組成,可進行獨特的預測,比如給定小部分的已知物件查詢,DETR可推導出物件與整體影像的關係,可直接平行輸出最終的預測結果。")
臉書將Transformer用來解決電腦視覺任務,發表一套模型DETR。DETR由一系列全局損失(Global loss)組成,可進行獨特的預測,比如給定小部分的已知物件查詢,DETR可推導出物件與整體影像的關係,可直接平行輸出最終的預測結果。
重點新聞(0530~0604)
臉書 Transformer 電腦視覺
臉書發表DETR模型,用Transformer架構來解電腦視覺任務
Transformer是一款新興深度學習模型架構,在序列性任務的表現特別好,常用於自然語言處理(NLP)、語音辨識、增強式學習等領域。而臉書最近發表的影像辨識模型DETR,特別把Transformer架構用來解決電腦視覺任務。
DETR可進行偵測物件和全景影像分割任務,但結構與先前的電腦視覺模型截然不同。DETR由一系列全局損失(Global loss)組成,可進行獨特的預測,比如給定小部分的已知物件查詢,DETR可推導出物件與整體影像的關係,可直接平行輸出最終的預測結果。
臉書解釋,DETR簡化了影像辨識的工作流程,省去不少須手動設定的作業,也不需要特殊的函式庫。經COCO影像資料集測試,DETR達到高階方法(如Faster R-CNN)的預測水準,不過對小型物件偵測仍不夠準確,這也是團隊未來的研究方向。(詳全文)

DeepMind BERT 偏差
DeepMind:句法偏差讓BERT更上層樓
自Google前年發布大型自然語言預訓練模型BERT以來,就成為自然語言處理(NLP)的標竿,即使不了解階級句法結構,也能很好地判斷文法和句法。不過,DeepMind和加州大學柏克萊分校的研究員聯手研究,發現句法上的偏差,可提高BERT的準確度。
進一步來說,團隊採知識蒸餾(KD)方法,透過提取(Distill)語言模型的句法預測,來把句法偏差嵌入BERT預訓練。為了順利做到這一點,團隊先建立了新的預訓練設置,可直接提取KD中遞迴歸類神經網路文法(RNNG)的單字邊際分布,同時也保持BERT的擴展性。後來,團隊利用6個結構預測任務,來測試改良的BERT,表現都比原本的BERT要好,錯誤率可下降2至21%。(詳全文)
OpenAI 自然語言模型 GPT-3
OpenAI釋出1,750億個參數的超大型自然語言模型
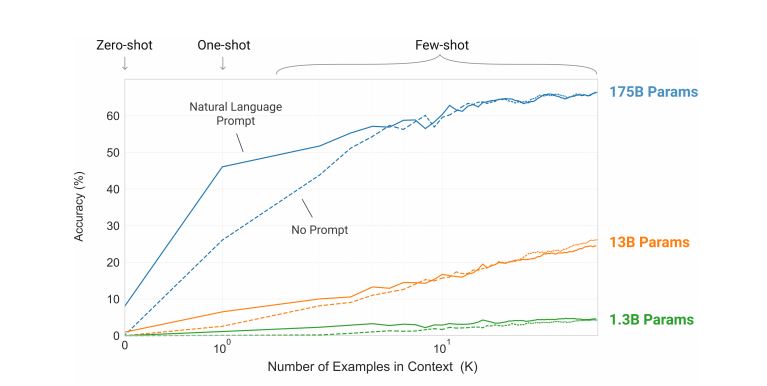
30多位OpenAI研究員日前聯手發表最新研究,也就是一套超大自然語言模型GPT-3,擁有1,750億個參數,而且在一系列的基準測試任務中,比如翻譯、新聞生成、回答SAT問題等領域,都達到高階等級(SOTA)。
OpenAI曾在去年發表GPT-3的前身GPT-2,參數最多也才15億個。這次發布的GPT-3模型,利用近上兆個單字的CommonCrawl資料集和網路文件、維基百科等相關資料,採非監督式方法訓練而成。團隊指出,GPT-3處理任務時,完全不須任何微調或梯度更新,只需要少量與模型交互的文字示例(Demonstration)即可。在NLP測試中,團隊指出,GPT-3在單樣本學習和少樣本學習中表現優異,但對常識推理、句子比較等任務則稍弱。(詳全文)
百度 量子機器學習 Paddle Quantum
百度開源量子機器學習平臺Paddle Quantum
百度日前在自家深度學習開發者大會上,宣布釋出量子機器學習平臺Paddle Quantum,要來加速資料科學家利用量子運算來訓練和開發AI的時間。這款平臺建置於自家深度學習平臺PaddlePaddle上,支援三種量子應用:量子機器學習、量子化學模擬,還有量子組合優化;開發者可以利用這些工具從頭打造量子模型。
