
酷澎
2019到2022年,全球受到疫情籠罩,線上商務市場大幅拓張。這段期間,位居韓國電商領導地位的酷澎其年營收從臺幣2千億元,急速成長到6千6百億元。極其龐大的業務規模擴張,使他們持續升級數據基礎建設。
這個基礎建設自2019年的大數據平臺擴張。不過,他們不再叫它「大數據平臺」,而是「數據平臺」──這意味著,不管數據大小,只要可以用來輔助決策,都會透過這個平臺處理、輸出。
截至2022年,這個PB級數據平臺一天執行超過5,000個任務,使用超過70個來源的數據。從工程師、商業分析師、高階主管、外部供應商和外部廣告主,超過50個團隊使用數據平臺。甚至,酷澎預期,此平臺未來處理數據量還會再增加數倍,就算目前平臺足以支援高時效性、高並行性的PB級數據處理,他們仍不斷升級數據處理流程,為未來平臺擴充做準備。
靠通用擷取框架來支援高速、多元、大量數據處理
酷澎數據平臺的架構主體分為擷取和分析類大平臺。擷取平臺由網頁日誌紀錄、串流數據架構及通用數據擷取框架組成,從超過70種來源擷取數據。數據平臺會自動化調度(Orchestrate)這些數據的儲存和處理程序,期間套用資安及數據品質框架。接著,數據會匯入由大數據平臺、顧客體驗分析平臺及機器學習平臺構成的分析類平臺,依照不同使用需求進一步處理數據,再輸出到實際使用這些數據的系統中。
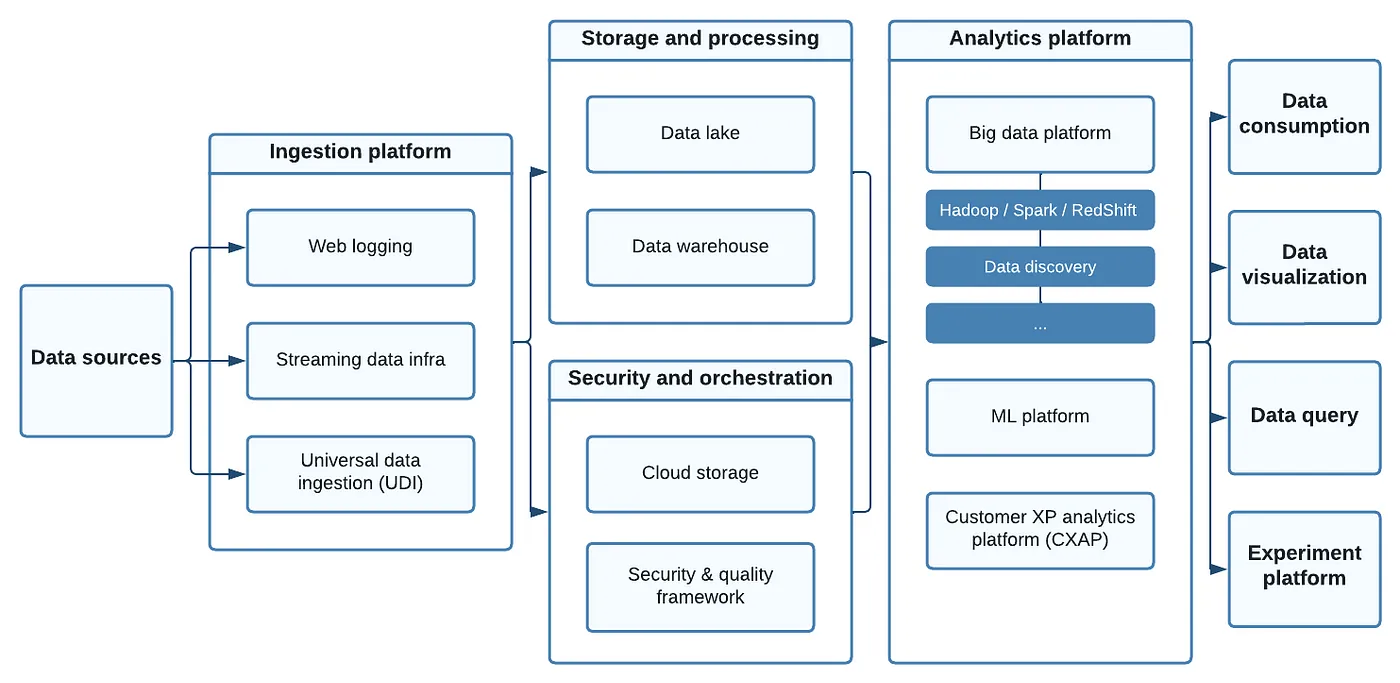
酷澎2022年數據平臺架構
酷澎數據平臺架構中,數據擷取層從超過70種數據源擷取數據,經過儲存、處理、資安及調度等程序,將數據輸入到數據分析平臺。分析平臺會再依據各式數據應用需求進行進階處理,再輸出到串接於平臺的不同系統中。圖片來源/酷澎
