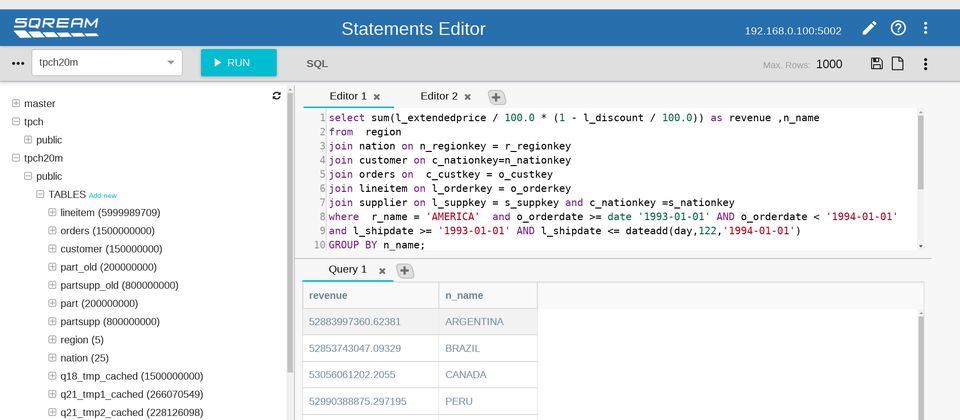
若要加速大型資料倉儲系統的存取速度,我們會想到的解決方案,可能有下列幾種:導入大規模平行處理系統(Massively Parallel Processing,MPP)的架構,或是搭配記憶體內資料庫(In-Memory Database),然而,這兩類產品的軟硬體建置成本並不低,前者需配置多臺伺服器一起運作,也將佔用資料中心的空間,後者也有記憶體容量配置的上限,市面上,是否還有其他適合的解決方案可供選擇?
今年,我們看到漢領國際引進一套能對應上述需求的產品,稱為SQream DB,它是一種GPU加速資料倉儲系統,在去年9月推出3.0版,資料載入速度是先前版本的2倍,而在資料查詢的部份上, 針對多張資料表的連結(multi-table joins),以及非重複數量統計(count distinct)的作業速度,新版可達到15倍的提升。
到了3月,SQream公司改變了這套產品的版號命名規則,定為「年.主要版號.次要版號.修補版號」格式,目前釋出的最新版本是 2019.1.2。
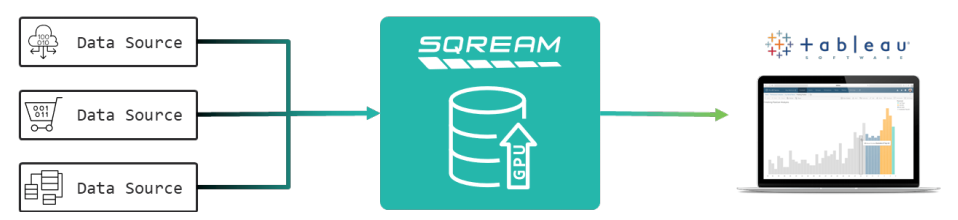
