
網路視訊會議服務整合AI功能已是大勢所趨,思科、微軟等業者都在持續開發與擴充相關功能,而Nvidia在10月GTC大會上,也宣布推出能夠結合多種AI應用的雲端原生視訊會議軟體開發平臺,稱為Maxine。它不僅提供減噪、更換虛擬背景、即時翻譯等近期常見的特色,也具備了資料壓縮與AI改善畫面品質、臉部自動對準鏡頭等功能。
近年來,幾個主要的雲端視訊會議服務廠商,都在持續強化AI相關應用,例如,思科Webex Assistant(前身為Cisco Spark Assistant,2017年11月推出),他們陸續併購多家公司,也是為了提升他們的視訊會議輔助機制,例如,8月宣布併購BabbleLabs,去年9月買下的Voicea,前年5月併購的Accompany,這些公司都運用了AI技術來提供改善協同作業的解決方案。其他如微軟Teams、Zoom等廠商,也不斷在前端用戶體驗與後端系統當中,擴充AI輔助機制。
身為多項AI軟硬體技術推動者的Nvidia也不甘示弱,在10月的GTC大會期間,突然宣布他們將推出一套基於雲端原生環境所設計的AI 視訊串流平臺,名為Maxine,他們將為開發人員提供雲端原生AI視訊串流軟體開發套件,運用GPU來加速處理,目前已開放先期試用。
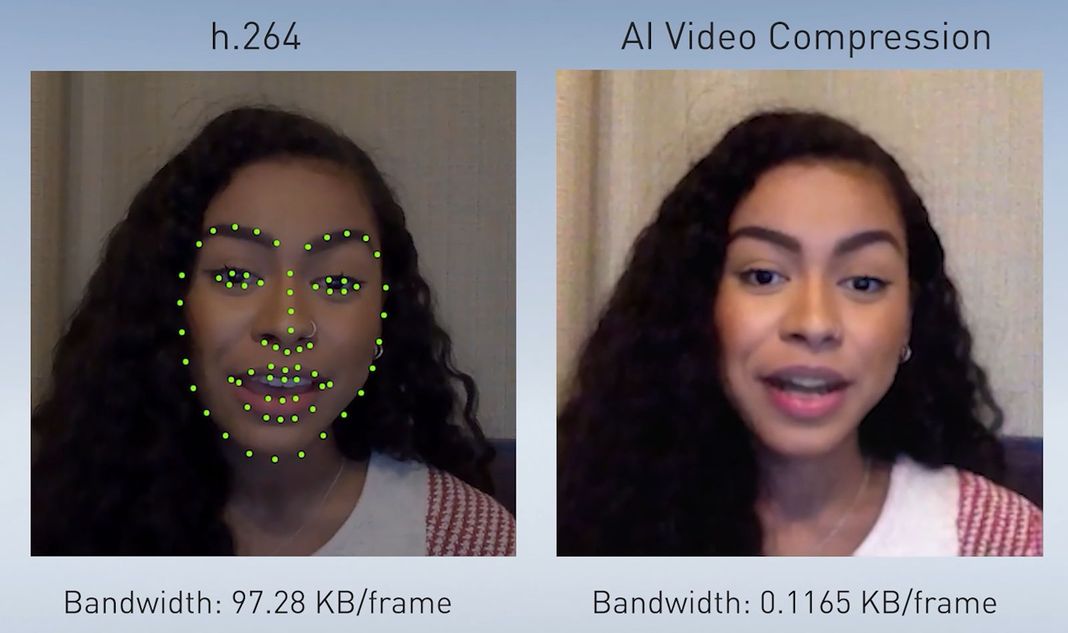
Nvidia創辦人暨執行長黃仁勳表示,首先,他們可透過AI來感知臉部重要特徵,僅傳送特徵變化,在接收器端重新設計臉部動畫(AI Video Compression),這樣的作法可減少10倍網路頻寬;
第二,AI可以重新調整臉部方向,讓你與通話的每個人進行眼神接觸(Face Alignment),你的臉會重新產生,這項應用可讓與會者面部呈現出與每個人眼神接觸的效果;

第三,AI可以根據你所說的話語聲音,來製作擬真的數位分身3D動畫,使其代替你來發言;

第四,AI可以移除背景雜音,提供超高解析度的畫面呈現,提升光線較暗時的清晰度、更換與會發言者的背景,甚至為臉重新打光;
第五,有了Jarvis對話式AI,可以做到即時翻譯,並提供同步出現在畫面底部的隱藏字幕。

他強調,有了Jarvis和Maxine,Nvidia能為現今視訊會議的應用方式,帶來全新變革,建構虛擬臨場參與(Virtual Present)的未來開會形式。
而Maxine這種AI輔助的視訊會議應用,背後倒底是如何運作的?以影像壓縮來說,首先,發話者傳送一個參考影像,就像目前的這類系統通常會運用經壓縮的視訊串流來進行,接著會傳送位於不同地點使用者的眼、鼻、口等周圍的要點(key points)。而在接收端的生成對抗網路(Generative Adversarial Network,GAN)會運用初始影像,以及面部的要點,在GPU上重建後續的影像,因此,在網路上僅需傳送較少量的資料即可。

除此之外,Maxine也將音訊、影片與交談式AI等多種功能,結合為單一工具包,可廣泛支援多種設備的使用。
能讓服務供應商提供超高解析度的影像,以及即時翻譯、背景噪音移除、可感知對話前後脈絡的隱藏字幕,也能運用臉部自動對準鏡頭,並且提供虛擬助理與逼真的替身動畫。
而這些技術應用形式之所以能成形,最主要仰賴的是Nvidia GPU與內建的Tensor Core核心,以及Jarvis這套同時支援語音與文字處理的交談式AI軟體開發套件,同時也運用了Nvidia發展的多種軟體開發套件,像是針對音訊與影片串流可提供高吞吐量的DeepStream,以及用於深度學習推論處理的TensorRT。
至於上述軟體開發套件,何以具備AI音訊、AI影片、自然語言理解等處理能力?Nvidia表示,這些都是他們發展的DGX系統系列整合式AI硬體設備產品(DGX A100),耗費數十萬小時的訓練而來。
而就運作架構而言,Nvidia也特別用了雲端原生(Cloud Native),以及基於雲端(Cloud-based)來形容Maxine,為何他們這麼說?在該公司的新聞稿當中,有一些解釋。他們表示,這套軟體平臺將多種AI微服務執行在Kubernetes叢集,而這些叢集裡面包含了Nvidia GPU,而在這樣的架構下,開發人員可根據即時出現的處理請求,迅速擴充服務規模,使用者可同時執行多種AI功能,並在應用系統可容忍的延遲程度內,保持良好的效能。
對於視訊會議服務供應商而言,他們也能運用Maxine,可透過雲端服務環境提供的Nvidia GPU資源,來執行AI推論工作負載,即可將這些先進的AI功能提供給數十萬個使用者。由於Maxine平臺本身採用模組化設計,因此開發人員可輕鬆選用所需要的AI功能,將其整合到他們的視訊會議解決方案當中。

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06