由於數據來源眾多,傳統手動建置個別數據流程(Date pipeline)的作法會導致管理及維護困難。酷澎做法是,自行打造一個通用數據擷取(UDI,Universal Data Ingestion)框架,能全自動化擷取資料、適用於所有數據源,且數據使用者可以不仰賴數據工程師,自行調整數據擷取設定。
UDI框架設計強調可以處理多元、高速、大量的數據。為了支援多元數據來源,酷澎將UDI框架設計為一個Hadoop的外掛框架,新增數據源時,只要重複套用同一框架便能完成,既不需要撰寫大量程式碼,更壓低了新增流程的成本。
酷澎還設計了各式自動化流程,以實現高速處理大量數據。例如,擷取數據時,此框架會自動化檢查數據擷取過程符合資安協定、自動化過濾數據,只存取必要欄位。批次擷取數據時,會自動評估並設定每批數據量,控制在有效率但安全的範圍內。
為了處理大量數據,酷澎將數據湖建立在AWS S3環境,以支援大量平行擴充。數據查詢及處理也使用各式支援大量數據處理的開源技術。例如,用Hive來設計數據消費層,使用Spark來進行ELT等數據處理,以及使用Presto作為臨時資料查詢引擎。
未來,酷澎計畫調整數據擷取模式,要發展事件驅動型(Event-based)即時資料流處理流程,並從異動資料擷取(CDC)逐漸改為強型別Log-based擷取模式。
打造Hadoop抽象層來提升資源運用效率
數據經過初步處理,流到分析平臺,進一步根據實際應用需求來處理。分析平臺是大數據分析、數據探勘、數據管理、查詢、各式實驗、機器學習、顧客體驗分析等諸多數據應用場景的基礎建設,
