存為個別的「實驗體」,之後開發者就可以透過更簡單的方式進行各種管理工作,像是:檢視目前正在進行的實驗,根據特徵來搜尋指定的實驗,審視先前的實驗與結果,或是透過虛擬的方式來比較實驗結果。這項功能將會保留每個實驗的完整體系,因此,一旦模型開始開始脫離原本所要輸出的部份時,開發者可以及時倒回相關的程序,並且對加工物進行檢測。

Debugger
在軟體開發過程當中,除錯是不可避免的工作,而在開發機器學習模型時,也需要進行這樣的處理,而在SageMaker Studio提供了Debugger的功能,開發者可透過這項機制對模型的訓練,進行除錯與剖析,以便改善精準度、減少訓練時間,並且促進對於機器學習模型的了解。

當前的模型訓練過程仍是相當不透明,訓練時間可能很長,而且難以進一步調校,而這種黑箱作業也會導致開發者難以理解與詮釋模型的運作方式。若採用Debugger,用戶在SageMaker訓練的模型,可自動發出關鍵測量指標,讓SageMaker Studio,能夠進行收集與審視(其他應用程式也可透過SageMaker Debugger的API來整合),這些指標將提供訓練精準度與效能的即時回饋,因此,一旦系統偵測到訓練問題,SageMaker Debugger可以提供警告與修正的建議。
此外,這項功能也能幫助開發者詮釋模型的運作方式,並且重現早期的處理步驟,讓開發者能夠更為理解神經網路的運作。

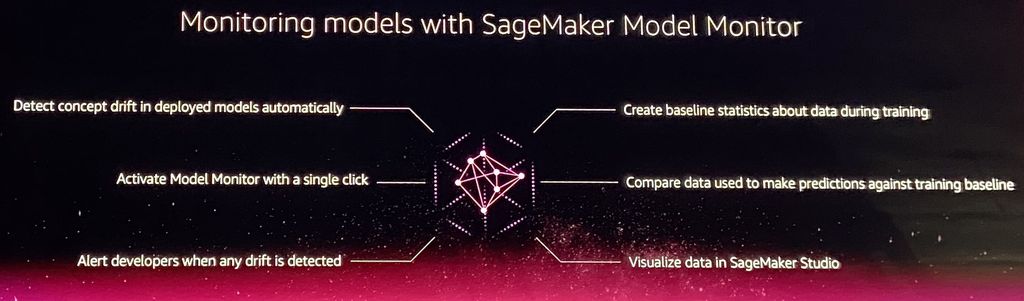
Model Monitor
開發機器學習模型時,除了注意除錯,也要處理概念飄移(concept drift)的情況,SageMaker Studio提供了Model Monitor功能,能讓開發者以更簡易的方式來調整訓練資訊或演算法,偵測與修正機器學習模型的概念飄移。

對於部署到正式環境的機器學習模型而言,目前影響精準度的重要因素之一,就是用於產生預測的資料,開始出現異於用於訓練的資料的情況(像是經濟情況變化帶動了新的利率,進而影響了家用採購預測,或是季節變換帶來不同的溫度、濕度、氣壓,結果也影響了設備維護排程的可信度),如果資料開始變得不同,它將會導致所謂的概念飄移,而這會使得用於預測的模型範式,不能再繼續套用。而在Model Monitor的功能裡面,可建立一套關於模型訓練期間的基準統計,並且以這個模型訓練基準來比較那些用於預測的資料。
當Model Monitor偵測到模型飄移時,開發者會接到警示,並透過圖表的呈現來辨識出根本原因,也可以自行撰寫所需要的規則,讓Model Monitor得以進行監控。
AutoPilot
若要提升機器學習模型開發的生產力,開發者同樣需要自動化的模型建構機制,對此SageMaker Studio提供了AutoPilot功能,而且,開發者還是能繼續保有對於模型的控管與執行狀態掌握。
目前若要執行自動化的機器學習,開發者已經有足夠的方法來建立初始模型,但觀於模型如何建立及模型裡面的狀態,卻無法拿到任何可用的資料,因此,假如模型本身的品質只有一般的水準,但開發者希望提升時,可能會找不到合適的作法。
此外,現今的自動化機器學習服務,僅能為用戶提供簡單的模型。然而,有時候用戶想要做一些條件交換,像是在特定版本的模型當中,犧牲一點點精準度來交換一些變化,希望能帶來較低延遲的預測產生速度,但目前這類服務只提供一個模型,而無其他選擇。
在SageMaker Autopilot裡面,開發者只需幾個點選動作,就可以驅使系統去自動執行許多工作,像是檢測原始資料、套用特徵處理器、挑選最佳的演算法組合、訓練多個模型、調校多個模型,以及追蹤模型的效能,並且根據效能來列出模型的排名。
而經過自動處理後所產生出來的結果,會是關於表現最佳的模型推薦,讓用戶能夠放心進行部署,而且僅需要投入一點時間與心力,即可訓練、完整掌控模型的建構與內部狀態。

