走進臺灣大學德田館302室,這裡是臺大資工所「機器發明及社群網路探勘實驗室」以及「網路探勘與資訊檢索實驗室」的共用研究室。這間看似一般行政辦公室的房間,卻是臺灣少數進行網路社群探勘研究的根據地,而這間研究室的研究生,今年同時獲得Yahoo Open Hack Day開發競賽優勝和趨勢科技騰雲駕霧百萬程式競賽冠軍。
臺灣大學資訊工程所賴弘哲、陳健文和交通大學資訊科學與工程所吳嘉祥所開發的「Location Plus!」服務,擊敗了其他38組作品獲得Yahoo開發競賽的優勝,而賴弘哲和陳健文更是趨勢百萬程式大賽的冠軍團隊成員。 臺灣大學資訊工程所賴弘哲、陳健文和交通大學資訊科學與工程所吳嘉祥(由左至右),運用雲端運算技術Hadoop分析20萬篇批踢踢BBS文章來打造「Location Plus!」服務。
臺灣大學資訊工程所賴弘哲、陳健文和交通大學資訊科學與工程所吳嘉祥(由左至右),運用雲端運算技術Hadoop分析20萬篇批踢踢BBS文章來打造「Location Plus!」服務。
Location Plus從大量的批踢踢BBS文章中,找出臺灣17個城市的熱門話題,每個城市提供30個熱門話題和相關的參考詞,可以讓使用者用這些熱門話題來搜尋Yahoo知識+、生活+、無名小站等內容,此外,也提供了手機版介面,讓使用者到任何地方就知道當地有哪些熱門話題。
打造Location Plus服務的關鍵技術Hadoop,正是Google和Yahoo所使用的開源雲端運算技術。
Hadoop屬於Apache基金會的頂級開源計畫之一,源自Google在2004年提出的MapReduce運算方法,原本這是用來開發搜尋引擎的技術,後來因為Hadoop具有強大的分散運算能力,遂成為軟體大廠競相採用的雲端技術,包括Google雲端運算學術計畫、IBM的Blue Cloud計畫、趨勢科技的網路防護技術等都有採用。
Yahoo更是直接聘用Hadoop創辦人Doug Cutting,在Yahoo內部大量導入Hadoop來處理各種網路使用記錄的分析。
Location Plus開發團隊正是利用了Hadoop超強的運算能力,來分析各種網路上的龐大資料,例如數GB資安Log記錄、2千萬筆Plurk噗文、20萬筆批踢踢BBS文章等,再使用分析的結果來打造應用程式的功能。
以獲獎的Location Plus服務為例,開發團隊原本計畫要以批踢踢BBS站文章、Yahoo新聞和社交網站Plurk的發言記錄,從這三類資料中找出每個地區的熱門話題。
今年六月時,陳健文先蒐集了三個月份的Plurk發言記錄,包括80萬名使用者資料、2千萬筆發言和1億筆回應,總共約30GB的資料量。他利用這些資料先測試各種資料探勘方法的可行性。
測試結果發現,在不同的演算法程式中,Hadoop需要數倍,甚至數百倍的儲存空間來暫存運算過程的資料,處理Plurk資料需要的磁碟空間超過了現有伺服器的3TB容量,陳健文必須重新修改演算法和程式才能解決。所以,十月正式比賽時,他們決定先使用資料量較少的批踢踢BBS文章來尋找各地熱門話題。
| 開
發 概 要 |
Location Plus! ●功能簡述:提供17個縣市的熱門話題,可作為網站內容的搜尋條件 ●開發成員:賴弘哲、陳健文、吳嘉祥 ●執行環境:Java、Linux、4部Dell PowerEdge 2950二路四核心伺服器 ●關鍵技術:Hadoop框架、PlaceMaker元件、BluePrint元件 ●使用資料:20萬篇批踢踢BBS文章、30萬筆維基百科詞條 ●網址:Locationplus.chienwen.net  |
用Hadoop執行600億次比對
賴弘哲和陳健文所屬的實驗室平時就會定期蒐集批踢踢BBS站的十大熱門看板的文章,主要透過RSS訂閱功能,蒐集任何人所發表的文章內容,以及這些文章的推文回應,再儲存於資料庫中方便做進一步的使用。長期下來,資料庫已累積了大約20萬筆文章記錄,每天還持續增加數百篇文章。