百度指出,Paddle Quantum具通用性和擴展性,因為它支援了量子電路模型的變量定義和矩陣乘法,還有一般的量子計算研究。此外,Paddle Quantum還提供一系列量子機器學習模型,為複雜的運算如Gibbs state preparation打下基礎。(詳全文)
Google 聯合分析 個資隱私
不拿走任何資料!Google發表聯合分析技術,兼顧隱私和服務品質
Google利用聯合學習(FL)基礎,發展一套聯合分析(Federated Analytics)技術,可用來改善Google自家鍵盤Gboard和音樂辨識應用的準確度。Google表示,這項技術最大的優點,就是讓使用者的資料留在裝置上,同時工程師也能獲取匯總的資料,來改善服務。
聯合分析原本用來支援聯合學習,讓模型品質評估也能在用戶手機上進行。舉例來說,Gboard工程師可用來評估單詞預測模型的品質,在本地端計算該模型的預測和實際輸入單詞間的差異,並上傳比對結果,透過多個使用者手機上傳的指標,工程師就能了解模型的效能。(詳全文)
Cloud 超級電腦 臺灣AI雲 科技部
自動評估更準確,Google最新NLG自動化指標BLEURT上線
現有NLG自動評估指標只評估表面相似度,Google開發一套可自動衡量句子間語意相似性的指標BLEURT,能達到接近人類註釋的準確性,準確度還比常用的自動指標BLEU高48%。
BLEURT是一個以機器學習為基礎的自動指標,能捕捉句子間語意的相似性。在開發時,Google採遷移學習來解決訓練資料不足的問題,透過BERT的上下文單詞表示法來輔助,以及其他預訓練方法,來提高BLEURT強健性。後來,Google也對BLEURT進行基準測試,在機器翻譯和資料生成文字等任務都超越現有的方法,比應用WMT Metrics Shared Task的BLEU,人工評估分數還要高48%。(詳全文)
微軟 Azure Cosmos DB 吞吐量
微軟Azure Cosmos DB可自動配置預設吞吐量,用戶不必再緊盯流量
微軟更新自家雲端NoSQL資料庫服務Azure Cosmos DB,除了強化和分析服務Azure Synapse的整合,還能自動縮放配置的吞吐量,用戶還可使用自己的金鑰對靜態資料加密。
首先,微軟釋出Azure Synapse Link功能預覽,鎖定混合交易和分析處理,可讓Azure Synapse存取Cosmos DB,以獲取接近即時的分析結果。另一方面,Cosmos DB也將之前預覽的自動模式更名為自動縮放預配置吞吐量,並正式釋出,藉由自動縮放功能,可以在維護SLA的同時,自動快速擴展以滿足突如其來的流量峰值,讓用戶不用監控流量。(詳全文)
大規模預訓練模型 電腦視覺 BiT
Google開源大規模預訓練電腦視覺模型BiT
Google發布一款電腦視覺預訓練模型BiT,透過大規模預訓練,可快速運用其他資料集,來解決電腦視覺任務,而且實驗顯示,這款模型可獲得極佳的Top-5精確度。
首先,Google利用自然語言預訓練模型BERT的方法,來調整預訓練的BiT模型。為微調超參數,Google運用了啟發式超參數調校方法BiT-HyperRule,並利用圖像辨識率和標籤範例數量等高層級的資料特徵,調整參數配置。在實驗上,Google利用ILSVRC-2012訓練和微調的模型,Top-5精確度可達到80%,比之前最好的成果還要高25%。(詳全文)

圖片來源/臉書、OpenAI、微軟、Google
AI趨勢近期新聞
1. 明年Google搜尋將把網頁經驗納入排序依據
2. 運算效能提升20倍,Nvidia新款資料中心等級GPU上陣
3. OpenAI聯手Uber,打造最新搜尋方法Virtual Petri Dish,幫開發者挑選最佳模型
資料來源:iThome整理,2020年6月
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10