隨著數據應用需求不斷多元化、規模化,酷澎以原本數據處理架構為基礎,打造新工作管理機制,藉由提升資源利用效率,來支援更多並行工作。這對分析平臺中處理最多數據的大數據平臺,尤其重要。
酷澎對大數據平臺下的Hadoop便下了許多功夫來優化管理機制。他們使用Hadoop環境時,遇到了一些痛點,其一是部分數據使用者不熟悉數據處理指令撰寫,成為他們使用數據的阻力,也使資源運用效率較低。
第二個問題較為複雜,涉及到成本、資源運用及Hadoop設計帶來的限制。
酷澎在Amazon EMR環境執行Hadoop。隨著用量提升,雲端儲存和運算資源用成本控管成為一大課題。酷澎大多使用較便宜的Spot Instances(競價型執行個體),而非較貴的Reserved(預留型)或On-Demand Instances(按需計價執行個體)。代價是,顛峰時段,運算資源時常會AWS被收回,給其他更高優先級或開價更高的雲端用戶使用,導致工作中斷,進而影響整體資料品質。
當酷澎能穩定存取的運算資源不足,便衍生出了大量資料回填(Backfill)需求。偏偏,Hadoop設計上對於數據刪除、更新及新增 (Upsert)支援度不高,大量回填不僅造成額外運算成本,還可能進一步影響數據品質。甚至,來不及等到資料回填,他們就被迫用低品質的數據來進行決策。
2019年,為了優化雲端資源運用效率,酷澎開始依照用途來分類叢集,分出了特定用途、常駐、短期等不同叢集類型,並嚴格控管每個叢集的生命周期長短,以避免浪費運算資源。同時,他們導入了基於人工預測的擴充機制,依據資源用量峰值分析,來提前排程叢集資源擴充,以避免雲端服務商原有的自動擴充功能來不及應對爆量需求。
