
LINE三大事業體LINE、LINE Bank、LINE Pay共12個團隊在臺徵才。
重點新聞(0207~0213)
LINE 資料科學 人才
LINE在臺12個團隊大舉徵才,要網羅AI、資料科學、資安等人才
LINE近日在臺展開人才招募,包括LINE、LINE Bank和LINE Pay等三大事業體共12個團隊,要來尋找臺灣人才,範圍涵蓋AI、資料科學、資安、前後端、測試和用戶端開發等領域。其中,LINE在臺灣就擁有2,100萬活躍用戶,而今年的目標,是要全面運用AI來提升使用者體驗,共有4個團隊開出職缺,其一就是推動LINE Brain計畫的LINE資料工程團隊,要尋找NLP、OCR、eKYC的高手。
再來則是今年即將開業純網銀的LINE Bank,共有6個團隊開出20多個職缺,像是LINE Bank App開發團隊、LINE Bank核心系統團隊、資安團隊等,還有負責風管、支付、數位客服和辨識的營運支援系統團隊。至於LINE Pay,有2個團隊招募成員,分別是負責開發創新支付和金融服務體驗的LINE Pay Development團隊,以及規畫產品上線測試流程、優化服務品質的 LINE Pay QA團隊。LINE即日起接收履歷,至3月9日止,經審核與線上測試後,將於4月25日臺灣辦公室舉辦最終面試。(詳全文)
空拍影片 影像辨識 德國航空中心
要賦予空拍機解讀影片能力!德國航空中心發表空拍影片資料集
為加速空拍機影片自動處理影像的能力,德國航空中心(DLR)聯手慕尼黑工業大學(TUM),發表空拍機影片資料集。該資料集名為空拍影片事件辨識(ERA),包含了25個事件類別、共2,866個從YouTube上收集且經標註的影片,每個影片都是24 FPS、長度約5秒。關於事件分類,團隊首先從維基百科上收集24個事件,再新增一個非事件類別,放置其他無法歸類的影片。這些類別包含了安全、交通、災難、生產、社會和體育活動等。有別於其他資料集,團隊也收集了在惡劣條件下拍攝的影片,比如低解析度、極端照明和惡劣天氣等。
此外,為了提供空拍影片專屬的基準測試,團隊也利用該資料集,來測試現有的深度學習工具,像是單幀影像分類模型和影片分類模型。團隊發現,就遊行或抗議、音樂會分類來說,時間關係網路(TRN)表現最好,顯示TRN有潛力用來辨識較難區分的行為事件。(詳全文)
.JPG)
邊緣AI Arm AI處理器
再攻邊緣AI市場!Arm發表兩款AI處理器
鎖定邊緣AI需求,處理器大廠Arm日前發表兩款AI處理器Cortex-M55和Ethos-U55。Arm指出,Cortex-M55是自家AI能力最強大的處理器,也是第一個採Armv8.1-M架構、內建Arm Helium 向量技術的處理器,可大幅提升終端數位訊號處理(DSP)和機器學習(ML)效能,與前代Cortex-M處理器相比,DSP和ML可分別提升5倍和15倍效能,也更省電。
至於Ethos-U55,則是Arm針對Cortex-M推出的首個微神經網路處理器(microNPU)。Arm表示,Cortex-M55與Ethos-U55搭配起來,能因應需求更高的ML系統;與現有Cortex-M處理器相比,兩者組合的效能可提升480倍。這兩款AI處理器,最快預計明年初上市。(詳全文)
微軟 語言生成 T-NLG
突破軟硬體瓶頸,微軟發表170億個參數的語言產生模型
微軟發表最新語言產生模型T-NLG,具170億個參數,是有史以來最大的語言產生模型,可產生單詞來完成開放式的文字任務,還可回答問題、總結文件等。
微軟能建立這麼大的模型,是因為打破了軟硬體技術的瓶頸。微軟採Nvidia DGX-2配置,以InfiniBand連接加速GPU之間的通訊,並使用Nvidia Megatron-LM框架,以張量切分技術將模型分到4個V100 GPU上。此外也運用DeepSpeed函式庫和ZeRO最佳化方法,使每個節點的批次處理大小增加4倍,減少了3倍訓練時間。測試發現,在標準語言任務WikiText-103困惑度的量測表現,T-NLG比OpenAI的GPT-2和Megatron都還要低,此外,T-NLG還能應付零次問答,不需要上下文,就能直接回答問題。(詳全文)

Jigsaw 假照片 Assembler