陳健文利用維基百科提供的30萬筆詞條作為關鍵詞,搜尋每一個關鍵詞在20萬篇文章中的出現次數,再按照出現次數的多寡由高到低排序。這個30萬筆詞條和20萬篇文章的比對任務,至少需要600億次的文章全文搜尋。
這項600億次的搜尋工作,賴弘哲說:「若使用一臺2.5GHz的雙核心桌上型電腦來運算,至少要執行10個小時才會有結果。」
他們使用實驗室購買的四部Dell 2950伺服器(二路四核心)來執行Hadoop程式。用一臺作為分配任務的Master伺服器,而其他三臺作為運算用的Slave伺服器,其中Master伺服器的記憶體有6GB,而其他三臺則只有4GB。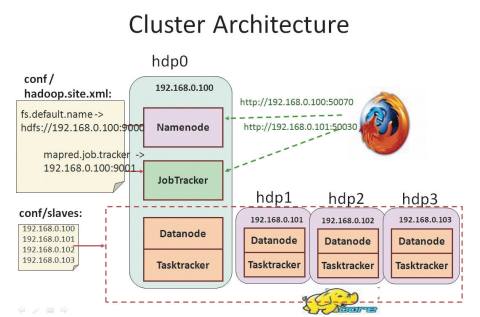
Location Plus使用4部Dell 2950伺服器來運算,hdp0擔任Master管理運算任務,其餘三臺(hdp1,2,3)扮演Slave執行運算。資料來源:賴弘哲、陳健文,iThome整理,2009年11月
賴弘哲表示:「Hadoop能支援異質的執行環境,每一臺伺服器的硬體規格不同也沒關係。」
不過,Hadoop目前只支援Java語言,賴弘哲先在四臺伺服器中建置好Java執行環境,同時在每臺伺服器的Linux作業系統中,建立一個免用密碼登入的共用SSH帳號,作為Master伺服器和其他Slave伺服器溝通之用。
完成環境設定後,先將Hadoop程式(包括Map程式、Reduce程式和30萬筆維基詞條檔案)以及設定檔複製到每一臺伺服器的相同目錄下。再將要分析的20萬筆批踢踢文章資料放入Hadoop的NameNode虛擬檔案系統中。賴弘哲表示,為了簡化程式處理,他們將20萬筆批踢踢文章全部存在一個檔案中,每一行是一篇文章,不同欄位如作者、標題等,再用Tab字元隔開。
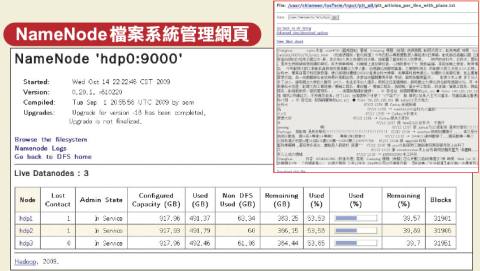
NameNode的使用方法就像是一般電腦中的階層式檔案目錄一樣,不同之處是NameNode會自動切割使用者傳入的檔案,再分散到不同Slave伺服器中的HDFS檔案目錄中。這項分散作業是自動執行,使用者不需了解底層系統如何運作,也不會知道資料最後儲存到哪些地方。
最後,在Master伺服器中啟動Job Tracker工具來執行Hadoop程式,Job Tracker會自動啟動其他Slave伺服器上的程式,依據設定檔進行分散運算。
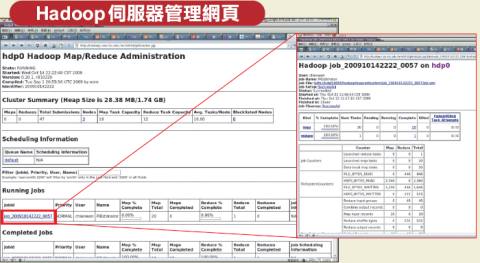
Hadoop提供了一套網頁介面的管理系統,可讓開發者追蹤每一臺伺服器的執行情形。Master伺服器隨時監控Slave伺服器的Heart Beat訊號,若超過幾百秒未回應時,這代表Slave當機,Master會重新將運算任務分配給其他Slave伺服器。
儘管Location Plus只使用了4臺伺服器,但賴弘哲表示:「執行過程中隨時可以增加新的伺服器,只要將新機器的IP加入Master配置檔的伺服器清單,在Hadoop執行下一個任務時,就會啟動新增的伺服器,不過,若是大幅變更配置檔,就必須關閉Hadoop重新執行。」
運算結束後,Hadoop會將執行結果儲存在HDFS檔案目錄中,開發者同樣可以透過NameNode的get指令取回,就像使用FTP下載檔案一樣。Key-Value傳值是分散運算的關鍵
陳健文指出,Hadoop能夠做到分散運算的關鍵有兩個原因,第一點是資料上傳到HDFS檔案目錄時,系統自動會進行資料分配,爾後,每臺Slave伺服器只需要運算儲存在本地端的部分資料就好,不需要互相存取其他Slave伺服器上的資料。
另一個原因是採用Key-Value傳值方式的MapReduce運算方式。陳健文解釋,分散運算分成兩個階段,在Map程式中會先讀取全部30萬筆的維基詞條,然後將逐項比較每一篇文章是否出現這些詞條。