後來,酷澎還打造了Hadoop抽象層來進一步強化資源分配。Hadoop抽象層是一個Web-based介面,作為中心化監控及管理系統。負責管理的工程師可以用來監控及管理EMR叢集。終端使用者則能透過Airflow operator或Python SDK等管道來提交任務需求到抽象層,再由抽象層自動分配適當的技術、叢集及資源用量。
這個抽象層為Hadoop上的工作流程帶來幾個益處。其一,簡化了大數據處理任務的提交流程;其二,簡化了數據叢集的實體細節;其三,透過自動分配機制,每個任務獲得適當的運算資源,酷澎暫時避免了靠增加額外Hadoop叢集來擴充資源。
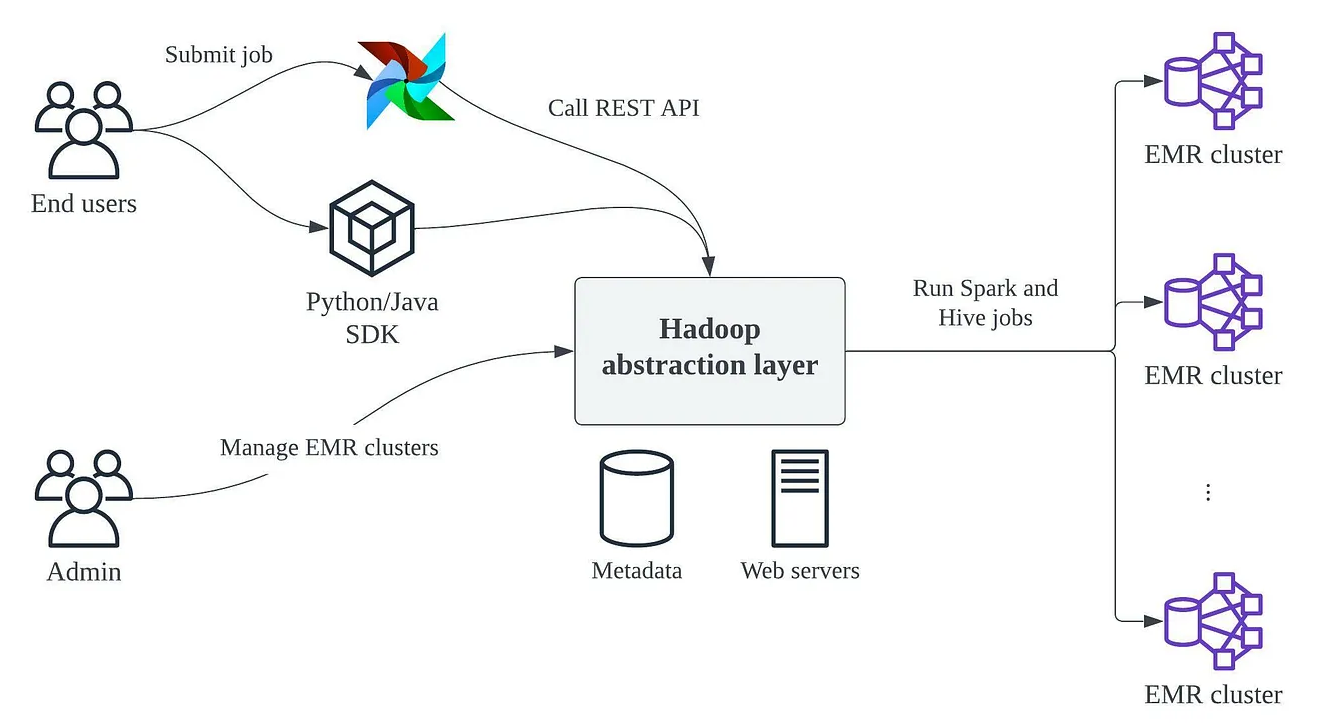
大數據平臺的Hadoop抽象層
酷澎為大數據平臺的Hadoop打造了一層抽象層。一般使用者可以透過Airflow或SDK來提交數據任務,由抽象層會自動分配任務所需資源和執行環境。系統管理員則能透過此抽象層來中心化管理EMR叢集。圖片來源/酷澎
調整Redshift叢集分工來降低資源爭奪
大數據平臺中,酷澎使用Redshift作為銷售、財務、產品目錄及行銷等不同領域數據的資料倉儲。酷澎表示,Redshift管理需求低、上手容易,但隨著數據量以及查詢需求提升,Redshift開始出現了一些問題。
第一是資源用量低擴充彈性問題。Redshift擴充彈性不如Hadoop,酷澎會隨著數據使用需求彈性擴充和縮減。不過,Redshift調整的彈性不足以應付他們數據使用需求變化。這導致工程師調整用量時,時常在使用者溝通及檢查系統健康狀況,費時甚至多於擴充相關的實際工程作業。
