微軟
重點新聞(0915~0921)
微軟 Kosmos-2.5 多模態
生成排版文件也可以!微軟發表多模態模型Kosmos-2.5
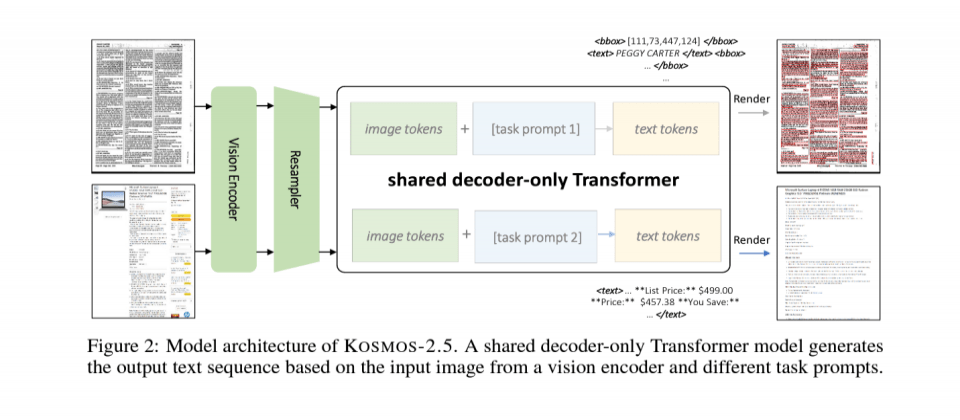
最近,微軟發表一套多模態模型Kosmos-2.5,可完成2項文字任務,一是生成具排版空間的文字區塊,二是產出結構化文字,並以機器可讀的Markdown格式呈現,保留排版和風格。這個Kosmos-2.5包含ViT視覺編碼器和Transformer解碼器,並用大量包含文字的圖片訓練而成,如PPT簡報、arXiv論文、README和HTML等,因此模型具空間意識,可理解文字區塊在排版中的位置,也能理解文字內容。
就生成過程來說,Kosmos-2.5會先產生文字區塊,也就是將文字區塊的座標分配到圖片中,這意味著模型更能理解文字區塊在圖片中的意義,能更準確產出結構化、連貫的文字描述。再來,模型會以機器可讀的Markdown格式,來產生結構化文字內容,包括原本的排版資訊和風格。
團隊指出,Kosmos-2.5為文字圖片理解提供了統一的架構和介面,適用於各種應用場景。比如,它可作為單一模型進行微調,用於資訊抽取、排版偵測和分析、視覺問答、螢幕截圖理解、UI自動生成等文字圖片理解任務。再來,Kosmos-2.5也能與強大的大型語言模型相容,比如GPT-3.5或GPT-4,並以模型產出的結果,來強化LLM的文字圖像理解能力。微軟表示,Kosmos-2.5統一的模型介面大大簡化了下游任務的訓練,也能讓模型有效遵循指令。(詳全文)
蒸餾 Google 小模型
Google開發逐步蒸餾技術,小資料小模型也能打敗LLM
為解決模型大小和訓練資料收集成本間的權衡問題,Google發展逐步蒸餾(Distilling Step-by-Step)方法,可用比一般方法少得多的資料,訓練用於特定任務的小模型,效能還比少樣本提示語言模型要好。這個逐步蒸餾法是要從LLM中,擷取有用的自然語言解釋,亦即LLM中間的推理步驟,並用這些解釋更有效地訓練小型模型。因此,逐步蒸餾的第一步驟,是從大型語言模型中擷取解釋,由開發者提供少數範例,如問題、中間的解釋和答案,引導大型語言模型對新的問題產生相對應的解釋。第二階段是利用第一階段取得的解釋訓練小型模型,小型模型學習由大型語言模型生成的中間推理步驟,能更好地預測答案。
團隊用5,400億參數的PaLM模型,再以T5作為特定任務的模型,實驗在不同自然語言處理任務的表現。透過逐步蒸餾法,使用較少的訓練資料就能超越標準微調方法的效果,甚至僅擁有2.2億參數的T5模型,在e-SNLI資料集表現就可超越5,400億參數的PaLM大型語言模型。(詳全文)

