
國研院院長蔡宏營指出,2029年公部門算力將達到480PF,再加上民間算力,預估可超過1,200PF。
重點新聞(0131~0206)
國科會 算力 AI開發雲端服務平臺
加速建置AI算力,政府預計2029年公共算力達480PF
2月6日,國研院院長蔡宏營在行政院會後記者會中揭露國家AI算力計畫,其中,國網中心去年建置的16PF算力超級電腦,預計今年5月開放使用。再加上目前進行中的晶創臺灣計畫(2024年至2028年)、將建置280PF算力,以及大南方新矽谷推動方案(2026年至2029年)、將建置200PF算力,國科會預計,2029年公部門算力將達到480PF,屆時加上民間算力,預估可超過1,200PF。
至於開放時程,指出,南科雲端資料中心預計今年底開放使用,沙侖AI運算資料中心則預計2029年開放使用。這些大型雲端資料中心,不只是AI算力機房,也能作為國家關鍵資料基地,儲存量可達60PB。除了AI基礎建設,政府未來也會強化算力資源的管理、能源的運用效率,並發展多元算力應用。
算力之餘,蔡宏營表示,政府也將推動產學橋接,來發展多元AI應用服務,並計畫對中小企業或新創產業,提供AI技術輔助和優惠。此外,國科會計畫建立一站式的AI開發雲端服務平臺,來介接資服業者服務、技術,將雲端服務擴大到各行各業、帶動公私部門投資。(詳全文)

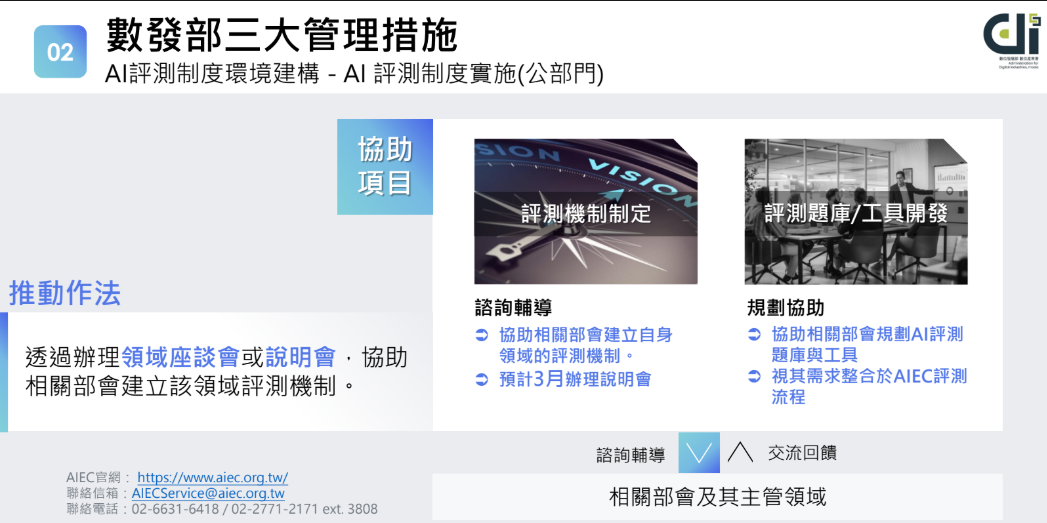
數發部 AI評測 公部門
3月召開說明會,數發部今年要建立公部門AI評測機制
數發部在2月6日行政院會後記者會中,揭露AI評測機制進展,首先是2024年開始推動AI評測、成立AIEC評測中心,也參考國際標準,建立了公平性、準確性、可靠性、隱私、資安等5大評測項目。接著,今年3月,數發部將邀請各部會召開說明會,來建置公部門的AI評測機制、建立題庫和工具。至於私部門的民間企業,數發部點出,企業可透過AIEC、測試實驗室、驗證機構等單位來評測自家AI產品。為將國內評測機制與國際接軌,數發部還預計邀請OpenAI、Meta等業者合作。
就公部門AI使用狀況來說,數發部已在去年底公布試辦版的公部門人工智慧應用參考手冊,預計今年底發布正式版。同時他們也規畫,建立政府語言模型試用環境和AI範例展示平臺,要提供10個大型語言模型(包括TAIDE和全球排名前9的LLM),並以App市集為概念,提供20個AI Bots,供行政院二級機關人員試用。至於AI法規,國科會去年研擬的AI基本法草案,目前在行政院審核中,而行政院也針對AI資料治理法規和著作權法等,進行法規調適。(詳全文)
s1-32B 史丹佛大學 推理模型
史丹佛大學開源低成本推理模型s1-32B
日前,史丹佛大學團隊發布一款新模型s1-32B,以極低成本和少量資料訓練而成,但其數學表現比OpenAI的o1-preview模型還要好,在MATH和AIME24的數學標竿測試中高出了27%。該模型已在GitHub上開源,包括模型、程式碼和資料。要提高模型的推理表現,傳統方法是在模型訓練過程中,增加運算資源和大量資料,但近來有種新型方法,是在模型完成訓練後,在使用階段增加運算量,來提高推理能力,這就是測試時間擴展方法(Test-time scaling),也是s1-32B採用的方法。
