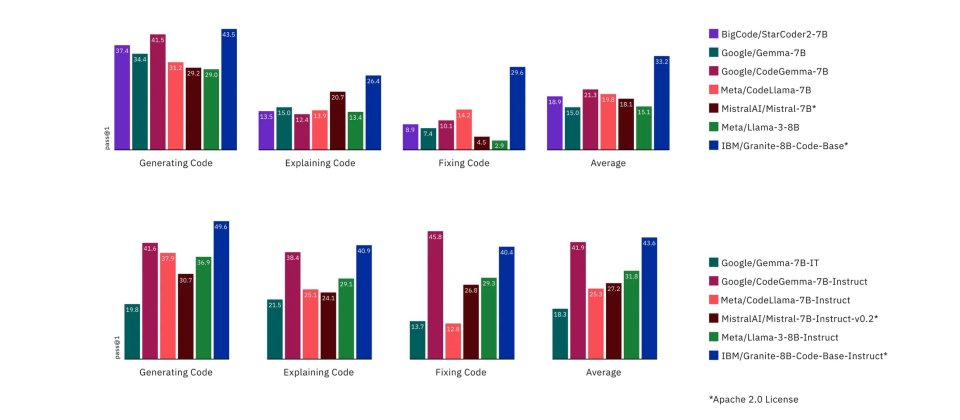
IBM以Apache 2.0授權條款開源一系列Granite程式碼模型,大小從30億到340億參數,包括基礎模型和指令跟隨模型,可用於應用程式現代化任務,甚至也可在記憶體有限的裝置上運作。經多個基準測試實驗,Granite程式碼模型在包括程式碼生成、修復與解釋任務,較多數開源程式碼大型語言模型的表現更好。
Granite程式碼模型具有多個變體,而IBM提到,針對大部分企業使用案例,80億參數的Granite程式碼模型,是權重、執行成本和功能最合適的組合。同時Granite程式碼模型也有高達340億參數的變體,而IBM使用一種稱為深度放大(Depth Upscaling)的方式,來訓練這些較大型的模型。
深度放大是一種增加模型層數的方法,以340億參數的Granite程式碼模型來說,研究人員創建了兩個200億參數的模型變體,每個變體有52層,藉由將第一個變體的最後8層,以及第二個變體的前8層去掉,再將這兩個模型合併,形成一個88層、具340億參數的新模型。研究人員提到,該方法將使模型層數更深,以提高其效能。
官方同時也發表了Granite程式碼指令跟隨模型,該模型經過Git提交和人工綜合指令,還有開源合成程式碼指令資料集微調。
研究人員針對當前各種Apache 2.0授權的開源模型,以HumanEvalPack、HumanEvalPlus和RepoBench基準測試進行比較。Granite程式碼系列模型在Python、JavaScript、Java、Go、C++和Rust程式語言的程式碼合成,修復、解釋、編輯和翻譯都表現良好。
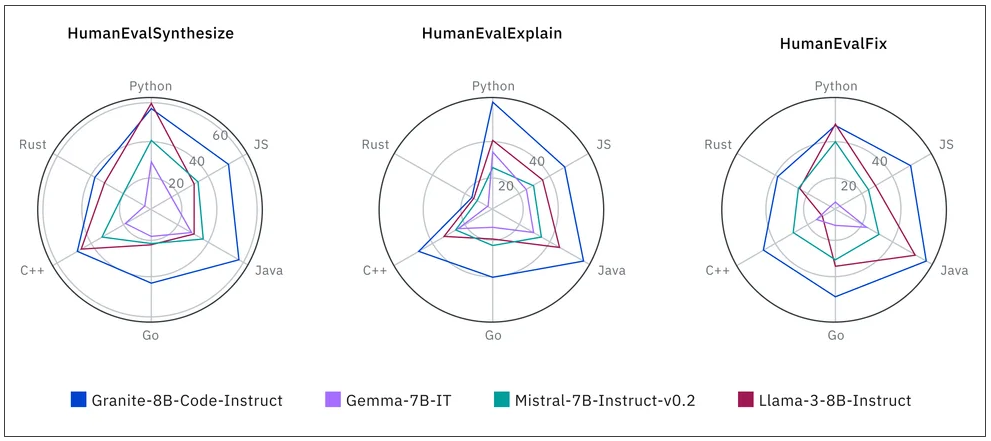
圖片來源/IBM
雖有部分模型在生成和修復程式碼等任務超越Granite程式碼模型,但整體來說,Granite程式碼模型能力表現平均,在多項測試中都獲得第一的位置。開發者現在已經可以在Hugging Face、GitHub、watsonx.ai和RHEL AI平臺使用到Granite程式碼系列模型。
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-10

2026-02-09