對於缺乏機器學習處理經驗的人,SageMaker Autopilot也很適用,因為他們可以單獨根據手上的資料,即能簡易地產生出模型。若是有相關經驗的開發者來使用SageMaker Autopilot,也可以藉此在想要進一步執行各種反覆處理的團隊當中,快速開發出符合基準組態要求的模型。
以目前的功能來看,SageMaker Autopilot最多可提供50種機器學習的模型,它們都已通過SageMaker Studio的檢測,所以,開發者可從中揀選符合他們應用場景需求的最佳模型,而且,也能根據他們所選的最佳化模型來考量相依的因素。

運用與亞馬遜相同的機器學習技術,提供更多高階的人工智慧應用服務
關於人工智慧的應用需求,其實並不只是提供各種開發機器學習的輔助機制,對於不諳這類技術運作原理與相關管理維護作業的用戶而言,其實,也能藉助雲端業者提供的高階代管服務,即可善用機器學習技術來簡化各種工作,進而為其使用者提供更多元的AI操作體驗。
先前AWS在這個領域裡面推出的人工智慧應用服務,所針對的需求大多是通用的數位內容轉換,2018年底延伸到推薦、預測、自然語言處理等進階AI服務,而AWS在今年底推出的相關服務,又有了重大突破,那就是跨入更多企業日常運作所需的應用,像是詐騙偵測、程式碼審視與剖析、往來客戶聯絡分析、內部資料搜尋。
Fraud Detector
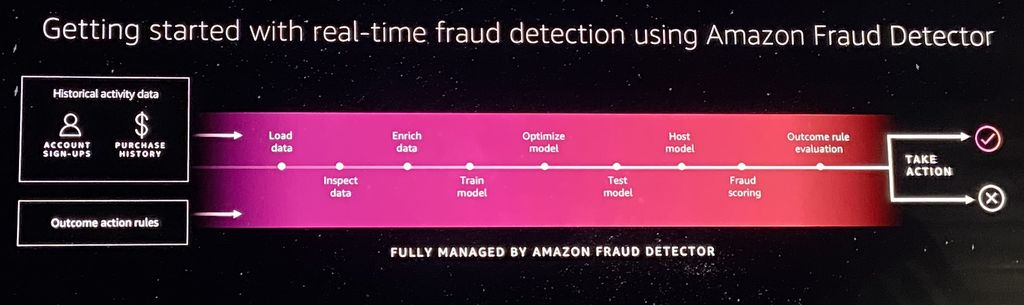
在今年底最新發表的人工智慧應用服務當中,Andy Jassy最先介紹的是詐騙偵測服務Amazon Fraud Detector,它能協助企業即時識別線上身分與支付詐騙行為,而且,這裡面採用的判別技術,是由本身就在經營電子商務的亞馬遜(Amazon.com)所發展出來的。

這套服務會同時使用詐欺與合法交易的歷史資料,對其執行機器學習模型的建構、訓練與部署,能為用戶提供即時的詐騙風險預測。在試用初期,用戶只需將一些資料上傳到S3,像是與交易相關的電子郵件位址、IP位址,也可自行增添帳單地址、電話號碼,接著執行自定的機器學習模型訓練。
如果用戶所要預測的詐騙顧客類型,是關於新帳號或線上支付的詐騙行為,Fraud Detector可運用亞馬遜數十年累積的詐騙風險偵測分析經驗,執行資料的預先處理、演算法選擇,以及模型訓練。
CodeGuru
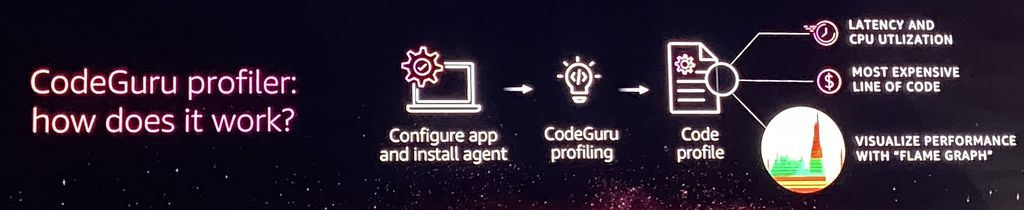
Andy Jassy第二個揭露的人工智慧應用服務,是針對軟體開發人員的程式碼審視(code reviews),以及應用程式剖析(application profiling)需求,用戶可運用AWS提供的機器學習技術來取得程式碼自動化分析的機制,但這裡所要提供的功能不只是幫忙突顯既有程式碼的撰寫錯誤、品質不佳與效能執行問題,還要找出耗費最多IT資源的程式碼片段。

