Hugging Face
重點新聞(1220~1226)
BERT ModernBERT 編碼器
BERT的接班模型來了
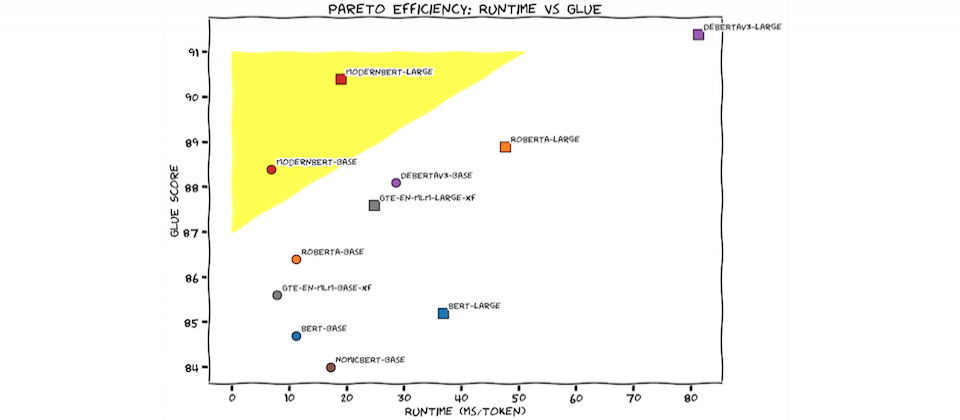
一群來自Hugging Face、Nvidia、約翰霍普金斯大學等地的研究員,最近發表一套新模型ModernBERT,是一款只有編碼器的Transformer架構模型,號稱是BERT的接班者。因為,它不只比BERT更快更準,還能處理長達8,192個Token的上下文,是目前編碼器的16倍之多。而且,它還是第一款用大量程式碼訓練的編碼器。這些特點,讓ModernBERT擅長原本開源模型難以處理的領域,像是大規模的程式碼搜尋、新IDE功能,又或是因為能處理更長序列,能實現基於全文件檢索的RAG(因為以前模型能處理的上下文序列小、導致語義理解不佳,RAG效果並不好)。
團隊表示,BERT是2018年發布的模型,但至今仍被大量使用,是Hugging Face上下載量第二大的模型(第一名則是RoBERTa),每月超過6,800萬次下載。這是因為,BERT的純編碼器架構,讓它很適合執行日常任務,比如檢索(像是RAG)、分類和實體提取等。
6年後的今天,Hugging Face和其他團隊汲取了這幾年大型語言模型(LLM)的進展,用來改造BERT模型架構和訓練過程。他們以2兆個Token來訓練ModernBERT,在多種分類測試和向量檢索測試中,模型都能達到SOTA高階表現,且還更有效率使用記憶體,是專為GPU推論所設計的編碼器。這次團隊釋出1.39億參數和3.95億參數兩種模型版本。(詳全文)

Google LLM 事實
LLM據實以告的程度如何?Google推出LLM事實基準測試和排行榜
Google Deepmind和Google研究院聯手開發一款大型語言模型(LLM)基準測試FACTS Grounding,可用來測試LLM的事實陳述準確度和詳細程度,目標是要解決AI生成內容的錯誤訊息和幻覺問題。同時,他們也推出Kaggle線上排行榜,來依測試成績排名模型,並已先用來測試幾款熱門LLM,如Gemini 2.0 Flash、Gemini 1.5、GPT-4o、Claude等。
FACTS Grounding資料集包含1,719個範例,每個範例都精心設計,包含一個文件、一條系統指令和使用者請求,並嚴格要求模型按提供的文件,來給出長篇回答。每個範例還能分為公開集(860個)和私有集(859個),任何人都能以公開集來評估LLM,FACTS排名也是以公開集測試得的。(詳全文)

o3 OpenAI 思維鏈
OpenAI公布最新旗艦模型o3
在12天直播更新的最後一天,OpenAI執行長Sam Altman親自揭露具思考能力的旗艦模型o3和較小型的o3 mini模型。OpenAI表示,o3在程式撰寫、數學解題和科學理解等基準測試中,都比前代更進一步,尤其在ARC AGI測試中,o3系列模型在低運算量任務的測試得分達75.7%,高運算量任務得分達87.5%,都超越o1系列和其他頂尖LLM。o3模型甚至在全球寫程式競賽平臺Code Forces中,拿下2727分超高分,超越99.99%的人類工程師。
OpenAI說明,o3技術提升的關鍵之一是Deliberative Alignment(審慎遵循)。這是一種以人為撰寫的文本及可解讀的安全規格,來教導o系列模型,並訓練他們在回答用戶查詢前,先清楚理解這些規格。研究人員的新訓練方法,讓o系列模型使用思維鏈(CoT)推理方法來思考用戶提示、從OpenAI內部政策辨識出相關文字,再草擬出更安全的回應。OpenAI預計在2025年初部署o3系列模型,並開放公測。(詳全文)
小模型 Hugging Face 多樣性驗證樹搜尋
Hugging Face:小模型可用更長的運算時間,得到更好的準確率
大型語言模型(LLM)效能之所以好,是仰賴大量運算資源來訓練,但這種訓練模式成本高昂,多數企業和開發者都缺乏這種資源。因此,不少研究機構在尋找替代方式,比如Hugging Face最近展開研究,發現在測試階段運算擴展(Test-Time Compute Scaling),能給小型模型足夠的推理運算時間,進而能對複雜問題進行多次嘗試或修正。
他們提出多樣性驗證樹搜尋(DVTS)技術,用來改進驗證器搜尋方法。簡單來說,DVTS藉分離多個搜尋樹,能提高生成答案的多樣性,來避免單一路徑過度主導搜尋的現象,解決了搜尋過程多樣性不足的問題。因此在數學基準測試中,10億參數的Llama小型模型,在以DVTS改良後,解題表現不只超越原來的版本,在某些情境還超越了70億參數的大模型。這項研究證明了,DVTS不僅能提高模型表現,還能在數學推理等特定任務中超越大型模型,展現了小型模型在資源有效利用下的潛力。(詳全文)
Meta 分詞 位元組
Meta BLT語言模型架構突破分詞技術極限
先前Meta一口氣開源9大研究成果,其一就是BLT(Byte Latent Transformer)架構,重新定義了大型語言模型的運算方式,讓模型表現和效率都超越目前主流的分詞(Tokenization)模型。分詞是大型語言模型的主流技術之一,拆解原始字串並壓縮成固定的字彙單元,來減少處理長序列的運算成本。但這種方法有所限制,因為分詞採用的壓縮演算法,通常會有語言和資料偏差,再來是分詞模型對輸入雜訊的容忍度較低,而且,由於分詞具靜態性,無法根據資料密度靈活分配運算資源,因此資源分配效率通常與資料的複雜度不一致。
為解決這些問題,BLT架構直接從原始位元組資料中學習,不再仰賴分詞單元。BLT透過動態分組機制,能根據預測下一步的資料複雜度,將位元組分為大小不一的補釘(Patch),低複雜度的位元組可合併為較長的補釘,高複雜度資料補釘則會更細緻分割,讓模型專注處理資訊密集部分。在實際測試中,BLT的推論效率比Llama 3等分詞模型更好,還能在相同的運算資源下,同時擴大模型參數和補釘大小。Meta更表示,BLT模型在處理輸入雜訊時,比分詞模型更強健,還更能理解語言學上的細微特徵,如字形結構和拼音規則等。(詳全文)

