,號稱是全球最大機器可讀的新冠病毒相關語料庫,要鼓勵開發者利用NLP從中找出新洞察,來對抗疫情。")
艾倫AI研究院與美國國衛院、白宮、微軟和其他機構共同釋出武漢肺炎資料集COVID-19 Open Research Dataset(簡稱CORD-19),號稱是全球最大機器可讀的新冠病毒相關語料庫,要鼓勵開發者利用NLP從中找出新洞察,來對抗疫情。
重點新聞(0313~0319)
艾倫AI研究院 武漢肺炎 開放資料 Kaggle挑戰賽
AI2聯手微軟、白宮和美國國衛院,開源釋出武漢肺炎研究資料集
由微軟共同創辦人成立的艾倫AI研究院(AI2)聯手微軟研究院、白宮科技辦公室(OSTP)、美國國衛院(NIH)的國家醫學圖書館,以及其他組織,共同釋出武漢肺炎開放研究資料集COVID-19 Open Research Dataset(簡稱CORD-19),內含2萬9千多篇新型冠狀病毒相關研究論文,其中1萬3千多篇為全文可瀏覽。AI2表示,這是機器可讀的最大型新冠病毒語料庫,而釋出資料集的用意,是希望全球研究員可藉自然語言處理(NLP)技術和AI,從中找出新洞察,來對抗疫情。
該資料集收錄同儕審核、正式刊登的論文,以及在bioRxiv、medRxiv等檔案收藏服務中的文章,且每周更新一次。此外,資料分析平臺Kaggle也舉辦了CORD-19挑戰賽,已根據WHO新冠病毒研究藍圖和美國國科院研究主題,列出幾項關鍵問題,作為挑戰任務,每項任務的獎金為1,000美元。Kaggle希望藉此鼓勵開發者,找出對抗疫情的關鍵資訊。(詳全文)
.JPG)
BERT 自然語言 模型評比
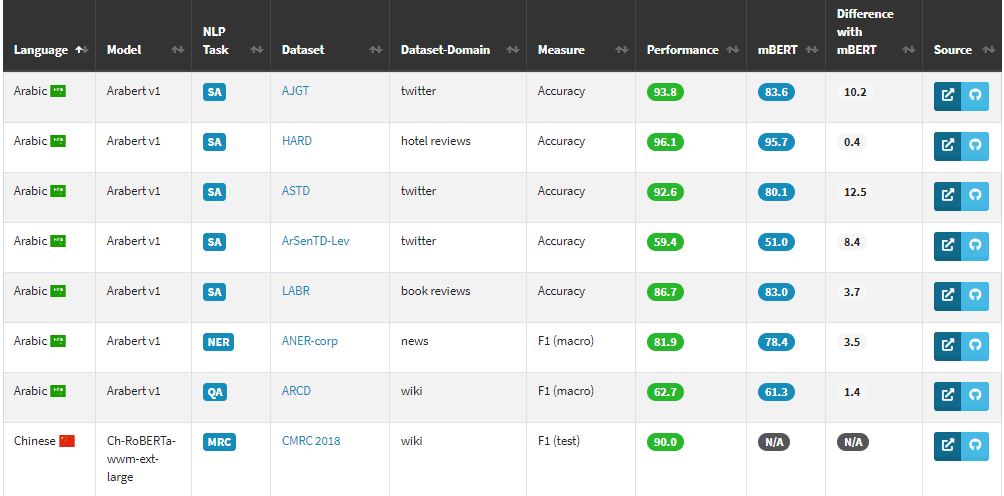
哪款BERT比較優?BERTLang網站告訴你
義大利博科尼大學團隊日前發表BERT Lang Street網站和研究論文,要來幫開發者評比各種BERT語言模型和多重語言模型mBERT的效能。自2年前Google發表雙向編碼自然語言模型BERT以來,大幅改善自然語言理解能力寫下了自然語言處理(NLP)里程碑。之後,Google也利用104種語言的語料庫,訓練出多重語言模型mBERT,作為通用的語言理解模型。不過,現階段針對mBERT和各語言BERT模型的評比,幾乎沒有明確的比較。
於是,博科尼大學團隊架設了BERTLang網站,來提供每個模型的架構和領域表現等評比。目前,團隊已針對18種語言、29項任務,測試了30個特定語言的BERT模型,也得到了177種測試結果。其中,在所有29項任務中,特定語言的BERT模型表現皆比mBERT要好。這些結果,都已公布於網站供開發者查詢。(詳全文)
Google 深度學習 行銷
目標打開DNN黑盒子!Google開源JAX函式庫Neural Tangents
Google日前釋出JAX軟體函式庫Neural Tangents,要來解開深度學習黑盒子。團隊指出,近來深度學習網路(DNN)在自然語言、對話代理等任務表現大幅進步,有人會懷疑,為何DNN參數過度設置,卻善於歸納?其中一個關鍵是,DNN的寬度增加時,模型表現就越規律、越容易理解。
不過,要無限增加DNN寬度,仍有些挑戰,像是需要深厚的數學知識,且要對每個架構分別設計。為此,Google開源Neural Tangents,開發者可輕鬆定義、訓練和評估寬度無限(Infinite)的DNN;進一步來說,無限寬DNN是指,由架構決定內核函數的高斯過程(GP),而Neural Tangents可提供卷積、池化、殘差連接、非線性特性等組件,讓使用者建立類神經網路。Google實驗發現,有別於常規訓練,實驗模型的學習動力在封閉形式下,可完全控制,開發者更可藉此理解模型行為。(詳全文)
Google 立體物件辨識 行動裝置
行動裝置也可即時辨識3D物件!Google釋出辨識模型工作流程Objectron
Google物件辨識模型工作流程MediaPipe增加新的辨識流程Objectron,可即時在行動裝置上辨識3D物件。Google表示,目前成熟的影像辨識技術多半是2D物件辨識,也就是從畫面中,以邊界框(Bounding box)框出2D物件。但如果延伸到3D,就能了解物件的大小、位置和方向,更可運用至機器人、自駕車、圖片檢索和AR等領域。
不過,要從平面影像辨識3D物件仍然有挑戰,比如缺乏訓練資料或多樣性等。為此,Google利用AR來建立3D資料集,並利用自家機器學習工作流程框架MediaPipe,來開發Objectron模型。Objectron可在畫面中,以3D邊界框框出常見的立體物件,並估算其大小、姿態。其中,為提高工作流程效率,系統每隔幾幀才會執行推論。Google也先釋出針對鞋類和椅子的Objectron辨識模型,未來要將辨識類別擴大至更多物件。(詳全文)