SQream是在2010年成立於以色列特拉維夫,該公司花了3年以上的時間,在2014年10月宣布推出主要產品SQream DB,當時的定位是大數據分析SQL資料庫。到了2017年8月,SQream DB發布 1.17版,聚焦在多節點安裝的部份,提供新增功能與改善措施,強調可填補大規模平行處理系統與記憶體內資料庫之間的鴻溝。
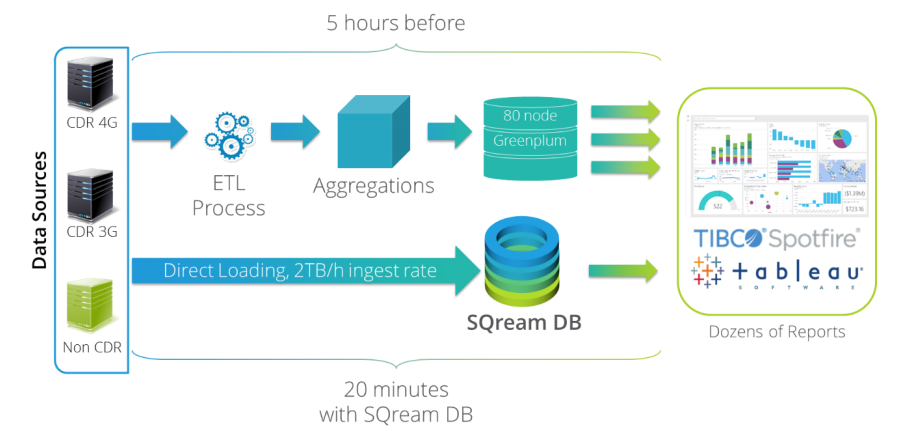
這套資料庫系統之所以著重在GPU加速,不只是因為它擁有大量運算核心,同時也看重它的記憶體頻寬,可提供極大的資料吞吐能力,同時執行多個複雜的任務。
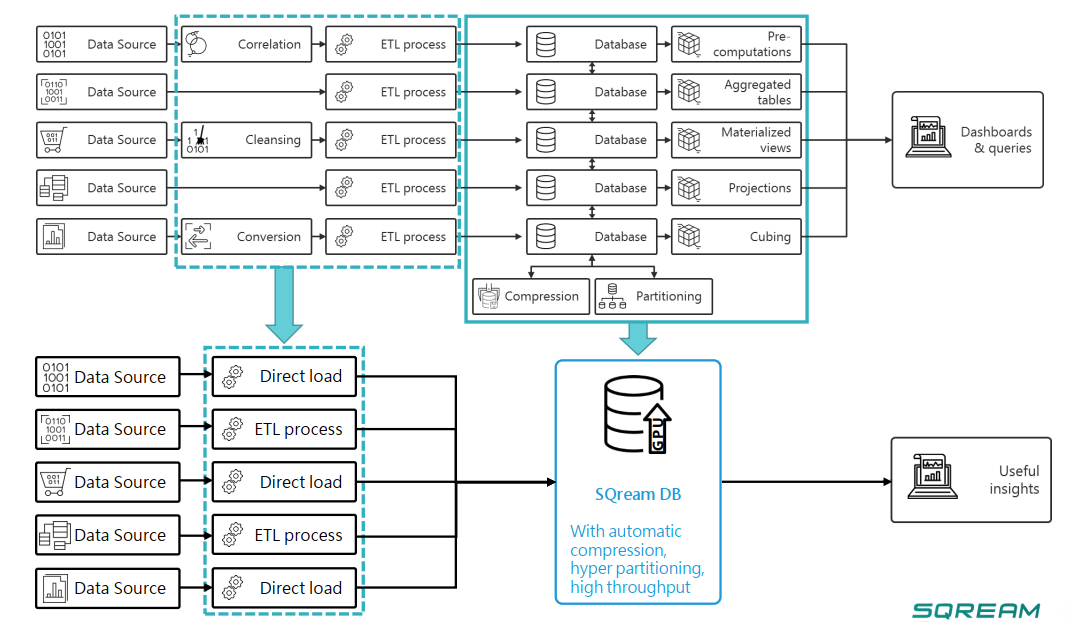
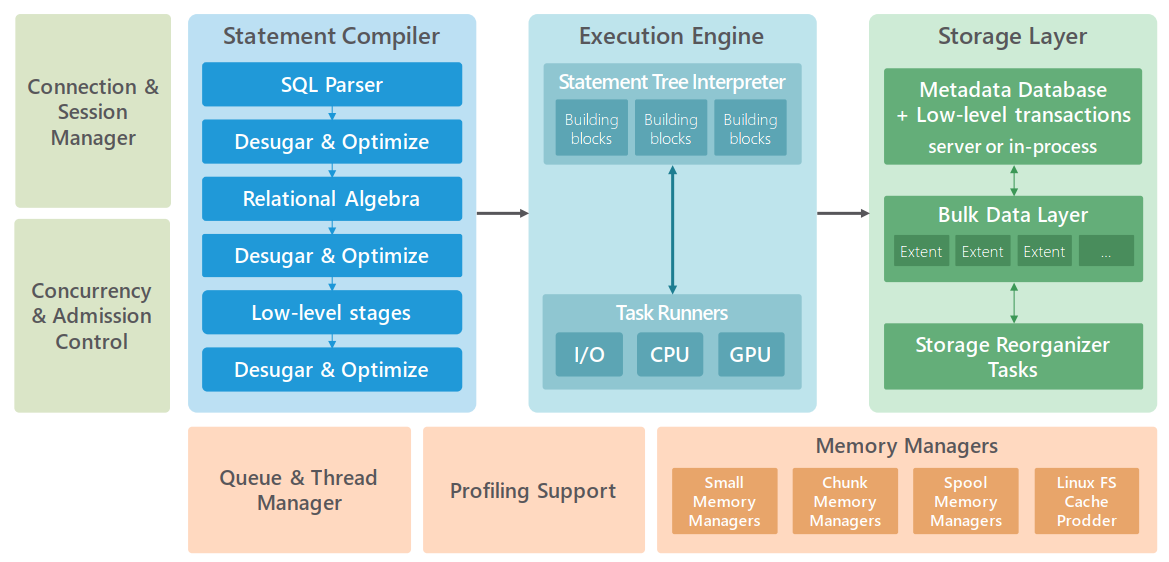
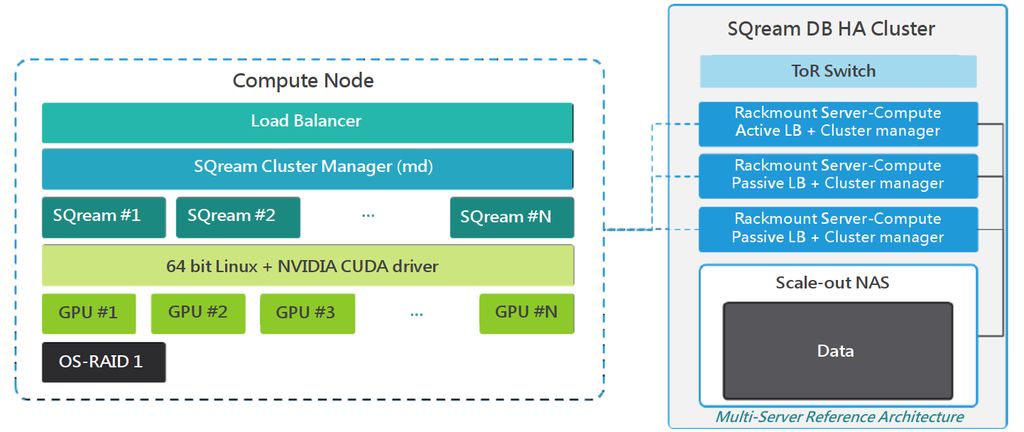
從系統元件的組成來看,SQream DB包含4大部分──SQream DB Daemon(sqreamd)、SQream SQL Editor、SQream Statement Editor、SQream Dashboard,值得注意的是,在安裝指南的文件特別提到,伺服器端必須安裝Nvidia CUDA的驅動程式,由此可知,這套資料庫系統需在搭配Nvidia GPU加速卡的伺服器環境下執行。
