
臉書AI研究院用Transformer打造出可同時執行7種任務的AI模型UniT,像是自然語言推理、QA、看圖回答、影像辨識等,特別的是,UniT雖以8個資料集訓練而成,但有別於傳統多任務AI的訓練方法,UniT是共用同一套參數,而非以個別任務的參數來微調預訓練模型。
臉書AI研究院
重點新聞(0226~0304)
Transformer 通用AI 臉書
離通用AI更近一步!臉書用Transformer打造熟練7種任務的AI
Transformer架構近年屢屢突破ML天花板,比如BERT創下NLP新里程,ViT證實Transformer取代影像生成網路CNN的可能,甚至OpenAI的DALL·E可從自然語言生成圖像。但這些代表性模型,都只專注於單一或特定型態(如文字與圖像)任務,這不禁讓人好奇:我們能否用一個Transformer模型,來處理不同型態的各種任務?
臉書AI研究院近日就以Unified Transformer(UniT)編解碼器模型來回答這個問題。UniT以不同領域的任務訓練而成,可同時處理7種任務,像是物件辨識、圖像和自然語言推理、自然語言理解等。不過,UniT最大的特點在於共用一套參數,而非像傳統訓練多任務AI的作法,用不同任務參數來微調預訓練模型。
臉書的UniT以傳統Transformer架構打造,每個輸入型態都有其編碼器,之後再接一個解碼器。進一步來說,UniT的輸入型態有兩種:文字和圖像,首先,UniT的CNN骨幹會萃取視覺特徵,再用BERT將文字輸入值編碼進隱藏狀態。接著,Transformer解碼器會用來處理編碼過的型態,最後才將Transformer處理的特徵送到特定任務的頭,來進行預測。臉書團隊用8個資料集來訓練UniT,讓它學會處理7種任務,且經測試,UniT在各任務接表現出色。(詳全文)
.PNG)
Transformer Geoffrey Hinton 類神經網路
如何讓AI更懂一張圖的千言萬語?Google AI大神Hinton:試試融合5種AI的GLOM
獲圖靈獎殊榮的Google AI巨頭Geoffrey Hinton日前發表長達44頁的論文,來描寫他設想的新AI系統GLOM。這個系統融合時下最先進的5種類神經網路,可分辨一張圖像中,部分與整體(Part-whole)的層級概念,目的是要讓模型更會解讀影像或自然語言。
進一步來說,GLOM融合的5種高階AI包括Transformer、神經場(Neural fields)、對比特徵學習、蒸餾和膠囊網路。Hinton指出,心理學證明,人腦是以影像中的部分與整體層級關係來解讀,並對視角不變的空間關係來建模。然而,類神經網路並非如此,因此產生一個難題:一個固定架構的類神經網路,如何分析圖中部分與整體的層級關係,而且是在每張圖都有不同結構的限制下?
他認為,要回答這個問題,單純以相同的向量群,來表示分析樹中的節點即可。在他的構想中,GLOM架構由大量的柱列(Column)組成,也就是一堆堆的自動解碼器;這個柱子可想像成一張圖片中的一個方格,向上延伸出的柱子,柱子可分為數層,每層涵蓋圖片中的一些位置訊息。以一張貓照片為例,假設方格落在貓耳,方格最底層就是貓毛,依序往上為貓耳、貓臉和整隻貓等,以此來推斷圖片中部分與整體的階層關係。
Hinton表示,GLOM的設計能解決過往CNN等網路的缺點,甚至是他自己研發的膠囊網路。要是GLOM真的可行,將大幅改善Transformer類模型產生的特徵解讀力,讓AI更懂語言和影像。(詳全文)
微軟 機器學習模型 錯誤分析
ML模型錯在哪秀給你看!微軟推出ML可視化錯誤分析工具包
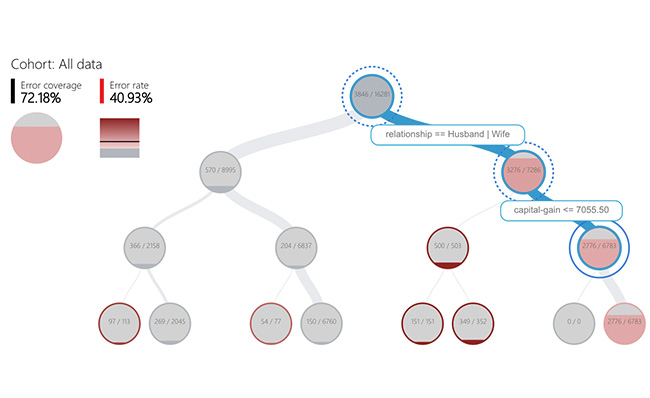
微軟近日推出一套ML模型錯誤分析工具包Error Analysis,可用來描述和解釋ML模型的錯誤。微軟指出,對ML應用開發者來說,在模型部署前先進行嚴格的評估和測試是必要的過程,但要分析、找出模型缺陷,極其複雜。