Google 量子運算 機器學習函式庫
整合量子運算和機器學習,量子機器學習函式庫TensorFlow Quantum正式開源
Google聯手滑鐵盧大學、X公司和福斯集團,共同釋出量子機器學習開源函式庫TensorFlow Quantum(TFQ)。該函式庫是TensorFlow的擴充,可結合量子運算和機器學習。
TFQ底層整合了TensorFlow和雜訊中等規模量子(NISQ)演算法框架Cirq,其中,TFQ的關鍵功能在於可同時訓練、執行許多量子電路,這是因為,TensorFlow能在電腦叢集中平行化運算,也能在多核心電腦上模擬較大的量子電路。Google指出,未來目標是要讓TFQ能透過Cirq,在真正的量子處理器上執行量子電路,比如Google內部正在開發的Sycamore量子系統。(詳全文)
臺鐵管理局 軌道扣件 影像辨識
夜間人工巡軌有新方法,臺鐵改導入AI自動揪出脫落的軌道扣件
臺鐵管理局聯手交通部運輸研究所,共同開發出軌道扣件缺失辨識系統,透過攝影機和深度學習軟體,來自動辨識鐵軌上的扣件安裝情況,輔助人工巡視作業。
目前,臺鐵軌道扣件巡檢仍採夜間人工目視,但因目視角度和巡檢車車速問題,難以快速進行。於是,臺鐵與交通部運研所合作,選定特定鐵軌區間,來收集訓練影像資料。之後,團隊再以Yolo v3來訓練深度學習模型,來檢查軌道扣件是否脫落。此外,團隊也用GoPro,於夜間巡檢車時速30公里時,錄製70公里的軌道扣件影像,驗證模型辨識準確率為86.7%。雙方指出,未來還要進一步改善模型,最終要達到無人巡檢。另一方面,團隊也開發雲端功能,可透過Google地圖來定位扣件脫落之處,方便進行維修。(詳全文)

Pixel 4 動作感知 Google
解密Pixel 4動作感知關鍵!記錄數百萬次手勢建立雷達解讀ML模型
Google日前揭露自家最新Pixel 4系列手機的Motion Sense技術,該技術讓用戶不需觸碰手機,就能隔空以手勢來控制音樂播放或靜音來電。這是因為,Motion Sense採用Soli短程雷達感測器和特別設計的機器學習演算法,來解讀Soli訊號。
在手機頂端內建Soli天線,可處理時序性訊號,再輸入至Soli機器學習模型,來分類手勢。為訓練這套模型,團隊找來數千名志願者,記錄數百萬個手勢,並配對側錄的雷達訊號,來訓練模型。Google用TensorFlow訓練模型,同時也克服手機低電量的挑戰,發展特殊的訊號處理技術,來解決聲音震動對Soli系統的影響,使其能與周圍的通話元件共存。(詳全文)

模糊測試 基準測試 FuzzBench
把關模糊器品質,Google開源釋出基準測試服務FuzzBench
Google日前開源釋出模糊測試器(Fuzzer)的基準測試服務FuzzBench,要來提供用戶嚴謹的模糊測試,降低採用障礙。模糊測試是一種抓臭蟲技術,透過自動或半自動產生另一個程式的亂資料,來測試程式可能出現的異常狀況。Google內部就用了不少模糊測試器如libFuzzer和AFL等,也揪出了數以萬計的臭蟲。
雖然目前有許多模糊器的研究,但仍難以評估模糊器是否能實際派上用場。因此,Google的OSS-Fuzz團隊建立了FuzzBench,用戶只需不到50行程式碼,就能整合Fuzzer和FuzzBench,可進行24小時的實驗。之後,FuzzBench會根據實驗資料,深入分析並產生報告,來比較不同Fuzzer的效能,包括統計測試,讓用戶了解Fuzzer之間的效能差異。(詳全文)
圖片來源/TensorFlow、Sam's Club、微軟
AI趨勢近期新聞
1. Alphabet生醫研究子公司Verily正打造武漢肺炎分類工具
2. Nvidia研究團隊用AI教機器人拿物品給人類
3. 加州大學柏克萊分校發現新方法,可改善大型Transformer的訓練和推論
4. Amazon自家無人商店科技上市開賣
資料來源:iThome整理,2020年3月
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10