
Google團隊打造一款機器人控制系統Performer-MPC,包含Transformer架構,可即時導航機器人,找出最佳路徑和避障,延遲為8毫秒。
重點新聞(0303~0309)
電腦視覺 Transformer 機器人導航
Google用Transformer模型來即時導航機器人
Google最近揭露一款控制系統Performer-MPC,以Transformer架構為基礎,可用於機器人上,讓機器人成功在密閉空間中即時導航、避開人類和障礙物,延遲僅8毫秒。進一步來說,Performer-MPC是一款端到端可學習的機器人系統,包含了基於Python函式庫JAX的可微分模型預測控制器(MPC),以及負責導航任務的Transformer編碼,可用來適應複雜的社交場景,不需人工介入、撰寫規則。Performer-MPC系統還有個重要元素,也就是構成Performer架構的可擴展Transformer模型,它具備線性空間和時間複雜度注意力模組,可讓機器人部署更有效率,實現8毫秒延遲。
Google指出,儘管經過數十年研究,機器人還是難以在狹窄空間中安全移動,而近年,Transformer在不少真實世界的機器學習問題中已有大幅進展,比如多模態架構可讓機器人用Transformer語言模型,來進行高階規畫,且近期以Transformer對機器人進行策略編碼的研究,也開啟機器人於現實世界導航的新契機。雖然,Transformer這種大型模型部署在機器人上,會遭遇延遲挑戰,且注意力機制耗費運算成本,研究者不得不在模型表現和運算成本間取捨、對模型剪枝。
但Google還是開發Performer-MPC,來測試Transformer能否讓機器人在狹小空間中,順利導航和避障。Google選定一款配有3D光達鏡頭和深度感測器的輪式機器人,並部署830萬參數、延遲8毫秒的Performer-ReLU變形模型,來執行導航任務。他們發現,在這個配置下,機器人可在狹窄場景,比如轉角死角處等,成功避開行走的人類,也能在不同障礙物間找出最佳路徑,成功穿越。Google表示,這項實驗證明,用Transformer架構設計具注意力機制的機器人控制器,是可行的。而且,百萬參數的Transformer架構與毫秒級推論延遲,能讓機器人有效率學習、作出適當的反應,更重要的是,該學習系統還能泛化,適應不同環境。(詳全文)

司法院 語音辨識 國民法官
司法院法庭中文語音辨識系統正式上線,準確率超過9成
為讓法庭程序更順暢,司法院開發一款法庭中文語音辨識系統,來加速法庭筆錄作業。司法院表示,該系統用過去1千多萬筆裁判書、180萬筆開庭筆錄來訓練AI辨識系統,平均準確率達92%,且能辨識大多數法律專有名詞。
這個語音辨識系統可用於逐字稿作業,也整合了法院審判筆錄和數位錄音系統、錄影回放系統和影音環控系統,來簡化過去書記官需聽、理解再騰打逐字稿的過程。簡單來說,該系統可在開庭過程中,即時產出逐字稿筆錄,就算有問題,也能調閱特定錄影段落來確認;該系統已於1月正式上線。