第二個問題是並行任務管理問題。Redshift是大規模平行處理(MPP)架構,任務佇列管理會更加複雜,且同時進行的資料查詢或資料處理任務會互相排擠。頻寬和算力的排擠,會造成執行速度下滑;數據及元數據存取權的排擠,則會導致資料存取鎖定(Data lock)。也由於MPP原本設計上不會於叢集間分享數據,酷澎起初做法是在不同叢集叢集中儲存數據副本,雖然一定程度增加任務執行速度,但算力和儲存需求負荷便會更重。
後來,酷澎調整Redshift叢集的架構,分為3個數據處理叢集以及5個使用者查詢叢集。前者又分為1個關鍵處理叢集以及2個一般處理叢集。一般處理叢集主要用來處理數據提取及載入(ELT中的E和L),以及少量轉換(ELT中的T);關鍵處理叢集負責關鍵資料轉換,從原始資料轉為符合不同需求的資料市集。
5個使用者查詢叢集則分配給不同業務領域的使用者,用來做領域專門的臨時分析、額外數據轉換,以及重複執行查詢指令來做數據追蹤。
這種分工模式,使叢集間爭取資源的情況減少。他們還將這些叢集轉換為Redshift RA3叢集,支援跨叢集數據共享功能,不再需要手動複製數據。
不只如此,他們導入了Redshift Spectrum工具,可以直接從S3環境中查詢結構和半結構化資料,而不需要載入數據到Redshift表格中。若使用者要查詢的數據不需要經由Redshift叢集處理,便能直接透過Spectrum來快速達成。
未來,他們計畫將Redshift資料處理程序轉移到資源擴充更彈性的EMR環境,利用Spark來進行資料處理。不過,仍支援使用者用Redshift來處理儲存於S3的數據。
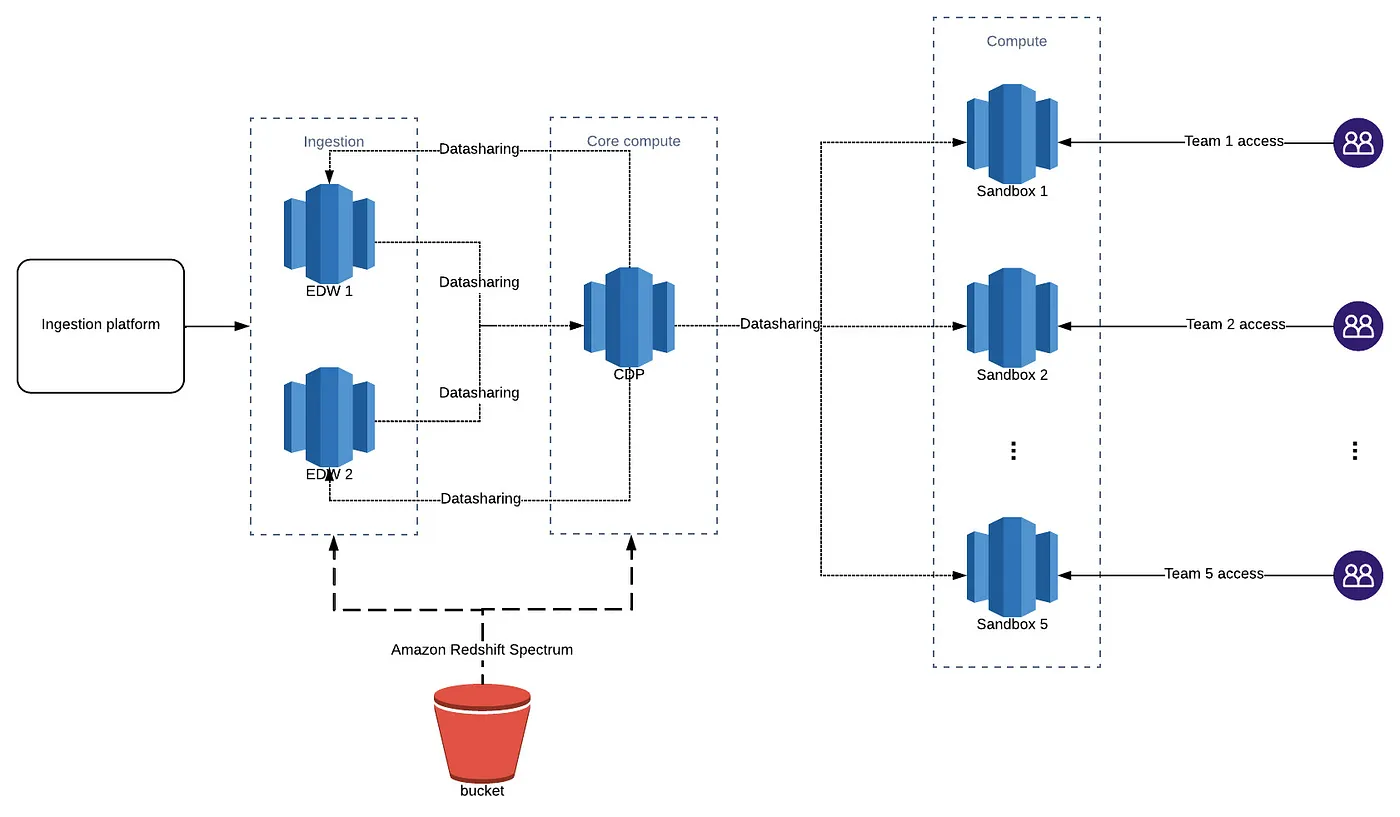
