
Google揭露最新多模態大型語言模型VideoPoet,該語言模型能夠執行各種影片生成任務,包括文字轉影片、圖片轉影片、影片風格化,影片補繪與擴繪,甚至是影片轉音訊等。該模型特別之處在於VideoPoet是一個大型語言模型,有別於目前大多基於擴散模型的影片生成模型。
Google指出,即使是目前最先進的影片生成模型,也只能生成小幅度的動作,在生成大動作的時候,就會出現明顯的破綻。Google探索大型語言模型在影片生成領域的應用,開發出VideoPoet,這是一個能夠執行各種影片生成、任務的大型語言模型,研究人員指出,諸如Imagen Video等影片生成模型,都是以擴散模型為基礎。
由於大型語言模型目前在各個領域,包括語言、程式碼和聲音等,都具有極強的處理能力,Google認為,大型語言模型因為在多種模態上優秀的學習能力,已經成為重要的技術標準。因此不同於該領域的其他模型,VideoPoet將影片生成能力整合到單一大型語言模型中,而非仰賴各項針對性任務訓練的獨立元件。
影片生成任務採用大型語言模型的優勢,在於可以利用現有的高效訓練基礎設施,但研究人員也指出,大型語言模型的本質上是處理離散的標記(Token),而這對於生成影片是一個挑戰。因此研究人員開發了專用的影片和音訊標記器(Tokenizer),將影片和音訊剪輯片段編碼為離散的標記序列,而這個離散的標記序列也能夠被轉換回原始表示。
VideoPoet藉由使用多種標記器,學習處理影片、圖像、音訊和文字等不同模態。當模型根據特定上下文條件生成相對應的標記後,這些標記就可以透過標記器轉換回可查看的表示形式,生成影片和音訊內容。
VideoPoet適應短影片格式預設生成縱向影片,並在進行影片風格化時,能夠預測光流(Optical Flow)以及深度資訊(下圖)。同時VideoPoet也可以生成音訊,透過先從模型生成2秒的音訊片段,接著就可在沒有文字指引的情況下,預測接下來的音訊。而這也讓VideoPoet單一模型,就可生成影片和配音。

VideoPoet能以前一秒的影片預測下1秒的影片,以連續預測的方式達到生成更長影片的目的,而這種方法不只可以有效延長影片,而且經過多次迭代後仍能保持影片主體的外觀不變。VideoPoet生成的影片也能夠以互動的方式編輯,像是改變影片中物體的運動,使其執行不同的動作,且編輯會從影片的第一個影格,或是中段的影格開始,提供了高度可編輯控制性。使用者也可以透過文字提示,添加需要的攝影機運動方式,藉此精確地控制攝影機的移動。
經過評估,VideoPoet能夠良好的執行影片生成任務,在多項基準測試中,VideoPoet較其他模型表現更好。研究人員要求評估者根據偏好選擇,在文字準確度方面,平均24%-35%VideoPoet的範例被認為更符合指令描述,而其他模型的比例則為8%-11%。評估者還更傾向選擇VideoPoet範例,認為其中41%-54%範例呈現出更有趣的運動方式,相較於其他模型比例只有11%-21%(下圖)。
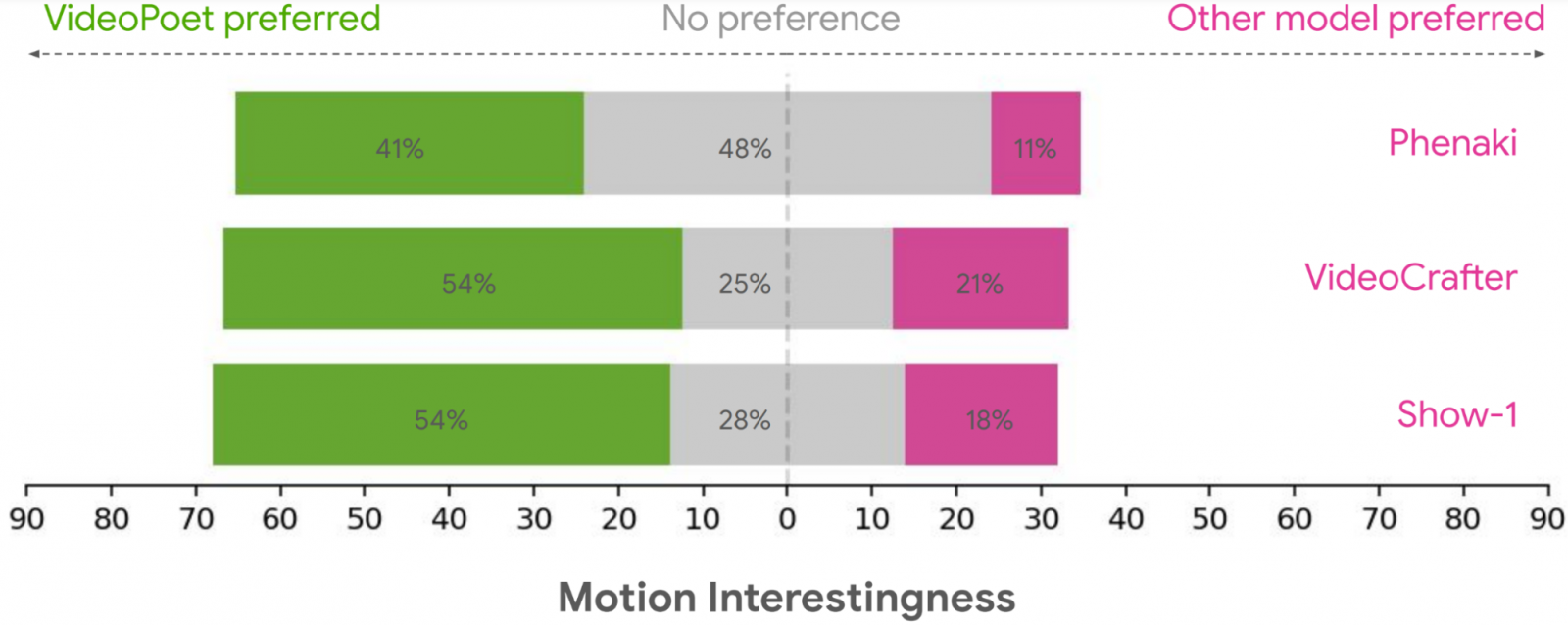
VideoPoet的研究貢獻在於展示大型語言模型的能力,也具有生成高度競爭力影片的能力,特別是在高品質的動作表現方面。研究人員指出,對於未來研究,他們的框架會朝向支援任意形式生成任意形式內容的方向發展。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10