司法院也指出,由於國民法官制度採連日連續進行制,審理程序一結束就得評議,行程緊湊,而語辨系統可即時產出筆錄、呈現法庭內發言內容,評議時也能搭配回放特定錄影段落,來加速評議過程。該系統已部署於全國21間地方法院的國民法官法庭,除國民法官適用的重大刑事案件外,司法院也打算讓一般刑事案件使用語辨系統,來產出即時筆錄。(詳全文)
資料集 Google搜尋 Dataset Search
Google搜尋再優化,新添資料集搜索引擎
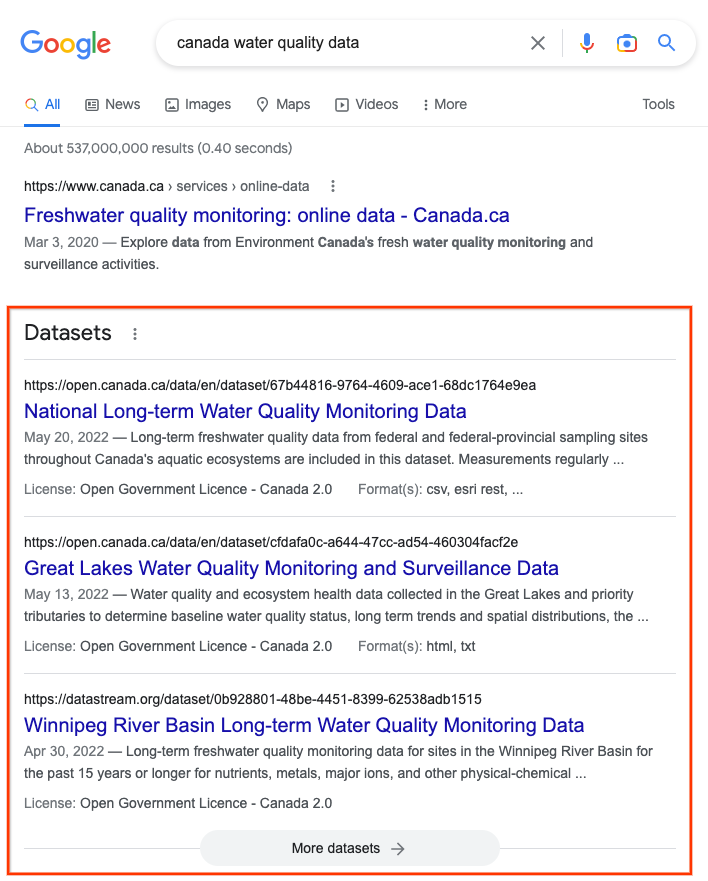
Google推出一款新搜尋引擎Dataset Search,使用者輸入關鍵字,就能搜尋相關資料集,可用來訓練或測試AI模型。這款資料集搜尋引擎,可查找1萬3千多個網站中的4,500萬筆資料集,這些資料集涵蓋多種學科和主題,也包含政府、科學、商用等領域。Dataset Search會顯示資料集的基本資料,也會預覽資料集概況、給出不同頁面的連結,如GitHub、Kaggle等。
Dataset Search主要檢索網路上含schema.org結構化數據的資料集頁面,因為schema.org的詮釋數據,可讓作者用來描述資料集特性和關鍵元素,如下載格式、授權方式等。若使用者希望自己建立的資料集能被Dataset Search納入,首先要確保自己發布的資料集能容易搜尋,且要說明其他人可以如何使用該資料集。特別是要確保描述資料集的網頁,具有機器可讀的詮釋數據。(詳全文)
Brave 生成式AI 搜尋摘要
Brave搜尋引擎自建生成式AI,根據網頁結果摘要更即時
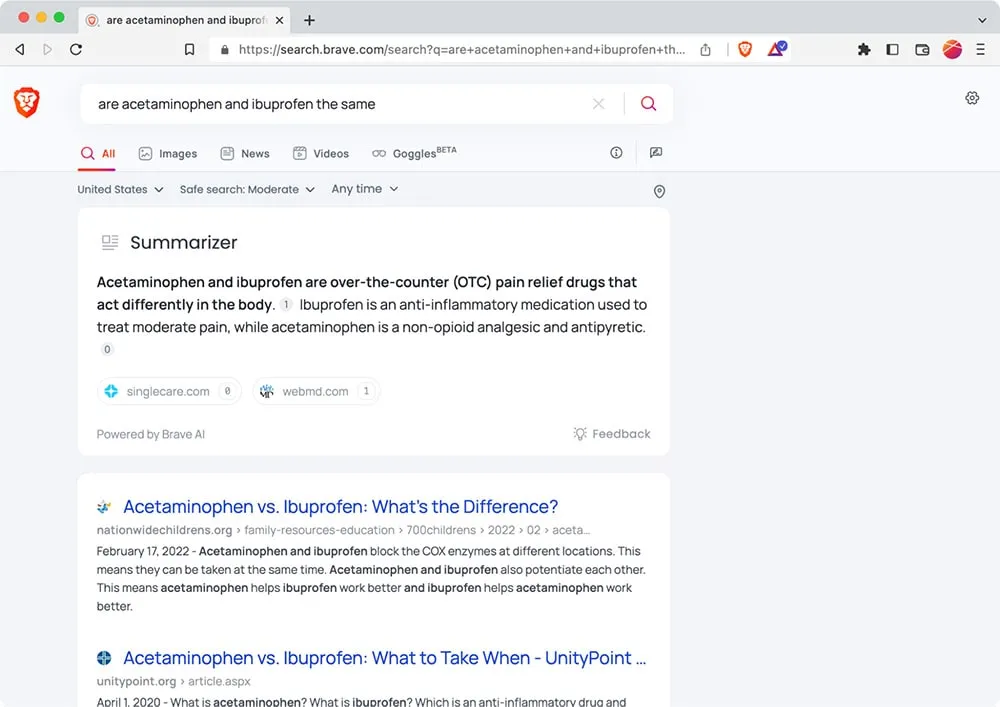
訴求高隱私安全的瀏覽器Brave也開發生成式AI系統Summarizer,來優化自家搜尋引擎,能總結搜尋結果,摘要旁也會列出資料來源,方便用戶查證。
Summarizer由Brave搜尋團隊開發,由三大語言模型組成,這些語言模型分別負責不同任務,首先是問答模型,會嘗試從文字片段中擷取具體答案,之後,Brave搜尋會利用一組零樣本分類器,過濾掉仇恨言論、粗鄙用詞和垃圾訊息等文字,最後交由摘要模型處理,來重寫並刪除重複的文字,保持語言一致性和可讀性。Summarizer給出的答案,完全基於網頁搜尋結果,因此能給出當日事件的結果,也不會產出未經證實的結論。(詳全文)
Meta 生成式AI WhatsApp
Meta成立生成式AI開發團隊
Meta執行長Mark Zuckerberg日前宣布要成立生成式AI開發團隊,來發展文字、圖片、影像等強化技術,改善旗下WhatsApp、Instagram和Messenger等服務。Zuckerberg指出,這個新部門將聚焦生成式AI,短期目標是要開發創意性的表現工具,長期目標則是開發可多方協助使用者的「AI人物」。在微軟、Google和OpenAI等相繼發表AI對話機器人後,AI成為Meta最重要的任務,團隊最近也發布AI大型語言模型LLaMA,並預告要開源LLaMA模型,來供AI研究社群進行不同領域研究。(詳全文)