對於雲端服務的用戶而言,這樣的執行效率檢視分析功能相當實用。提升軟體品質、縮短開發時間,對於軟體生命週期的管理,固然很重要,但在雲端服務的環境當中,因為業者會根據使用規模大小,以及持續時間長短來計費,若特定程式碼佔用過多資源與執行時間,就會對用戶造成不必要的成本支出,因此對於這樣缺乏經濟效益的程式碼,AWS認為,他們需要推出這樣的服務來幫助用戶省錢,而關於這類軟體品質差、效率不彰的問題,所造成的影響不只是抽象的人力成本,還要考量到具體的雲端服務費用,因此,他們特別以「最花錢的程式碼(most expensive lines of code)」來形容。
開發人員要怎麼使用CodeGuru來審視程式碼?他們仍然照常將程式碼提交到GitHub、CodeCommit等軟體開發倉庫服務,然後再將CodeGuru設為程式碼審視人員之一即可,不需調整原本的作業流程或額外安裝軟體。隨後CodeGuru會接收到程式碼下拉的請求,並且運用系統預先訓練好的模型,自動對用戶程式碼執行評估,而這些完成訓練的機器學習模型,所根據的程式碼資料主要有兩大來源:亞馬遜數十年來所審視的程式碼,以及GitHub排名前十大的開放原始碼軟體專案。
處理過程中,CodeGuru會針對程式碼的品質來分析程式碼的異動,如果發現問題,會在程式碼下拉請求當中,增添一段評論敘述,讓開發者能夠清楚看到該段程式碼所在的行數位置、問題類型,以及系統推薦的修正方式(像是範例程式碼與相關說明文件的連結)。


而在應用程式剖析的部份,CodeGuru會利用機器學習技術,找出最耗費雲端服務資源的程式碼。為了要達成監控的目的,用戶須在他們開發的應用程式當中,安裝小型、輕量的代理程式,讓CodeGuru能夠以5分鐘為頻率,定期觀察應用程式執行時的狀態,以及剖析程式碼的組態。而這樣的觀測會記錄CPU利用率與存取延遲,以及直接對應的程式碼位置,最後會產生圖表,協助用戶找到那些導致效能瓶頸的程式碼片段。
目前有哪些企業採用CodeGuru?AWS表示,亞馬遜內部團隊正在使用CodeGuru,他們剖析的應用程式數量已經超過8萬支;而在2017年到2018年之間,這套服務提供給亞馬遜的內部版本,也協助隸屬於該公司消費業務的Amazon Prime Day團隊,大幅提升應用程式的執行效率──CPU利用率增加了3.25倍,在Amazon會員狂歡購物節期間,他們需管理的執行個體數量也隨之減少,整體成本降低近4成。

Connect Lens
第三個AWS今年主推的人工智慧應用服務,是針對AWS客戶聯絡中心雲端服務Amazon Connect,所提供的分析服務Contact Lens,當中運用了機器學習的技術,讓用戶能夠從與顧客的對話裡面,理解他們的意見、認知的趨勢,以及接受的價值,藉此改善顧客體驗及辨別顧客意見回饋。目前AWS公布多家先期採用這項顧客資料分析服務的企業,包括:財務軟體公司Intuit、金融投資財務管理公司John Hancock、媒體集團News Corp、個人財富與利益解決方案廠商Accolade,以及行動電信與能源供應商amaysim。

基本上,單就Amazon Connect而言,它採用的技術,與目前支撐亞馬遜顧客服務的技術是相同的,號稱能以更低的成本讓用戶經營他們的客戶聯絡中心,而且能支援數千個值機員的使用。若這項服務同時搭配Contact Lens使用,AWS表示,客戶服務主管可以透過Amazon Connect網頁主控臺介面,毋需具備程式撰寫與機器學習等技術專業,即可進行多種功能的操作。例如,從顧客對話裡面,發現新興的主題與趨勢,並能夠對客戶來電與對話文字記錄,快速實施全文檢索,以便找出解決顧客的疑難雜症,同時,還能提供來電與文字對話的分析,進而改善客服人員的效能。
若在電話進線期間發生問題,Contact Lens也會將相關警示發給主管,讓他們在顧客體驗開始變差的初期,就可以介入。
除了高度整合Amazon Connect,Contact Lens的詮釋資料,像是文字謄本、意見、分類標籤,都是依照妥善定義的資料綱要來儲存,而且會放置在用戶的S3資料桶當中。企業可以輕易地匯出這些資訊,並且運用Quicksight、Tableau這類圖表分析工具,將其產生更進一步的解析,以及結合其他來源的資料。

