隨著人工智慧迅速發展,可預期不久的將來,會出現比人類更聰明的人工智慧,OpenAI提出了一個人類需要迫切面對的課題,是當人工智慧比人類更聰明,人類該如何有效地進行監督?在這樣的背景,OpenAI展開超對齊(Superalignment)研究,最新的研究成果是以小模型來監督大模型,在人類開發和管理超級人工智慧(Superhuman AI)的難題上,提供一個新視角。
OpenAI直言比人類聰明的人工智慧在10年內會出現,而至今人類仍然不知道如何可靠地指導和控制超級人工智慧,唯有找到有效的控制方法,才能夠確保先進的人工智慧系統的安全性。面對這個問題,OpenAI成立了超級對齊(Superalignment)團隊來找出解決方案。
在人工智慧領域中,對齊(Alignment)概念指的是確保人工智慧系統的行為,符合人類設定的目標和道德標準,對齊主要關注當前和短期內的人工智慧技術,使這些人工智慧系統能夠安全地服務人類。而超級對齊則是研究更前瞻的議題,針對未來可能出現超越人類智慧的人工智慧系統,確保超級人工智慧系統能夠被有效的監督,並且使其行為與人類的價值觀和利益保持一致。
目前的對齊方法主要是來自人類回饋的增強學習(RLHF),但是因為未來人工智慧系統將能夠執行極複雜和具創造性的行為,這將使得人類難以進行監督,像是超級人工智慧可能可以編寫數百萬行具有潛在危險的程式碼,即便是專家也難以完全理解。
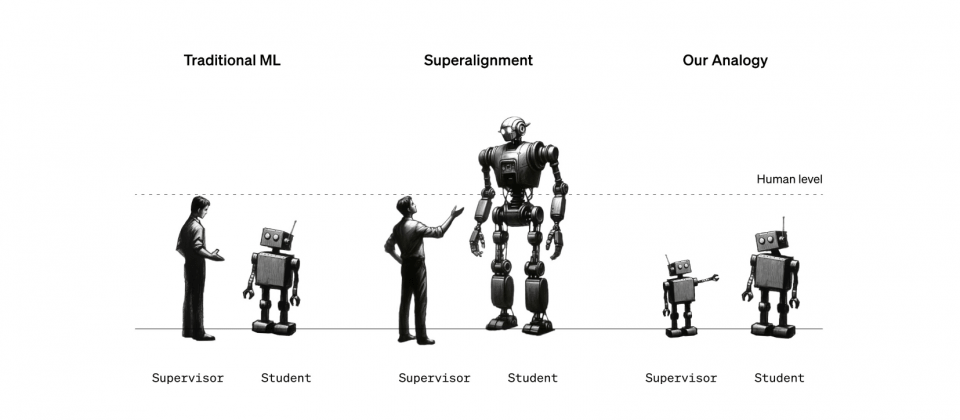
也就是說,相對於超級人工智慧,人類成為了弱監督者,如何讓弱監督者能夠信任並控制遠比自己還要強大的模型,是人類要進入通用人工智慧時代前,必須先面對的挑戰。為了解決人類如何監督比自己更聰明的人工智慧這個問題,OpenAI限縮問題類比該問題,相當於一個較小的模型監督一個較強大的模型。
研究團隊在這項研究中的初步猜想,涵蓋了兩個相對立的觀點。一方面認為強模型可能無法超越提供訓練訊號的弱監督者,因為強模型會學習並且模仿弱監督者所犯的錯誤,進而限制了表現。另一方面也希望強大的預訓練模型,只需要經過適當引導即可發揮潛在能力,即便是弱監督者提供不完整或有缺陷的訓練標籤,強模型也能根據弱監督者的意圖進行泛化,進而解決更為困難且複雜的問題。
研究團隊使用簡單的方法鼓勵模型更有自信,使強模型能夠不受弱監督者的能力限制,甚至在必要的時候反對弱監督者的意見,因此在自然語言處理任務中,以GPT-2模型監督GPT-4時,產生的模型能力通常介於GPT-3和GPT-3.5,許多GPT-4的能力仍然可以發揮。
這項研究展現了一種可能性,也就是即便是在弱監督的指導下,強大的人工智慧模型也能超越其限制,達到更高水準的效能,這項發現替未來在超級人工智慧系統中,實現有效的對齊提供新的方向和希望。也就是說,即便人類身為弱監督者,能力和理解可能受到限制,並無法良好地評估強模型,但是身為弱監督者仍有能力引導和改善強模型的表現,揭示了人類控制更先進的人工智慧系統的可能性。
同時這項研究也證明了現有的對齊方法,也就是基於人類回饋的增強學習,可能需要進一步改進才能適應超級人工智慧。總而言之,儘管現階段的對齊方法仍存在挑戰,但透過創新的策略和技術,將可以有效提升人工智慧的泛化能力,這對於未來開發和管理超級人工智慧有重要的意義。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10