在昨天正式發布,這次共有13個組織參與評測,表現亮眼的除了Nvidia DGX SuperPOD,還有Google的TPU v4。")
MLPerf最新訓練評比結果(MLPerf Training v1.0)在昨天正式發布,這次共有13個組織參與評測,表現亮眼的除了Nvidia DGX SuperPOD,還有Google的TPU v4。
圖/ML Commons
ML基準測試套件MLPerf最新訓練評比在6月30日出爐。這次MLPerf Training v1.0的測試中,將近四分之三參與評測企業所使用的硬體,都是以Nvidia的AI產品為基礎,Nvidia本次也以DGX SuperPOD參加評測,分別在8項AI工作負載測試中,都獲得不錯的成績。Google這次則是以近期發布的AI加速晶片TPU v4參加評比,在特定AI模型訓練的任務中,效能表現甚至超越了Nvidia產品評測結果,不過TPU v4還在預覽階段,預計今年才會開始提供GCP客戶使用。
這次MLPerf Training v1.0測試的AI應用類別有8種,除了過去就有的6種應用類別,分別是用於排名與推薦的DLRM、用於NLP的BERT、可在行動裝置上執行的輕量級物體偵測模型SSD、重量級物件偵測模型Mask RNN-T、用於強化學習的MiniGo,以及廣泛用於圖像分類的ResNet-50 v1.5,今年更新增了用於語音辨識的RNN-T與醫療影像分割的UNet-3D,來對各家產品進行效能評比。
今年共有13個組織參與評測,相較於去年來看,今年參與評比的組織更多了。Nvidia資深加速運算產品管理與行銷資深經理Paresh Kharya指出,近年來有越來越多用戶看重MLPerf評比的結果,比如台積電OPC部門主管就曾表示,MLPerf基準測試,就是影響內部決策的一項重要因素。
這次參與評測的組織中,有將近四分之三的企業提交的AI加速平臺,都是以Nvidia產品為基礎,顯示Nvidia在AI加速領域的領先地位。Nvidia這次也以市售的DGX SuperPOD,參加了全部8項AI項目的測試,且在多個項目中獲得最佳成績。不過,Google這次提交的TPU v4,雖然還是預覽版本,但在特定領域的效能表現更優於Nvidia,顯示他們未來將用於GCP的AI加速晶片,對於特定類型的AI應用有其優勢所在。