採用獨特的資料處理與儲存架構,可縮短載入大量資料的時間
而在資料存放的架構上,SQream DB採用的是直欄式(columnar)儲存引擎,能將所要處理的資料進行垂直與水平的分割,便於支援繁重的資料分析處理工作,像是連結、彙整(aggregations)、分類(sorting)。
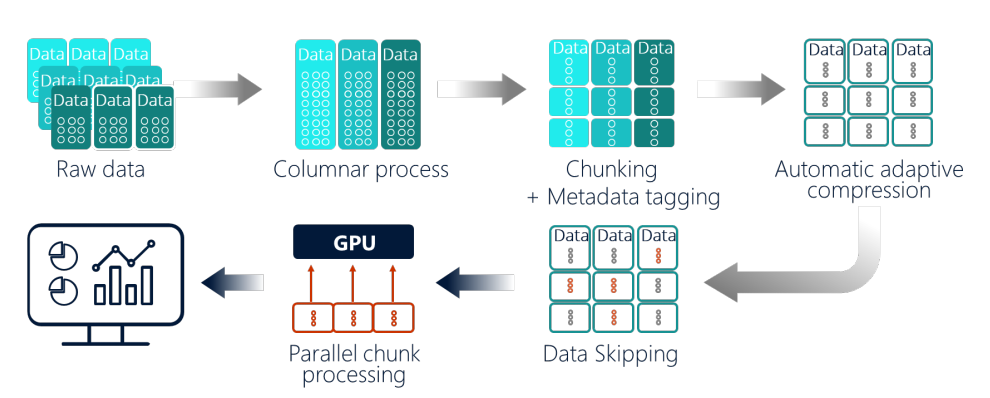
所謂的水平切割,是針對原始資料進行直欄式的切割處理(Columnar Process),讓指定查詢作業能夠存取到特定欄位下的子集合資料,相較於標準的列式儲存(row storage),這種作法可減少磁碟掃描與記憶體I/O存取,而且相當適合GPU這類擅長平行運算的技術。
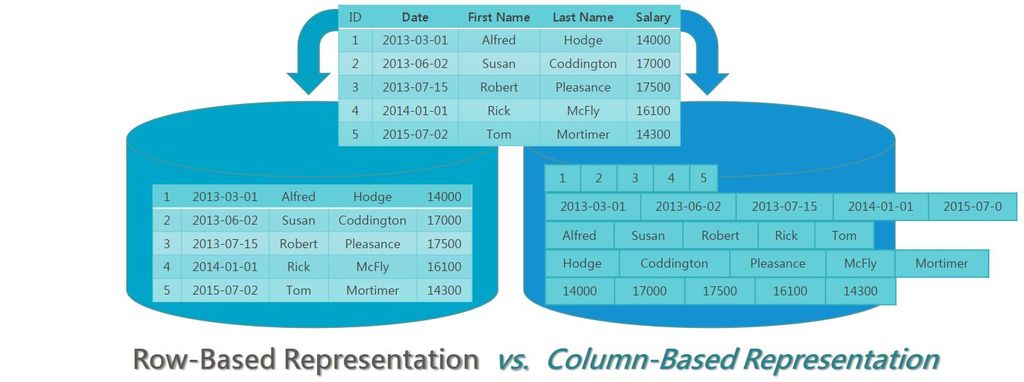
另一種水平分割,是將上述垂直切割後的資料,再進一步分割為資料塊(chunks),如此可提升硬體資源的使用效率,像是相對容量較小的GPU記憶體,使其能夠進行排存(spooling)與快取。
資料塊:資料表的超分割(hyper-partitioning)