Kendra
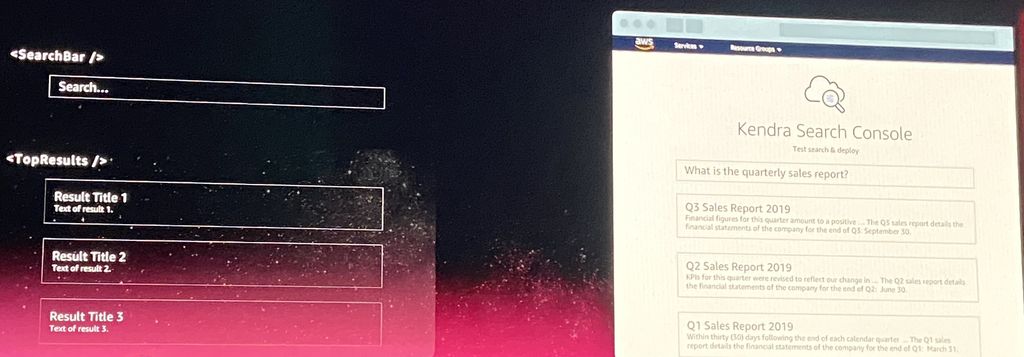
在今年re:Invent大會最後介紹的人工智慧應用服務,是提供企業搜尋功能的Amazon Kendra,裡面運用了自然語言處理,以及其他機器學習技巧,能夠統合企業內部的多個資料孤島(data silos),並且持續提供高品質的通用查詢結果,AWS認為,相較於目前透過關鍵字查詢而得到的隨機連結列表,這項新的服務足以取而代之,提供更好的選擇。

有了Kendra,企業的員工若要進行內部資料搜尋,可以運用自然語言的表達方式來進行查詢,例如,他們可以鍵入問題內容敘述,而不只是單純輸入關鍵字,而系統也能夠用對話的方式回答問題,並且提供相關的服務與網站連結。
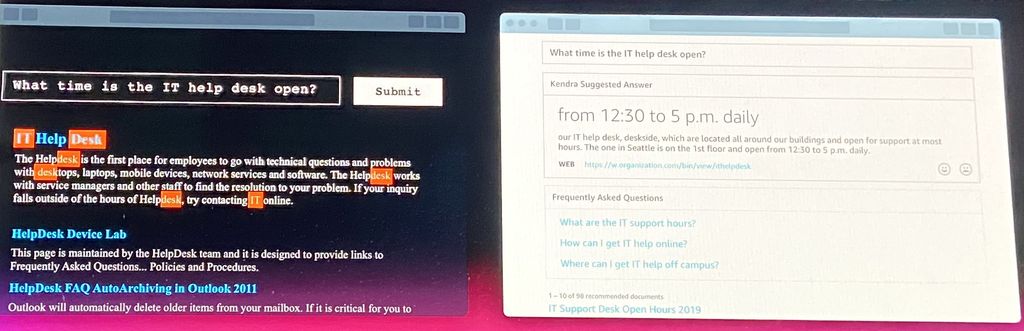
同時,這樣的服務,能夠橫跨多種應用系統、網站入口與維基共筆內容管理系統(Wiki)進行整合,用戶只需在AWS管理主控臺上進行簡易操作,例如指出需要查詢的文件儲存庫位置,Kendra就會匯集所有資料,以便建構集中的索引。
在文件安全控管的部份,這項服務會掃描文件當中的許可權限,可確保搜尋結果只會列出該名使用者所能存取的文件,以便符合企業既有的文件存取政策。
此外,Kendra會根據不同用戶的差異,自動重新訓練機器學習模型,以便改善查詢精準度,而當中會運用到的分析資料來源,包括點選資料(click-through data)、使用者位置、意見回饋,若累積更多時間的使用與資料分析,可為搜尋提供更理想的回答效果。

涵蓋底層與中高階機器學習的應用需求,提供整合度更高的開發工具與AI服務
整體而言,今年AWS在機器學習領域所推出的雲端服務,在應用的格局上,都有進一步突破。
例如,在SageMaker的機器學習開發平臺服務,AWS提供了功能豐富的整合式開發工具,能夠大幅簡化機器學習模型的設計與測試流程。
而在人工智慧應用服務的部份,AWS今年增設了更多與亞馬遜目前使用相同機器學習技術的解決方案,不只是2018年底宣布推出、2019年6月、8月陸續登場的個人化推薦與預測服務,他們也預告未來將發布與企業商務運作需求密切相關的服務,涵蓋了顧客身分辨識、顧客往來分析、應用程式效率與成本節約,以及內部資料搜尋等層面,繼續為雲端服務業者的機器學習與人工智慧技術,提供更多專業領域的應用服務選擇。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06