AFS 台智雲 LLM
台智雲揭企業級LLM服務新進展,新添繁中優化的Llama 2模型
繼今年5月發表企業級大型語言模型服務AFS後,華碩子公司台智雲日前再揭新進展,在AFS中納入更多模型,包括以繁中資料強化的FFM-Llama 2,預計9月底上線。進一步來說,AFS全名為AI Foundry Service,主要有2種大型語言模型的部署和推論服務,即AFS Cloud和AFS Appliance。其中,AFS Cloud為雲端託管服務,企業可透過API來使用訓練好的LLM,AFS Appliance則是私有雲/地端部署服務,企業可下載大型模型到地端使用。
這次,台智雲在AFS的預訓練模型庫中,新添以繁中語料優化的FFM-Llama 2模型,包含70億參數、130億參數和700億參數三種版本,以及Meta原本的Llama 2、Code Llama等開源模型,此外還有先前發布的FFM-1(含7B、176B版本)、BLOOMZ(含7B與176B版本)以及Embedding等模型來供用戶選擇。
另外,台智雲在AFS中還新添新功能,比如能提高訓練效率的LoRA(Low-Rank Adaptation),特別適合資料量不多的企業使用者,預計10月上線FFM-Llama 2、Meta Llama 2和FFM-BLOOM系列支援LoRA。另一個新功能則是BitsAndBytes,結合了LoRA和模型縮小技術,有利於模型部署於運算資源有限的裝置。(詳全文)
蛋白質 EvoDiff 序列空間
可設計自然界所有蛋白質!微軟開源AI新框架EvoDiff
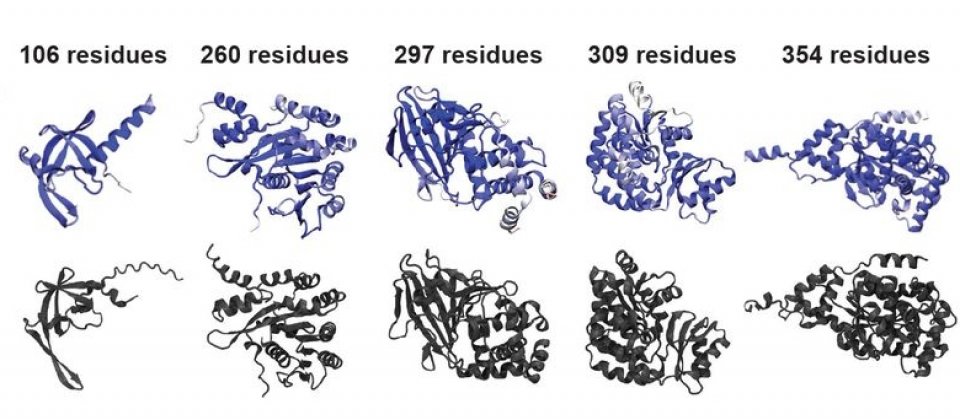
微軟開源通用擴散模型框架EvoDiff,兼具處理大量、多元資料的特性和擴散模型的控制能力,在序列空間中能以可控制的方法生成蛋白質。用EvoDiff訓練的模型,能生成多樣化且結構合理的蛋白質,甚至能生成以結構為基礎的模型無法生成的模型,具通用性。
這個EvoDiff框架,結合進化與擴散兩個方法,用進化規模的蛋白質資料,來建立擴散模型。所謂進化規模,是指涵蓋大規模進化歷史,足以反映蛋白質長時間進化的資料,可讓模型在探索和設計新蛋白質時表現更好。使用EvoDiff框架訓練的模型,能生成符合現實且多樣化的新蛋白質,包括在序列空間生成,在生物學和疾病中都有非常重要作用的無序蛋白質(Disordered Protein)。(詳全文)
輕量化 GAN 低階裝置
Google輕量化臉部編輯GAN模型,低階手機也能即時生成
Google針對生成對抗網路(GAN)的高運算複雜度提出新解方,將原本需要在伺服器執行的臉部編輯模型輕量化,改良為可在手機執行的少樣本臉部風格模型MediaPipe FaceStylizer,提供高品質臉部圖片生成。
MediaPipe FaceStylizer包含臉部生成器和臉部編碼器兩個主要元件。臉部編碼器的主要功能是生成對抗網路反轉,將圖像映射到生成器的潛在碼中,來產生圖片。為最佳化生成器,團隊特別設計損失函式,從一個複雜的StyleGAN模型,提煉出一個更輕量的生成器BlazeStyleGAN,不僅容量小、執行快,生成的圖片品質也很高。
經測試,當輸出解析度為1024x1024,BlazeStyleGAN-1024可減少95%運算複雜度,且輸出圖像品質與StyleGAN-1024模型沒有明顯差異。甚至,BlazeStyleGAN-256和BlazeStyleGAN-512在所有具GPU的裝置上都能即時運算,在更高階手機的執行時間甚至不到10毫秒。BlazeStyleGAN-256還可以在iOS裝置上以CPU即時生成結果。Google將透過MediaPipe平臺發布MediaPipe FaceStylizer。(詳全文)

