Mistral AI發表全新語言模型Mistral Saba,這是一款針對中東與南亞市場設計的高效能、小型化區域語言模型。Saba擁有240億參數,專注於阿拉伯語與多種印度語言的理解與應用,並且在效能與推理速度上取得平衡,相較於更大規模的模型,能夠以較低的計算資源提供準確的回應。Mistral AI強調,這款模型不僅可以透過API存取,還支援本地部署,以滿足企業對於資料隱私與安全性的需求。
一般大型語言模型雖然支援多語言,但往往缺乏對於特定語言的深度理解,特別是在文化脈絡、專業術語與語法細微差異方面。而Saba的訓練採用來自中東與南亞地區的高品質資料集,使其在這些市場的實際應用能夠提供更自然、精確的語言處理能力。
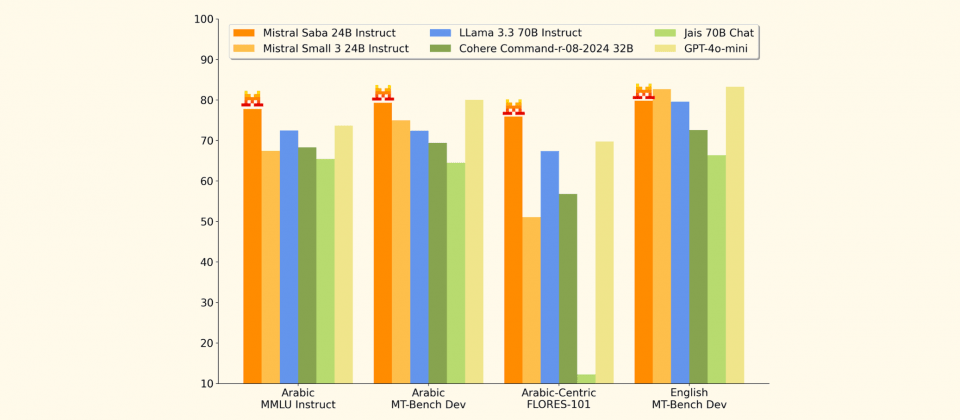
根據Mistral AI公布的基準測試結果,Saba在阿拉伯語的大規模多任務語言理解測試(MMLU)表現領先,甚至超越部分擁有700億參數的模型,同時推理延遲明顯更低,能夠在單個GPU硬體環境下達到每秒150 Token以上的生成速度。這對於希望在有限計算資源內,部署大語言模型的企業來說,是一個重要的優勢。此外,Saba也支援微調,企業可依據自身需求進一步調整,強化其在金融、能源、醫療等特定領域的應用。
Mistral AI近期的模型發布傾向於輕量化和本地部署語言模型,與目前市場上競爭者普遍推出的超大規模雲端模型策略不同。除了Saba這款針對中東與南亞市場設計的區域語言模型,Mistral AI也積極與企業合作,訓練專屬語言模型,以滿足特定產業需求。這種策略不僅強調更細緻的語言最佳化與本地化能力,也讓人工智慧模型能夠在有限的計算資源下高效執行,增加企業在資料隱私、安全性及應用靈活性方面的選擇。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-09

2026-02-06