Nvidia 串流影片 解析度
Nvidia用AI強化串流影片解析度
Nvidia在GeForce RTX 40與30系列最新的GeForce Game Ready驅動程式中,加入影像超級解析度(VSR)功能支援,使用者只要用微軟Edge 110.0.1587.56或Google Chrome 110.0.5481.105以上版本的瀏覽器,就能將瀏覽器上低解析度的串流影片,提升到4K解析度。
Nvidia解釋,由於串流影片是以區塊為單位來壓縮,因此會發生塊狀壓縮失真,若用傳統畫質提升演算法,反而會讓塊狀壓縮失真更嚴重。因此,RTX VSR技術透過邊緣偵測和特徵銳化,來解決問題。這是一個深度學習方法,Nvidia先用不同壓縮程度的影片來訓練模型,模型了解低解析度影片的壓縮失真類型後,就能從輸入的低解析度影片影格,預測目標解析度的殘差圖像,再將殘差圖像疊加到經Bicubic解析度提升演算法處理的影格,來校正假影錯誤和銳化邊緣,來產出高解析度影像。(詳全文)
IBM 大型主機 z/OS
IBM大型主機作業系統z/OS將擁抱AI
IBM預計在2023年第三季推出大型主機作業系統更新z/OS 3.1,該版本的一大更新重點,是要在作業系統融合AI和資料分析解決方案,來讓z/OS應用也能有智慧自動化與大規模加速推理功能,在z/OS 3的混合雲架構中整合AI功能。
進一步來說,z/OS 3.1的工作量管理程式(WLM)將有AI加持,能預測即將發生的批次處理工作負載,還能採取相對應的系統最佳化措施。同時,新版本也會支援AI解決方案,讓企業用戶在z/OS上執行應用程式時,能獲得低延遲的AI功能。另一方面,IBM也希望z/OS能進一步支援企業混合雲策略,因此加入z/OS容器擴充(zCX),強化容器化Linux工作負載效能和安全性,還要強化程式語言COBOL和Java的互通性。(詳全文)
微軟 Bing Chat 語氣
微軟Bing Chat加入3種語氣風格
微軟快馬加鞭更新Bing聊天機器人,近日已在Bing Chat中加入三種語氣風格,來供使用者選擇。微軟在2月底時,就多次預告要開發語氣調整功能,來解決Bing Chat時而情緒化、時而放肆乖張的發言問題。
微軟網頁服務主管Mikhail Parakhin說明,Bing Chat測試用戶可看到Bing Chat模式選擇器,也就是一個3階段的滑鈕設計,提供「精準」、「創意」及「平衡」三種風格。其中,「精準」風格可提供更事實導向的答案,「創意」則會給出較長、類似聊天的答案,比較有趣,但也可能包含較多錯誤。(詳全文)
圖片來源/Google、Brave
近期AI趨勢新聞
1. OpenAI針對付費用戶推出ChatGPT API和Whisper API服務
2. 小米展示新AR眼鏡,具變色鏡片、支援手勢控制
資料來源:iThome整理,2023年3月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12

2026-02-10


2026-02-06