創作 YouTube Create 編輯
YouTube推出AI內容編輯器
影音平臺YouTube日前推出一款AI編輯工具YouTube Create App,能用來精準編輯和剪輯、自動配音、上字幕和過場。特別的是,YouTube Create 還將測試一個新功能Dream Screen,使用者只需輸入一個想法,就能新添AI製作的短片或圖片至自己的影片。舉例來說,使用者可輸入「我想現在就在巴黎」,App就會合成包含使用者在巴黎的影片或圖片。
這個App還會有個生成式AI功能,來根據發燒主題和觀眾偏好,來產生主題點子和影片大綱給使用者。此外,App也有個AI驅動的音樂推薦功能,能根據使用者輸入的影片描述,來推薦合適的背景音樂。另一方面,使用者也能開啟外語自動配音功能。YouTube表示,這個功能是要讓使用者更容易創作,特別是對第一次發片的使用者而言。(詳全文)

Stability AI 音樂生成 聲音
跨入聲音領域,Stability AI發表文字生成音樂工具Stable Audio
繼推出文字生成圖像模型Stable Diffusion後,Stability AI日前發表文字生成音樂模型Stable Audio。該模型由Stability AI內部的生成式聲音研究實驗室Harmonai開發,利用AudioSparx提供的80萬個聲音檔進行訓練,涵蓋音樂、音效、各種樂器,以及相對應的文字描述等,總長超過1.9萬個小時。
Stable Audio與Stable Diffusion一樣,都是基於擴散的生成模型。Stability AI指出,一般的聲音擴散模型通常是在較長聲音檔案中隨機裁剪的聲音區塊進行訓練,可能導致所生成的音樂缺乏頭尾,但Stable Audio架構同時基於文字,以及聲音檔案的持續及開始時間,讓模型能控制所生成聲音的內容與長度。此外,利用最新的擴散取樣技術,Stable Audio模型在Nvidia A100 GPU上以44.1 kHz的取樣速度,不到1秒就能渲染95秒的立體聲。目前,Stable Audio提供免費與Pro付費版。(詳全文)
Bard Extensions 聊天機器人 生成式AI
能跨服務回答問題了!Google發表Bard Extensions
Google日前發表英文版的Bard Extensions,也就是Bard聊天機器人的外掛,能從使用者每天使用的Google服務中尋找答案,或替使用者進行規畫。這個新外掛可用於Gmail、Docs、Drive、Google Maps、YouTube、Google Flights和Google Hotels等。舉例來說,若使用者要規畫大峽谷之旅,可在單個對話中,要求Bard自Gmail中找出適合每個人的日期,搜尋航班與飯店資訊,於Google Maps上列出到機場的路線,或列出大峽谷各種活動的YouTube影片。
儘管Google在Brad的隱私聲明中,宣稱會蒐集使用者的Bard對話、相關產品使用資訊、位置資訊及意見,但對於Bard Extensions,只要涉及Workspace中的 Gmail、Docs與Drive服務,Google都承諾相關內容不會經過人類審查員,也不會被用來訓練Bard模型或作為遞送個人化廣告的參考。(詳全文)

圖片來源/Google、微軟、YouTube
AI近期新聞
1. DALL·E 3文字轉圖像模型將於10月登場,可利用ChatGPT協助描述
2. 發展腦機介面裝置的Neuralink,開始接受人類大腦植入臨床試驗申請
3. 甲骨文整合臨床數位助理與EHR,擴大醫療AI應用場景
資料來源:iThome整理,2023年9月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-12

2026-02-10


2026-02-10

2026-02-06