基本上,所有存放在SQream DB的資料表,會自動分割成多個資料塊,而每個資料塊包含了幾百萬個資料點(data point),之後,這些資料塊會經過壓縮,佔用的儲存空間只需幾MB,不需手動介入或維護。
換言之,每張資料表的列會分散在多個資料塊當中,而且是橫跨多個欄位來存放,而由於資料塊很小,若要經由PCI匯流排傳輸到GPU當中處理,會比較有效率。
同時,這裡所採用的壓縮演算法,會根據不同類型的資料而調整(例如,需依循資料所在地的規則)。一旦資料發生變更,這套自動調適壓縮演算法也會針對特定的資料塊,來決定最佳的壓縮方式。
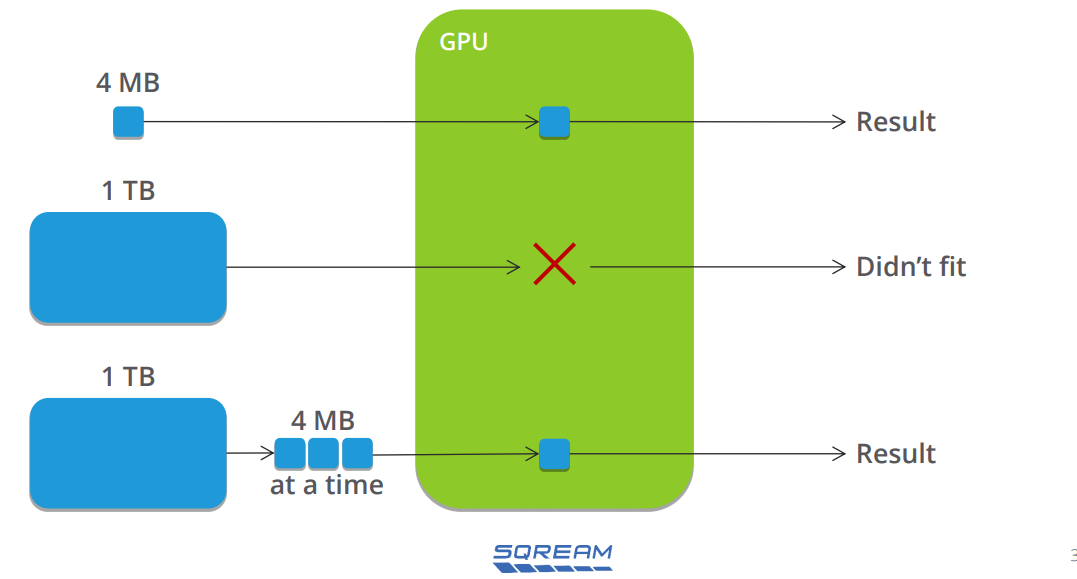
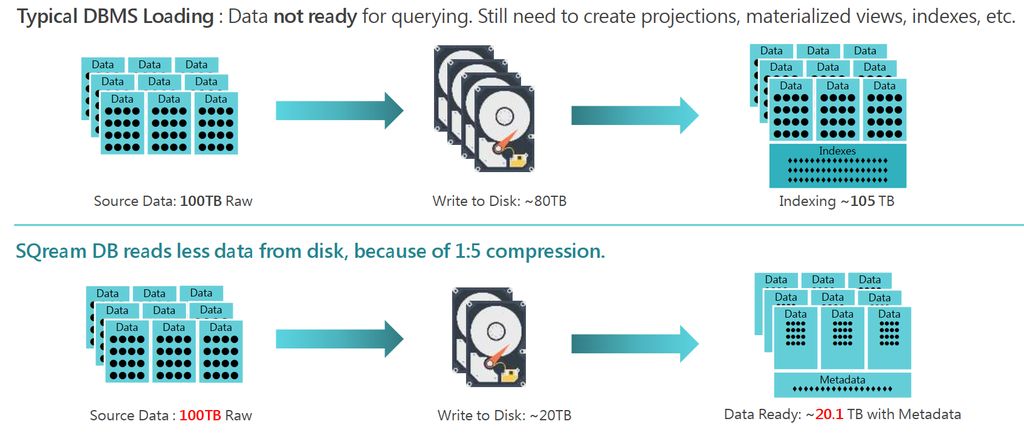
基於這樣的架構,使用者查詢所有資料時,就如同面對一張普通的資料表,同時,又能因應一般資料庫儲存需求快速成長的挑戰。而根據SQream的估算,若從多個外部來源載入資料的作業而言,這套GPU加速資料倉儲系統在資料提取(Data Ingestion)的部分,以每張GPU加速卡為單位時,可達到每小時3.3 TB的存取效能。

中繼資料存取:zone map、資料省略
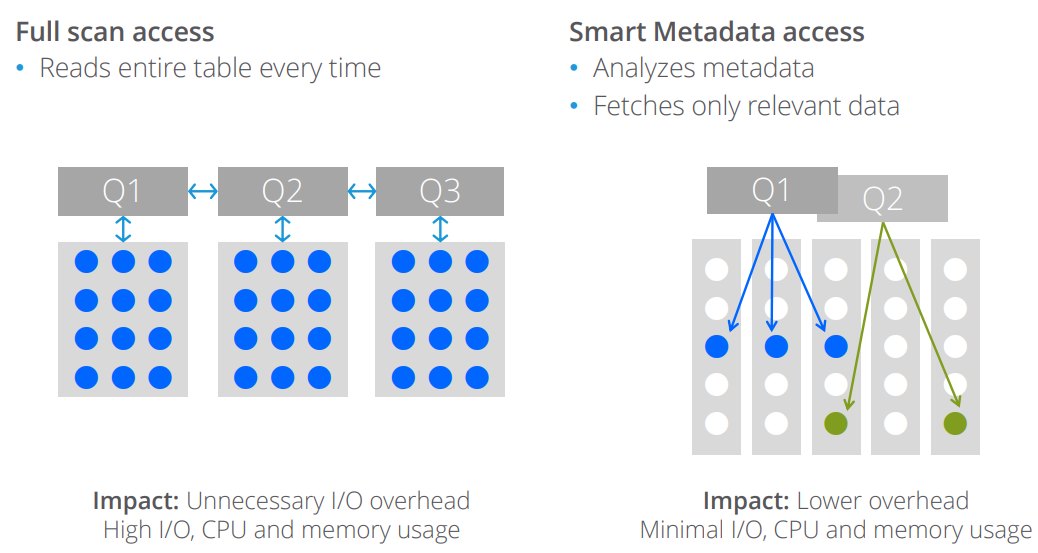