.png)
大多企業提交了已經商用的產品(Available),部分企業提交的是預覽類(preview)產品,如Google使用的TPU v4,可能幾個月後才會上市,也有組織使用可能長久都不會上市的研究類產品來評測,如中國鵬城實驗室。
Nvidia也提供了更多數據,來說明這次評測的結果。
Nvidia圖表揭露了兩個總評比的指標,分別是模型訓練速度與單一晶片的效能比較。在訓練速度的評比上,訓練時間越短,代表該硬體擁有更好的表現,由此來看,Nvidia DGX SuperPOD在半數的AI應用類別中拔得頭籌,比如花費最久訓練時間的MiniGo類別,Nvidia也只花了16分鐘就完成訓練。但在SSD、ResNet-50 v1.5、BERT與DLRM的訓練速度評比上,Google TPU v4取得了更好的成績,換句話說,TPU v4參與的6個AI應用類別的評比中,就有4種類別的表現優於DGX SuperPOD。
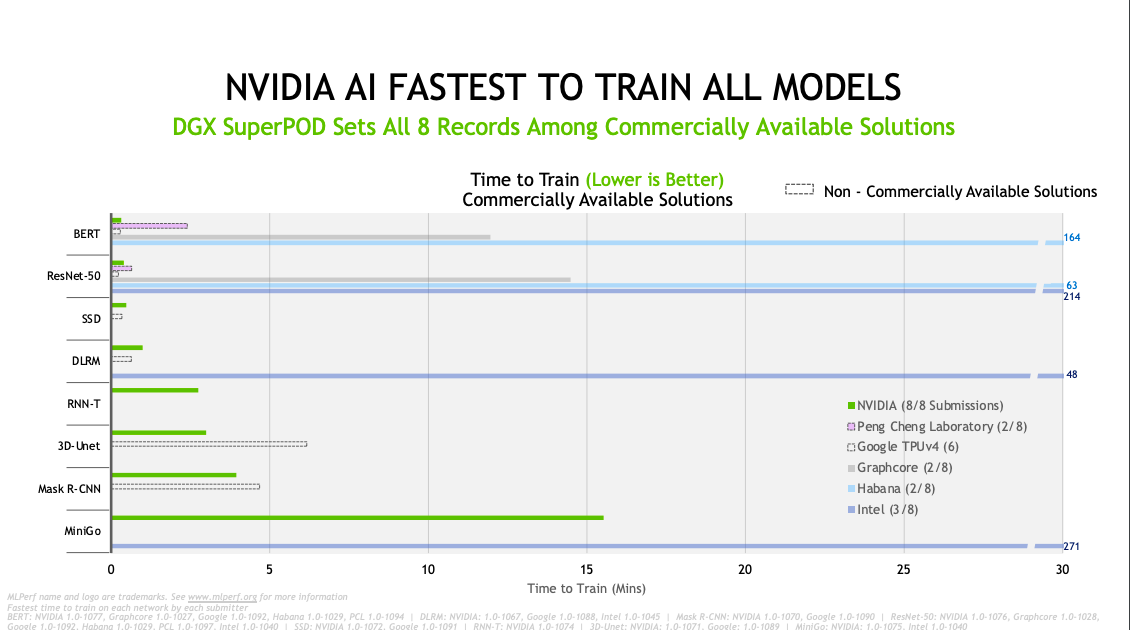
不過,由於各家企業的產品配置不同,使用核心處理器的數量也不同,因此在效能評比上,單一晶片的效能也是一大評比指標。Nvidia DGX SuperPOD是以A100組合而成,若以A100為基準來比較其他AI晶片效能,可以發現A100在大多AI應用中,都具有穩定的高效能表現,單一晶片效能更是Graphcore或Habana的2~7倍以上。而Google尚未上市的TPU v4,則在其中3項應用中取得更好的表現,分別是SSD、ResNet-50 v1.5、DLRM。
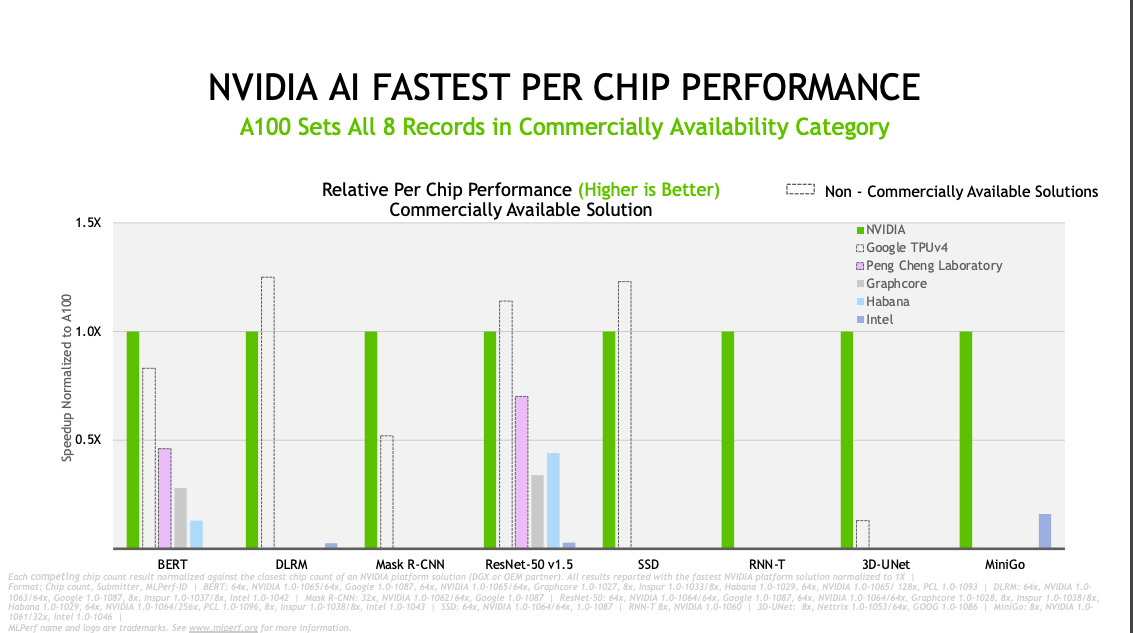
Google的TPU v4也非第一次參加評比。去年Google就曾經以TPU v3與v4提交MLPerf測試。當時的評測結果,TPU v4平均效能比TPU v3提升2.7倍,最大的效能差異是用於訓練Mask R-CNN,TPU v4的效能是TPU v3的3.7倍。