為簡化這個過程,微軟開發出Error Analysis,主打兩大功能,也就是先找出錯誤率高於Benchmark的資料組(Data cohort),再分析錯誤率較高的原因,讓使用者加以改善。進一步來說,Error Analysis使用決策樹和熱像圖來找出錯誤率較高的資料組,以二分樹狀圖來區分出高錯誤率的特徵,再透過熱像圖進一步分析其中1、2個作為輸入值的關鍵特徵,是如何影響資料組的錯誤率。
接著,Error Analysis用4個方法來分析錯誤率高的原因。首先是資料探勘,來探索資料集統計數字和特徵分布,再來是總體說明,來解釋特徵值如何影響模型預測。第3是細部說明,可根據分析所選資料組的資料點,來視覺化呈現預測錯誤的可能原因,比如缺失值。最後是假設分析,來比較調整後的模型表現。(詳全文)
邊緣運算系統 國際太空站 HPE
邊緣運算系統首次進駐太空站!HPE聯手NASA部署在國際太空站
HPE新推出Spaceborne Computer-2國際太空站邊緣運算系統,可大幅提高太空站的運算能力,也是將邊緣運算系統部署在太空的首例。國際太空站太空人可透過Spaceborne Computer-2,來處理醫學影像和DNA定序等運算,也會分析來自太空感測器和衛星的資料,大幅縮短各種太空實驗時間。
進一步來說,過去在衛星和國際太空站的數百個感測器,資料都得送回地球才能進一步分析,但現在利用邊緣運算,研究員可處理更多機載圖像、訊號和資料,更廣泛了解地面道路的車流量和停車場汽車數量,更準確預測交通趨勢,也可測量大氣中的氣體和污染物、偵測空氣品質等。Spaceborne Computer-2已於2月20日,從地球上發送到NG-15太空站中,將服役2到3年。(詳全文)

AWS 品質檢驗 nbsp; 工業
30張圖片就能訓練完模型!AWS推出工業瑕疵檢測服務
AWS正式發布工業用電腦視覺服務Amazon Lookout for Vision,利用電腦視覺來偵測產品瑕疵,讓製造業品質檢驗工作自動化。AWS這款服務的特點是採用小樣本學習,因此只用少數樣本,就可訓練模型,找出產品瑕疵如裂縫、不規則形狀等。
進一步來說,用戶可將相機圖片發送到Amazon Lookout for Vision服務來辨識異常,找出如產品表面損壞、元件缺失或各種瑕疵,而且,該服務每小時可處理數千張圖片。此外,在模型訓練部分,用戶僅需提供30張正常和異常的圖片作為基準,就可開始評估零件或成品狀態。在分析資料後,Amazon Lookout for Vision還會在服務儀表板或透過即時API發出通知,讓用戶採取適當的後續處理。(詳全文)

解碼器 語音通話 低頻寬網路
如何在低頻寬網路實現高品質語音通訊?Google有解
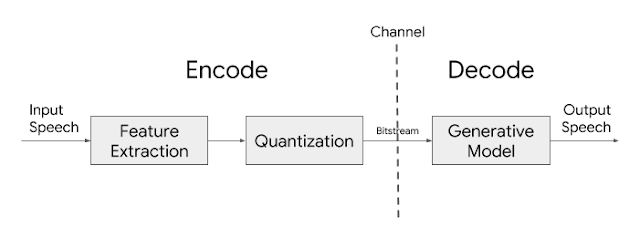
Google利用機器學習技術,開發出高品質低位元率的語音編解碼器Lyra,可讓低頻寬網路的語音通話品質變得更好。Google解釋,數十年來,編解碼器都是媒體應用程式的重要元件,讓需要大頻寬傳輸資料的應用程式,能更有效傳輸資料。但對語音編解碼器來說,位元率越低,語音訊號的清晰度就越差,聲音也就越像機器人。
為解決問題,Google用數千小時的語音,來訓練編解碼器和循環生成模型WaveRNN,打造出Lyra,能高效壓縮、傳輸語音訊號,在低頻寬中支援高音質語音通訊。由於Lyra採WaveRNN,可以較低的位元率在不同頻率範圍平行生成多個訊號,在之後以特定的採樣頻率,結合到單一輸出訊號中。如此設計讓Lyra可在雲端伺服器中執行,還可在中階手機上即時運作,處理延遲約為90毫秒,與其他傳統語音編解碼器相同。(詳全文)
圖片來源/臉書、Geoffrey Hinton、Google、微軟、AWS
AI趨勢近期新聞
1. Google解釋電影照片的AI生成技術細節
2. 戴爾首次在海外設置創新中心,聚焦邊緣運算、AR和資料分析
3. 微軟發表結合硬體與服務的邊緣AI運算平臺Azure Percept
資料來源:iThome整理,2021年3月
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10