大數據平臺的Redshift叢集設計架構
酷澎為大數據平臺的Redshift重新設計了叢集架構,數據會先由2個一般處理叢集進行提取和載入,再由關鍵處理叢集來轉換,輸入到5個依業務領域分類的使用者查詢叢集,進行進一步轉換、測試和分析。圖片來源/酷澎
建立數據探勘系統來支援全平臺元數據檢索
良好的元數據搜尋功能對於數據探勘、數據管理、各式數據工程及數據應用來說相當關鍵。酷澎早期已經開發了元數據搜尋引擎,不過隨著數據基礎架構演進,此系統不復堪用。
舉例來說,Hive元數據儲存在Metastore資料庫中,但實際數據則儲存在HDFS中,使用者常會需要知道數據格式、儲存位置、數據沿襲、新鮮度、以及產生時間等資訊。這與傳統RDBMS只在意表格Schema的情況非常不同。
近年酷澎更新了數據探勘系統,會自動用Meta query從各式生產系統的資料庫以及資料倉儲蒐集元數據,並統一儲存在中央元數據資料庫中,供使用者搜尋。此系統1小時內便能反映元數據變動。
這個探勘系統雖然不複雜,卻是大數據平臺重要的一環,也是酷澎內使用率前幾高的數據管理功能,一天會有上百人來從上千個數據表中查詢元數據。
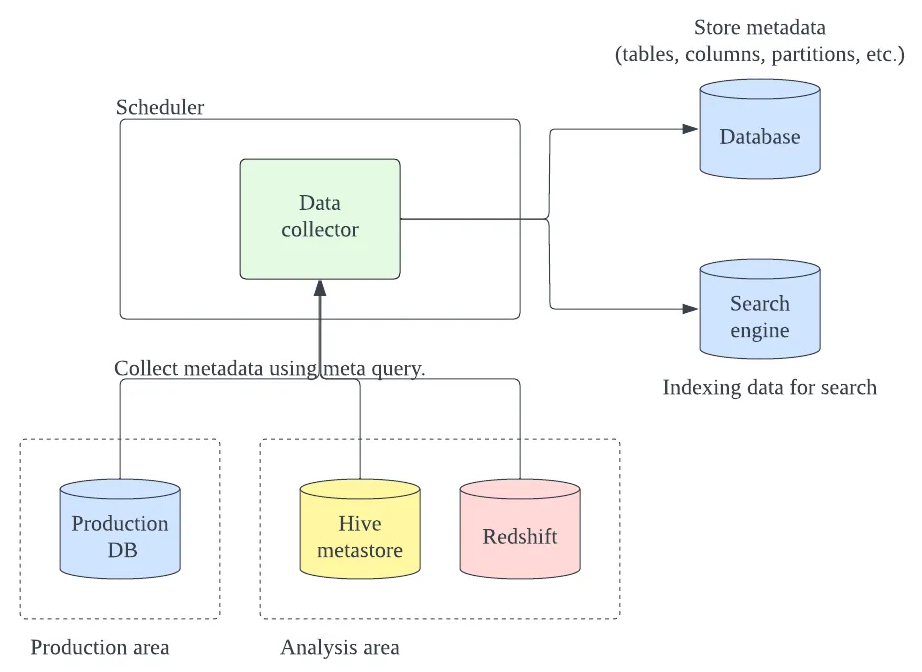
大數據平臺的數據探勘系統
數據探勘系統會從各式生產資料庫及資料倉儲蒐集元數據,供每天上百個使用者搜尋上千個數據表的各式元數據,包括數據格式、儲存位置、沿襲歷程、新鮮度、以及產生時間等。圖片來源/酷澎
打造顧客分析及ML專用平臺,統一管理工作流程及資源分配
