雲端時序資料庫服務Timescale不僅可用於儲存和查詢時序資料,現在也逐步拓展支援人工智慧領域,透過新增的Timescale Vector功能,官方採用近似最相鄰搜尋(Approximate Nearest Neighbor,ANN)技術,有效加速數百萬向量的搜尋。
而且由於要滿足不同應用場景的需求,Timescale Vector還提供多種索引演算法,包括受到DiskANN演算法啟發的新型索引外,還有HNSW(Hierarchical Navigable Small World)與IVFFlat(Inverted File with Flat Vector Indexing)。這些新的技術加入,使得Timescale成為多功能且高效的資料庫解決方案。
大型語言模型成為推動部分人工智慧應用程式發展的基礎,企業逐漸在其應用程式中整合人工智慧功能,而向量嵌入更是這波人工智慧熱潮的核心技術。向量嵌入將詞語和短語的語義資訊數學化,以數值向量的方式表達語義,官方提到,這樣的技術在搜尋應用中特別有用,因為允許基於語義進行搜尋,因此即便查詢和資料庫中的詞彙不完全相同也沒問題。
向量嵌入是生成式人工智慧技術的核心,可用於查詢相關的資訊,並將其作為上下文傳遞給大型語言模型,以強化大型語言模型的輸出。因此不少資料庫皆開始資源向量搜尋功能,而這也包括熱門的時序資料庫Timescale,推出向量搜尋功能Timescale Vector。
Timescale Vector是一個專門針對人工智慧應用的資料庫擴充功能,其以PostgreSQL為基礎運作。該工具針對向量資料最佳化,使得開發人員可以更快速且有效地執行近似最相鄰搜尋。ANN僅是一個廣泛的搜尋框架,專門用於大型高維資料集中,尋找一個點的最近鄰居,而Timescale Vector提供了多種索引演算法,來實現ANN搜尋。
Timescale Vector除了提供受到DiskANN演算法啟發的新型索引方法之外,還提供了PostgreSQL資料庫向量類型擴充功能pgvector中的HNSW與IVFFlat演算法。不同的演算法具有不同的優點和限制,Timescale Vector針對不同場景提供豐富的演算法,供開發者依據需求選用。
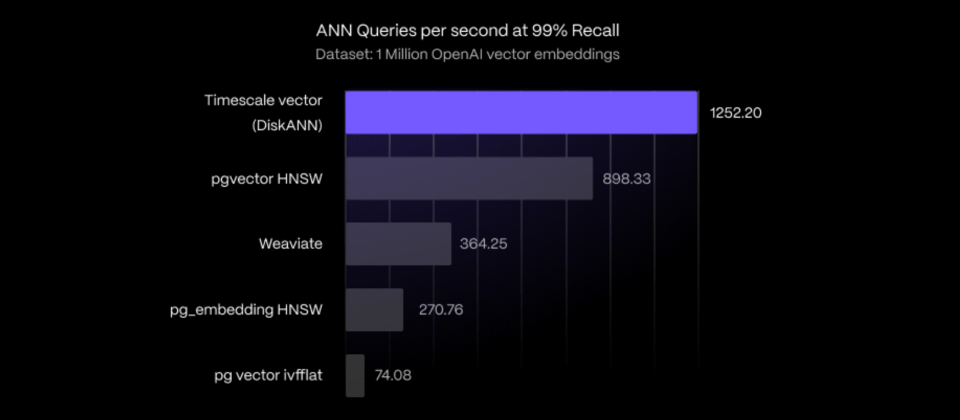
根據基準測試,對100萬個OpenAI向量嵌入執行近似最相鄰搜尋時,Timescale Vector的新索引效能比其他專用向量資料庫和現有PostgreSQL索引方法高出243%,查詢精確度達99%。
而且由於Timescale Vector索引提供了量化向量功能,能夠節省儲存空間達到10倍。量化是一種簡化向量資料的技術,目的是要減少儲存空間和加速查詢,在Timescale Vector中啟用量化功能,可讓開發者在保留相對高查詢精準度的同時,大幅減少索引大小,對於資源有限或是需要高效運作的應用非常有用。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10