例如有一個詞條是「電腦展」,Map程式先讀進一篇批踢踢文章,搜尋文章中是否有「電腦展」這個詞條,若有,則 Map程式會送出("電腦展","1")的傳回值,前者「電腦展」就是Key,而1就是Value。如此反覆比較過20萬篇文章後,就會得到一堆Key-Value的成對結果,每一組都是代表Map程式找到的一個詞條和文章的關係。
Reduce是分散運算的第二階段,每一個Key都有一個對應的Reduce程式(實際是同一支Java程式,但是Index參數是每一個不同的Key),例如Reduce("電腦展")這支程式,就會自動收集所有Map傳回的Key-Value結果,再將這些結果的Value加總起來,就是20萬篇文章中有出現「電腦展」這個詞條的文章數量。
同樣道理,Reduce("正妹")就會計算出現「正妹」的文章數量。Value也可以設計成代表其他意義,例如傳回的Value是文章編號,那就可以蒐集到哪幾篇文章有談到「正妹」,而不只是統計數量而已。陳健文設計的Value就組合了四種資訊。
陳健文指出,因為Map-Reduce的程式架構,可以將原本複雜的比對工作拆解成各自獨立的程式,交由不同的Slave伺服器來處理,達到分散式運算的效果。「這是一種不同的程式設計思維,但其實並不難,只要經過訓練就會使用。」他說。
透過Hadoop找出維基詞條在BBS文章中的出現頻率後,賴弘哲再使用TF-IDF演算法(Term Frequency-Inverse Document Frequency)來計算每一個詞條的熱門程度,並使用Yahoo提供的PlaceMaker API來找出和每一篇文章相關的地理位置,例如臺北市、桃園等,將地理位置作為修正TF-IDF演算法公式的參數之一。最後,賴弘哲就可以找出每一個地區最熱門的話題有哪些。
PlaceMaker API會分析傳入文章的內容,找到內文中和地點或地理有相關的資訊,例如台北、大安區、高雄,甚至是知名景點、建築物,如中正紀念堂都可以辨識。Yahoo是透過搜尋引擎記錄累積這些與地理相關的資訊,支援17種語言,包括中文。而且使用時沒有像斷章取義API有每天2千字的限制。
所以,陳健文可以用PlaceMaker一次找出20萬筆的BBS文章,每一篇文章中的地點資訊,PlaceMaker還會傳回一個涵蓋這些文中地點的概括位置,例如文章中有台北和高雄,PlaceMaker就可以傳回「臺灣」的位置。賴弘哲正是在重要性的TF-IDF演算法公式中加入這項地理資訊。
運算時間加快20倍
賴弘哲表示:「原本十小時的分析過程,使用Hadoop雲端技術後,只需要半個小時就能完成。」正因為大幅縮短了運算時間,所以,賴弘哲才能在短短24小時的比賽時間中,反覆進行了十次測試,依據這些測試執行結果來調校演算法,找出最有效的熱門話題。
最後,陳健文統計熱門話題和其他詞條共同出現在文章標題的次數,找出最常一起出現的相關詞。在網頁上畫出地理區、熱門話題和相關詞的語意網絡,作為使用者查詢Yahoo網站內容的搜尋條件。
吳嘉祥則負責打造手機版本,他將Hadoop計算出來的熱門話題清單和搜尋結果打包成XML檔,再傳送到Yahoo的BluePrint服務來產生支援各種手機螢幕規格的輸出畫面,讓使用者透過手機搜尋各地熱門話題的網站內容。
未來,賴弘哲希望能進一步分析比賽時來不及處理的兩千萬筆Plurk資料,結合Plurk的位置資訊,讓Location Plus能即時提供在地人自己的熱門話題內容。文⊙王宏仁
|
管理Hadoop雲端運算環境其實不難 |
| 雲端運算框架Hadoop提供了方便的網頁版管理介面,讓開發者監控各伺服器的執行情形,以及每一個運算任務的處理進度,另外還提供了NameNode瀏覽網頁,可以管理分散式檔案系統上的資料。
|
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06

2026-02-09
")
2026-02-09

")