顧客資料分析以及機器學習模型訓練是酷澎兩大類關鍵數據應用情境,經手數據量大、數據處理需求多、應用範圍也廣。過往,這兩類情境的數據流程是逐案建立,不過隨著需求量提升,他們便為這兩類情境打造了專用自助式平臺,以減少重工、統一工作流程、管理資源分配,並降低非工程人員使用門檻。
為顧客資料分析建立的自助式平臺名為顧客經驗分析平臺(CXAP),會蒐集各式客戶端事件數據並提供分析功能。此平臺作用類似於CDP,不過是整合到整個數據平臺當中,而非一個獨立系統。
使用者於CXAP前端介面可以進行數據分析和探勘。CXAP支援輸入SQL指令,也有圖形化使用者界面,不需要寫程式碼就可以做到使用者旅途分析、銷售漏斗分析、數據趨勢分析等操作。
CXAP後端包含開源關連式資料庫ClickHouse,支援接近即時的數據擷取和處理,可以在數據產生數十秒內完成擷取,以加速數據從生成到實際應用。他們還整合了數據分析及探勘工具Superset,可以快速製作視覺化報表。
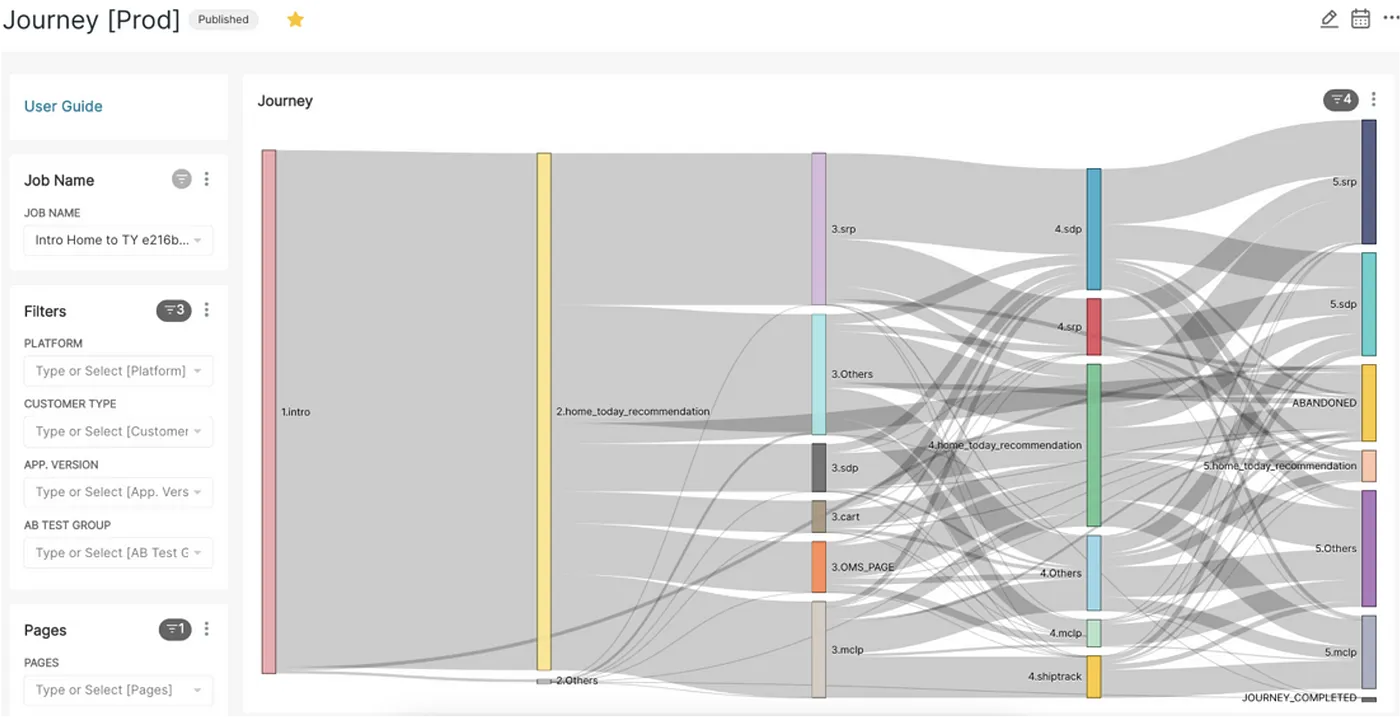
分析類平臺的顧客體驗分析平臺
酷澎分析平臺下的顧客體驗分析平臺可以用SQL指令來搜尋各式客戶端事件數據,也能透過No-code工具來生產各式視覺化資料分析報表。圖為分析顧客旅途用的桑基圖。圖片來源/酷澎
酷澎也為機器學習模型開發設置了一個平臺。機器學習平臺則比CXAP更加複雜,統一了數據準備、互動式Notebook開發環境、運算資源存取、超參數調整、模型部署及應用等ML工作流程,並支援常見ML工程所需資源。