為訓練模型,史丹佛大學團隊先根據難度、多樣性和品質,篩選出1,000個樣本,這些樣本包括問題、模型推理過程和答案,集結起來就是s1K資料集。接著,他們開發預算強制(Budget forcing)方法,在測試期間(也就是模型使用期間)強制控制運算量,比如當模型想太多時,提早終止思考來減少推理步驟、產出答案,或是強迫模型延長思考,在模型要結束輸出時,多次加入「Wait」來讓模型繼續推理,來自我修正推理步驟。最後,他們用s1K資料集來監督式微調Qwen2.5-32B-Instruct模型,得出s1-32B模型,以16張H100 GPU和26分鐘完成訓練,花費約20美元。(詳全文)

Hugging Face 多模態模型 SmolVLM
號稱業界最小多模態語言模型來了
AI資源平臺Hugging Face最近發布兩款新多模態模型SmolVLM-256M和SmolVLM-500M,前者號稱是全球最小的多模態及影片語言模型(VLM)。進一步來說,256M和500M模型都使用SigLIP作為圖片編碼器,以SmolLM2為文字編碼器,來共同運作。
其中,SmolVLM能勝任多種多模態任務,包括生成圖片描述或短影片字幕、PDF或掃瞄文件問答,以及回答圖表問題。這種模型架構輕巧,適合用於行動裝置應用,同時維持強大效能。其中,256M是最小型的VLM多模態模型,它能接受任何序列的圖片和文字,生成文字輸出,能以不到1GB的GPU RAM對單一圖片推論。若要更高效能,則可選擇SmolVLM-500M模型,在單一圖片上推論僅需1.23GB的GPU RAM。二款模型微調後表現更好。(詳全文)

推理模型 Open-R1 DeepSeek
Hugging Face要打造推理模型Open-R1
DeepSeek-R1模型發布以來,因其相對低廉的硬體和訓練成本展現良好推理能力,如數學、程式開發與科學領域的推理能力,引發社群關注。不過,DeepSeek-R1只開源了模型權重,並未開源資料集和訓練程式碼,因此Hugging Face啟動一項專案,要根據DeepSeek公布的研究內容,進行逆向工程,打造一款名為Open-R1的開源版本,希望在透明、可驗證的環境下,讓研究社群能更深入了解這項技術,如關鍵架構、訓練步驟,以及在有限硬體資源下達到高效訓練的方法。
Hugging Face團隊的做法,是先分析DeepSeek發布的技術報告與模型論文,並從現有權重中,推斷其訓練配方和資料分布。再來,Hugging Face將召集志願者,共同整理出可公開使用的高品質推理資料,藉此復刻或接近DeepSeek-R1所使用的多階段訓練策略。Open-R1若順利出爐,還可能在技術透明度和研究價值上,超越原始模型,供任何人檢閱並改良強化學習流程、語言模型結構和推理邏輯。(詳全文)
OpenAI o3-mini ChatGPT
OpenAI推理能力模型o3-mini正式推出
OpenAI最近揭露,小型推理模型OpenAI o3-mini已部署到ChatGPT和API,供付費方案用戶及開發人員使用。這款o3-mini保有OpenAI o1-mini的低成本和低延遲特性,但進一步加強小模型的效能和速度,具備優異的STEM(科學、數學和程式撰寫)能力,在AIME 2024數學標竿測試中,o3-mini-high推理能力等級模型得到87.3,優於o1-preview的56.7、o1-mini的63.6。