一眼看穿!Jigsaw發表可辨識假照片的平臺Assembler
Alphabet旗下子公司Jigsaw日前發表一款實驗性平臺Assembler,整合了各種偵測技術,讓新聞從業人員或事實查核人員透過單一平臺,就能辨識影像的真偽。
Assembler整合了多種照片偵測工具,每個工具都有特定的用途,比如辨識照片中的「複製-貼上」程序,或是偵測照片的亮度有所變更。此外,Jigsaw也自行打造兩款工具,一是專門用來辨識DeepFakes的StyleGAN,可區分真人與DeepFakes的不同;另一個工具是一套完整的模型,可整合不同偵測工具的結果,分析照片中曾被變更的動作,一次揪出照片中的所有古怪之處。Assembler目前仍處早期開發階段,歡迎外界貢獻各種偵測模型。(詳全文)


臉書 PyTorch3D 電腦視覺
臉書開源PyTorch3D電腦視覺函式庫,要簡化3D深度學習
臉書AI研究院近日開源自家PyTorch3D電腦視覺函式庫,要利用PyTorch來簡化3D深度學習的流程。臉書指出,該PyTorch3D是一個高度模組化的函式庫,具一系列常用的3D算子(Operator)和損失函數,也提供模組差分算圖API,讓使用者可將函數導入深度學習系統。
進一步來說,PyTorch3D函式庫融合了臉書自家的2D識別函式庫Detectron2,將物體辨識能力帶到3D領域。使用者可利用PyTorch3D,來進行多種3D深度學習研究,像是3D重建、光束調整法(Bundle adjustment)等,甚至是3D推理。與此同時,臉書也提出一套3D資料結構Meshes,可用來批次處理異質網格,使深度學習應用更有效率。(詳全文)
Google 機器學習評估 ML-fairness-gym
Google釋出用來評估機器學習系統長期影響的工具
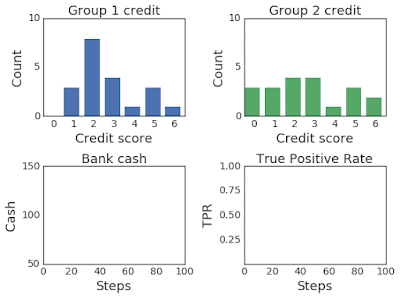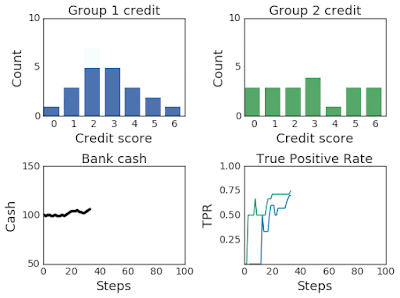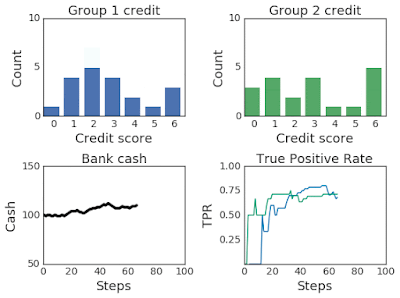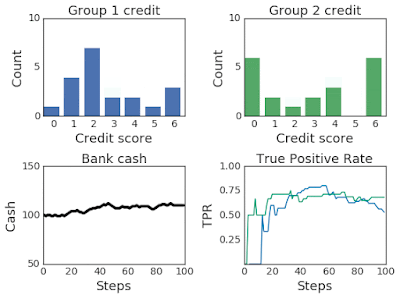
為提高AI透明度,Google日前釋出一套分析模擬工具ML-fairness-gym,用戶可透過簡單的模擬,來了解機器學習決策系統在社會中的長期影響。
ML-fairness-gym採用Open AI的Gym框架,來模擬序列性決策。在這個框架中,代理人(Agent)會與模擬環境互動,並在每個步驟中,選擇一個影響環境狀態的動作。接著,環境就能顯示代理人所參考的觀察資訊,也就是用來影響後續行動的訊息。(詳全文)
Google 自然語言生成 LaserTagger
Google開源可即時產生精確文字的AI模型LaserTagger
Google團隊開發一款AI文字編輯模型,可預測編輯操作序列,把來源文字轉換成為目標文字。Google表示,LaserTagger是一種精確不易出錯的文字產生方法,比過去的方法更容易訓練,執行速度也更快。
Google在2014年提出Seq2seq方法,主要用於自然語言生成(NLG),像是段落融合、文字摘要和文法糾正等文字編輯工作。不過,Seq2seq有三大缺點,比如產生不支援的文字、需要大量訓練資料、文字產生速度慢。不過,LaserTagger透過限制字彙表來縮小輸出的決策空間,可避免模型隨意添加字詞,不易產生不支援的字。此外,就算只用數百或是數千個範例訓練,LaserTagger也能產生合理的結果,Seq2seq則需要數萬個才行。在速度上,LaserTagger預測速度是Seq2seq的100倍,因此更適合即時應用。(詳全文)
圖片來源/德國航空中心、Google、Jigsaw、微軟
AI趨勢近期新聞
1. HackerRank調查:開發人員最想學的程式語言是Go跟Python
2. Google釋出多語言問答基準TyDi QA
3. Google搜尋技術加持,Waymo自駕車物體辨識能力再升級
4. 簡立峰卸任Google臺灣總經理後加入臺灣新創Appier董事
資料來源:iThome整理,2020年2月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10