此平臺將ML模型開發流程分為3階段:數據準備階段、訓練和追蹤階段、實際應用階段。數據準備階段,酷澎使用Airflow來管理並驅動Spark、Hive、Presto等數據處理工具,以導入機器學習所需訓練數據。他們更開發了一個SDK,讓工程師可以整合、同步、分享及管理不同來源的數據集。
訓練和追蹤階段,此平臺提供預先封裝了各式常見ML/DL框架及數據科學函式庫的容器,只要啟動一個Jupyter容器即能進行後續開發。開發人員可以透過CLI或API來存取GPU運算資源,進行模型訓練,還可以透過視覺化儀錶板追蹤實驗進度。此平臺也支援多種超參數調整演算法,來快速實驗不同超參數設定。
實際應用階段,此平臺內建模型部署工具,用K8S來管理和執行模型部署及連結到外部應用程式。開發人員也容易透過Jsonnet來設定自動擴充配置,以及產生符合REST格式和使用gRPS協定的模型對外API。
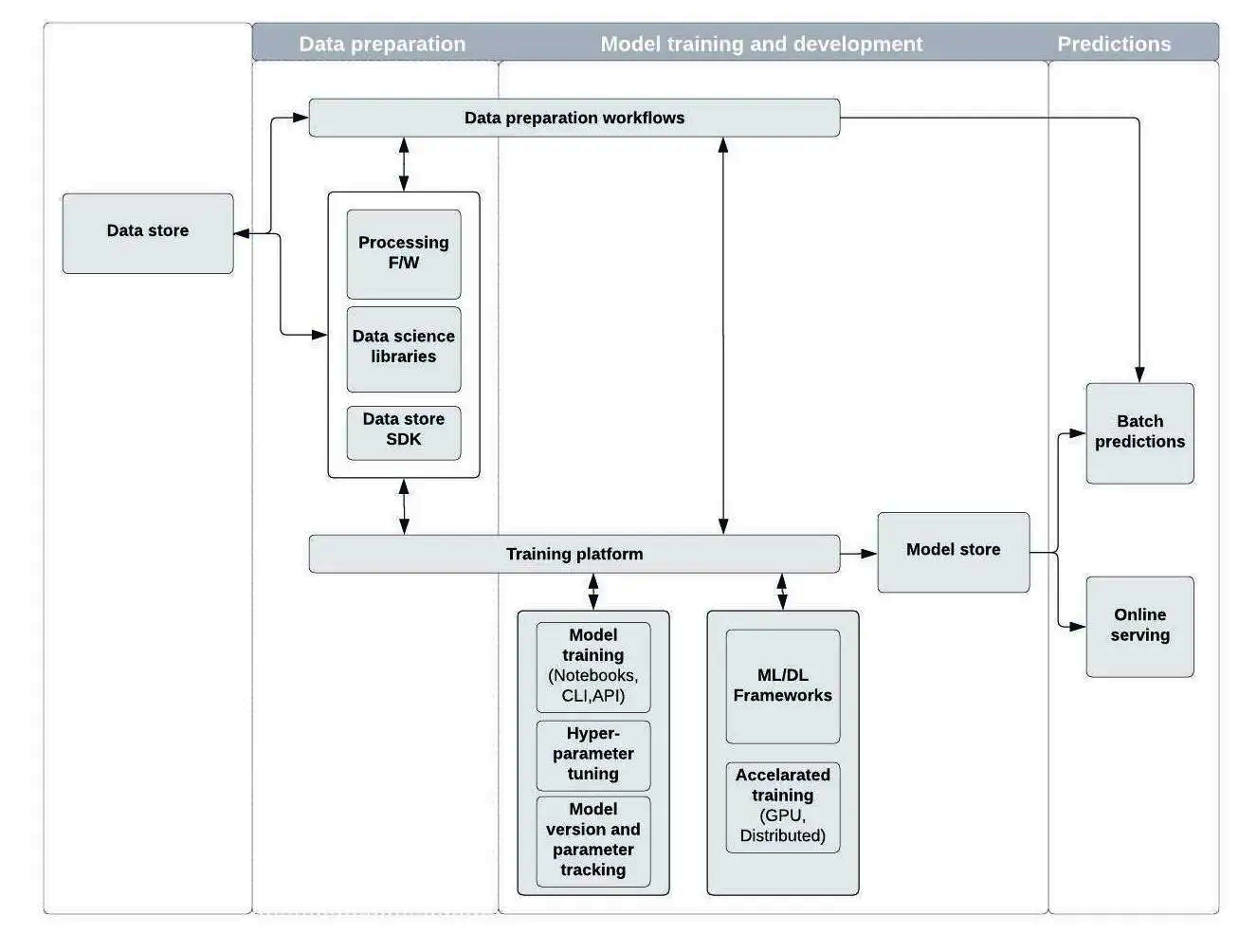
分析類平臺的機器學習平臺
酷澎分析平臺下的機器學習平臺制定了一個標準化工作流程,涵蓋資料準備、訓練、GPU資源調度、模型調整、模型儲存、模型部署、外部系統串接。平臺上提供許多常見ML工程所需資源,並有統一GPU資源分配機制。圖片來源/酷澎
數據經過數據平臺一系列處理後,會輸出到各式工具及系統,供內外部終端使用者使用。正是利用這些數據,酷澎許多核心競爭能力才變得可能。
接下來,我們將介紹酷澎如何利用這些數據,來支援火箭速配背後的自製地圖系統、高科技物流中心背後的SCM應用開發工具,以及支援產品功能設計、產品外觀設計、SCM、行銷等不同領域利用數據驅動決策的實驗平臺。

熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09