對開發者而言,o3-mini和o1-mini一樣,也支援串流,而且有低、中、高三種推理能力可選擇,用於不同場景。OpenAI指出,o3-mini能整合搜尋功能,可提供即時網頁答案及連結。不過,目前o3不支援視覺功能,需要的用戶還是得繼續使用o1-mini。o3-mini已部署到ChatGPT和API,包括API使用層級3到5特定開發人員的Chat Completions API、Assistants API及Batch API。(詳全文)
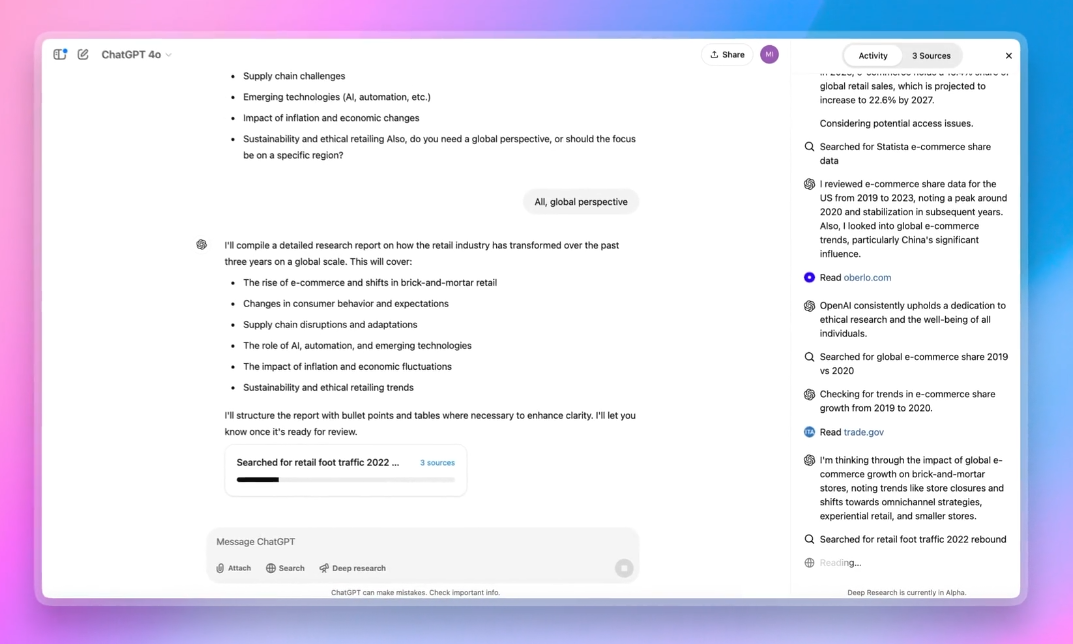
Deep Research OpenAI 搜尋工具
OpenAI推強大搜尋研究工具Deep Research
最近OpenAI推出Deep Research功能,可整合網路上大量分散資訊,自動執行多步驟研究、產出報告結果。進一步來說,該系統利用端對端的強化學習技術,經大量困難瀏覽與推理任務的訓練,學會自主規畫、執行多步驟資訊搜尋流程。
這個功能不只能繪製圖表、嵌入網站圖片,還能精確引用來源文字,滿足研究報告對技術與細節的需求。而且,Deep Research內建Python工具,能動態生成圖形,並將分析結果嵌入最終報告,可大幅降低人力負擔。OpenAI評估顯示,在Humanity's Last Exam這項涵蓋多領域專家級問題的測試中,Deep Research達到26.6%準確率,比其他先進的語言模型,如OpenAI o3-mini_high的13.0%、DeepSeek-R1的9.4%、OpenAI o1的9.1%還要好。
Deep Research目前供Pro用戶使用,未來將逐步擴展至Plus、Team與Enterprise等更多使用者。OpenAI表示,未來還將新添Deep Research功能,來連接更多專業訂閱資源和內部資料庫。(詳全文)
LLM DeepMind 複雜任務
不必轉化為數學模型,LLM也能良好解決複雜問題
日前,DeepMind發表Mind Evolution技術,結合了大型語言模型(LLM)和演化式搜尋方法,解決傳統方法在自然語言規畫與推理任務中的效率和準確性瓶頸。這個研究的特別之處在於,語言模型可直接用來處理複雜問題,且解決能力非常好,不必先將問題轉化為數學模型。
團隊表示,LLM在處理複雜自然語言規畫和推理任務仍有限制,比如旅行規畫或行程安排等情境,傳統方法容易受限於局部搜尋,或難以將問題轉換為明確的數學模型,影響了解題效果。於是,DeepMind設計一套演化式搜尋策略,結合隨機探索和深度最佳化,可生成、重組、改進候選解方。這個方法能在短時間內,大幅提高解題準確性,還能應對自然語言描述中,隱含的約束和需求。而且,這個方法還不需要一一檢查每個中間推理步驟,大幅降低運算成本。
DeepMind還以旅行規畫、行程安排及隱寫術生成(Steganography)等高難度的自然語言任務,來測試Mind Evolution。結果顯示,Mind Evolution在TravelPlanner與Natural Plan基準測試的成功率在95%至100%間,遠遠超過傳統的最佳解搜尋與逐步修正策略。(詳全文)
圖片來源/國網中心、數發部、史丹佛大學、Hugging Face、OpenAI
AI近期新聞
1. 行政院要求公務機關全面禁用DeepSeek AI服務
2. Google Gemini 2.0 Flash Thinking供所有用戶測試
3. Anthropic預計替Claude加入雙向語音模式
資料來源:iThome整理,2025年2月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10