DGX SuperPOD今年表現更進步,Nvidia持續精進GPU產品效能
去年,Nvidia同樣以DGX SuperPOD參與評測。若以Nvidia去年6種AI應用評測的成績,來比較兩年來產品效能的差異,可以發現無論是DGX SuperPOD或是單一晶片A100的效能表現,幾乎在每個AI應用上都有顯著成長。比如DGX SuperPOD今年用於訓練DLRM的效能,就達到去年的3.5倍之多,A100用於Bert訓練的單一晶片效能,也達到去年的2倍以上,顯示Nvidia的同一種產品,也隨著時間不斷進步、優化。
Paresh Kharya指出,效能提升的原因,包括Nvidia透過軟體套裝CUDA Graphs,消除過去GPU與CPU溝通遇到的效能瓶頸,以及在大規模測試時使用Nvidia SHARP,來整合網路交換器中的多項資料傳輸作業、減少網路流量與等待CPU處理時間,其他還有增加記憶體頻寬等做法。
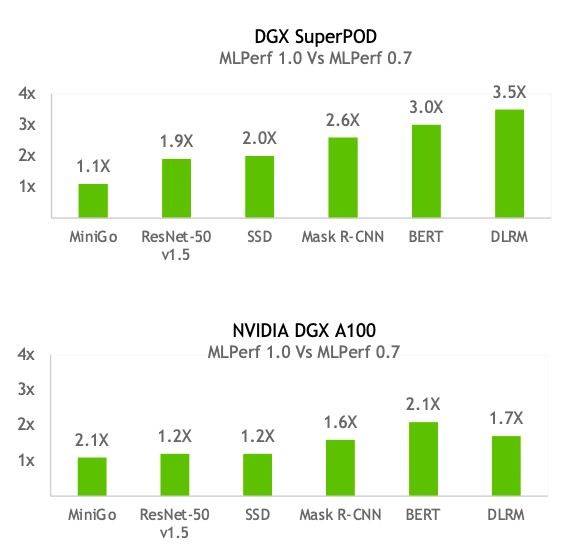
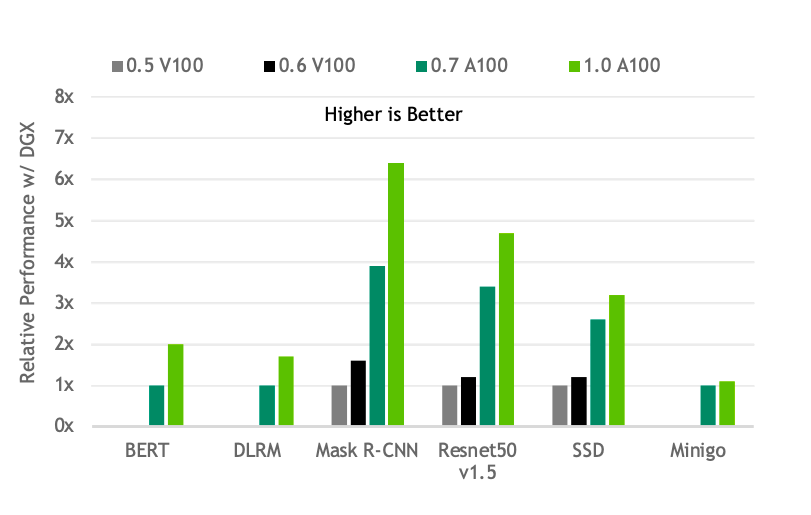
Paresh Kharya也根據Nvidia歷年評測結果提出一項數據,指出從MLPerf訓練評比推出至今不過2.5年,Nvidia GPU的效能已經是當時的6.5倍,且在每一種AI應用的效能表現都有長足進步,幾乎以摩爾定律的兩倍速度在成長。他也強調,帶動效能快速成長的原因,除了仰賴硬體技術的進步,「Nvidia擁有完整的軟體堆疊來加速模型運算,也是一大關鍵。」
至於許多用戶都會關心的產品價格,為何沒有在MLPerf中進行性價比的評比?Paresh Kharya指出,MLPerf評測的目的,是為了展示了各種AI平臺和許多創新AI系統的效能,並非價格的比較。而且,參與MLPerf評比的產品從入門級到超級電腦皆有,產品價格變化大,加上各家企業會搭配軟硬體推出不同的解決方案,產品金額並非MLPerf評測的焦點。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