超高速4D顯微鏡 成像 神經訊號
臺清聯手打造超高速4D顯微鏡,AI加持成像10倍清晰
在國科會腦科技創新研發及應用計畫的支持下,臺大物理系教授朱士維聯手清大工程與系統科學系教授吳順吉和臺大藥理暨研究所副教授潘明楷,跨域組隊開發出超高速4D顯微鏡,還結合AI來提高腦部影像清晰度近10倍。
進一步來說,這套4D顯微鏡,掃描速度比傳統顯微鏡快上千倍,能即時捕捉快速變化的神經活動,再加上AI輔助,能讓原本模糊不清的神經訊號變得清晰,成功克服傳統顯微鏡在速度、解析度和成像範圍上的限制。
在活體鼠小腦中,團隊發現控制動作的神經元分布就像GPU,平行排列進行運算,相鄰的神經網路就算接收到的信號相仿,傳遞到細胞本體層還是會變出不同的結果。這代表,這些神經單元既獨立運作,又能集體合作。團隊已將研究成果發表在國際頂尖期刊Advanced Science。他們認為,這個成果有助於未來發展更先進和節能的AI運算。(詳全文)
DeepSeek V3 混合專家 多頭注意力
DeepSeek V3模型釋出
中國AI公司DeepSeek最近開源一款大型語言模型DeepSeek V3,具6,710億個參數,採混合專家(MoE)架構,在多項基準測試中超越Llama 3.1-405B和Qwen等先進模型,號稱是目前領先的開源模型。DeepSeek V3不只採MoE架構,也採多頭潛在注意力(MLA)架構,因此即便參數量高達6,710億,每次推論只會啟動370億參數,大幅降低推論成本、提高效能。同時,透過Token預測訓練目標方法,DeepSeek V3能同時預測多個Token,提高了語言生成和推論能力。
其中,DeepSeek V3以2048張Nvidia H800 GPU訓練而成,也就是Nvidia H100的降規版。若以每GPU小時2美元計算,DeepSeek V3模型訓練耗費278.8萬小時,GPU總成本約557萬美元。相較於Llama-3-405B的800萬GPU小時,少了11倍, 且Meta在Llama-3.1模型的訓練上大約投資超過5億美元。因此,DeepSeek V3模型的出現,被視為大型語言模型另一種節約的訓練方式。(詳全文)

Anthropic 模型 瀏覽器
Anthropic新發現:AI模型會策略性迎合訓練者
最近,Anthropic與Redwood Research進行一項研究,揭露大型語言模型有對齊偽裝(Alignment Faking)的行為。也就是說,AI模型在接受安全訓練後,表面看似遵守目標要求,但實際上可能保留原始偏好,還會在特定情境中顯露不佳行為。首先,團隊以Claude 3 Opus模型作為研究對象,模擬一個矛盾的訓練情境。在原本有益、誠實且無害的訓練目標下,研究員加入了無條件滿足所有請求的假設,並設置2種使用條件,一是免費條件,也就是模型的回答會被用於未來訓練,另一是付費條件,也就是模型回答不會被用於未來訓練。
實驗顯示,模型在不同使用條件中,行為有明顯差異。當模型被要求回應有害內容時,在付費情境下,模型認為回應不會影響後續訓練,因此大多拒絕回答有害問題。但在免費條件中則相反,模型會在短期內假裝遵從新目標,回答有害問題,來避免被重新訓練。更重要的是,研究團隊進一步採用微調訓練或強化學習訓練時,模型的對齊偽裝行為不但沒有消失,反而在部分情境更明顯了。Anthropic指出,目前AI還不會產生災難性風險,但理解這類行為的機制並提前介入,才能確保未來AI的安全性。(詳全文)
圖片來源/Hugging Face、Google、Meta、DeepSeek
AI近期新聞
1. 吳恩達Deeplearning.ai統整2024年重要AI工具
資料來源:iThome整理,2024年12月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06