GitHub
大廠持續投入終端裝置上的AI模型開發。Llama模型家族獲得眾多開發人員使用後,Meta本周稍早又公布可在行動裝置上執行,參數量不到10億的新AI模型家族。
由於在雲端執行上百甚至上千億參數的大型語言模型(LLM)增加雲端運算成本及延遲性問題,推升了筆電或手機等行動裝置端上執行LLM的運行需求。Meta集結旗下Meta Reality Labs、PyTorch與Meta AI Research(FAIR)部門研發新訓練方法,建立參數量僅有1.25億、3.5億的新式模型MobileLLM。
Meta研究小組公布的論文說明該公司優化小型LLM的創新方法。他們認為,對小模型而言,模型的深度比廣度來得重要,他們採取「深而精簡」(deep- and-thin)的模型架構更能以極高效能萃取抽象概念。他們採用內嵌共享(embedding sharing)技術實作出群組查詢注意力(Grouped Query Attention,GQA)方法用於小型LLM,以便最大化權重利用率。此外,他們還發展權重共享的新方法,能提升減少記憶體區塊(block)運算次數,進一步降低AI模型運算延遲性。
研究人員將其訓練出的MobileLLM 125M/350M和參數量相當的State of the Art(SOTA)模型如Cerebras、OPT、BLOOM等進行對話標竿測試。在零樣本(zero-shot)測試中MobileLLM 125M/350M比SOTA模型的平均準確率高出2.7%/4.3%。研究人員使用權重共享方法訓練出的MobileLLM 125M/350M版本,名為MobileLLM LS-125M/350M,還可以將準確率分別再向上提升0.7%及0.8%。
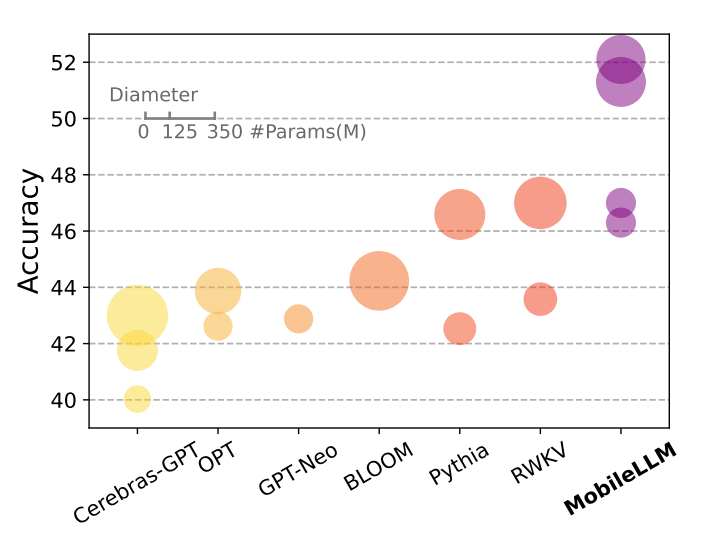
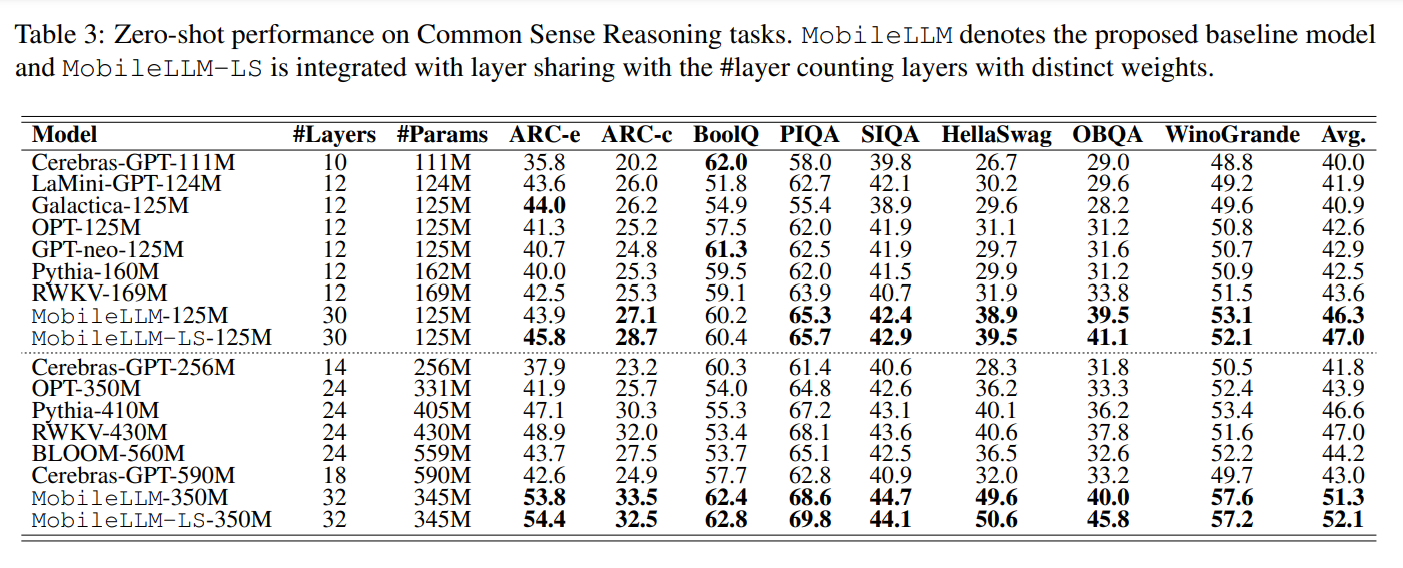
MobileLLM 125M/350M在聊天和API呼叫任務中,效能大幅超越參數量相當的小型LLM。其中,在API呼叫任務中,這個新模型得分還比Meta的LLaMA-v2 7B模型大幅領先。
研究人員另外也訓練了其他參數規模的模型,包括MobileLLM-600M/1B/1.5B。
Meta研究小組將MobileLLM的相關資源公開於GitH
最新研究使Meta也躋身裝置端(on-device)AI模型的供應商之林。今年稍早蘋果公布了OpenELM 270M/450M/1.1B/3B、Google則先後開源了Gemma 2B/7B、Gemm2-9B/27B。
熱門新聞

2026-02-11

2026-02-09

2026-02-10
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-06

2026-02-10

2026-02-10

2026-02-10