在吸取資料(ingest)的當下,SQream DB也會針對存放在資料塊的全部資料列,來收集與儲存中繼資料(metadata),裡面包含了納入資料的數值與屬性範圍。而在中繼資料儲存到系統之際,也會與壓縮的資料塊區隔開來。
關於此種metadata的處理方式,一般稱為zone map,已有一些資料庫系統採用。有別於標準的索引機制之處在於,metadata是從資料塊自動收集而來,且透明地橫跨所有資料類型與欄位;同時,也不會佔用太多容量,這邊的中繼資料收集只會佔用1%的儲存空間;此種作法也有助於資料查詢速度的提升,因為經過計算的zone map,可允許資料修剪(data pruning)或資料省略(data skipping)的處理,毋須讀取無關的資料;若要刪除老舊資料,也能受益於這種技術而變得更容易。
舉例來說,在SQream DB執行資料查詢時,系統會查看中繼資料的型錄,並且排除那些zone map被辨識為無關查詢的資料塊。也就是說,從磁碟讀取資料時,能夠因為我們在SQL指令當中輸入的Where子句,或是連接一些關鍵欄位(key)時,而不需載入查詢範圍以外的部分。

針對所有的資料欄位,SQream DB會自動收集中繼資料,其中,對於數值型的資料處理上,可獲得最佳效益。一般而言,多數資料庫的資料表都有某種時戳或日期的記錄,這類資料通常使用了某種升冪排序的方式,而在SQream DB的系統上,當資料納入SQream DB資料表時,系統會填入資料塊,並在資料塊置入特定日期之際,新的資料塊將會帶入同樣或新的日期而建立。
舉例來說,如果我們要查詢橫跨10年的大量歷史資料時,只想分析某日的其中一個小時,在SQream DB的系統當中,就只會掃描該份資料表的1/24;如果想要查看10年期間、每年12月24日的其中一個小時,SQream DB只會掃描資料表的1/8760。換言之,若進一步僅指定相關欄位,SQream DB就能夠讀取範圍更小的資料。
針對時間序列型的資料,有了這種層級的刪減技術,系統即使面對指定範圍的查詢,甚至是規模非常大的資料表,仍能夠更快產生出處理的結果,而不需仰賴大型與繁重的索引機制。
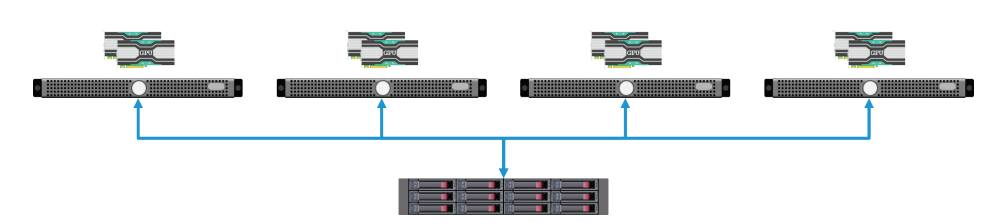
支援多種擴充系統處理規模的做法
此外,若要以縱向擴充(Scale Up)和橫向擴充(Scale Out)等方式,來提升GPU的運算規模,只需在伺服器端換裝或加裝GPU加速卡,比起純CPU的伺服器系統,相對容易擴充運算規模。
可運用較多人擅長的SQL語法來進行查詢,並且支援多種資料來源、程式語言、圖像報表平臺
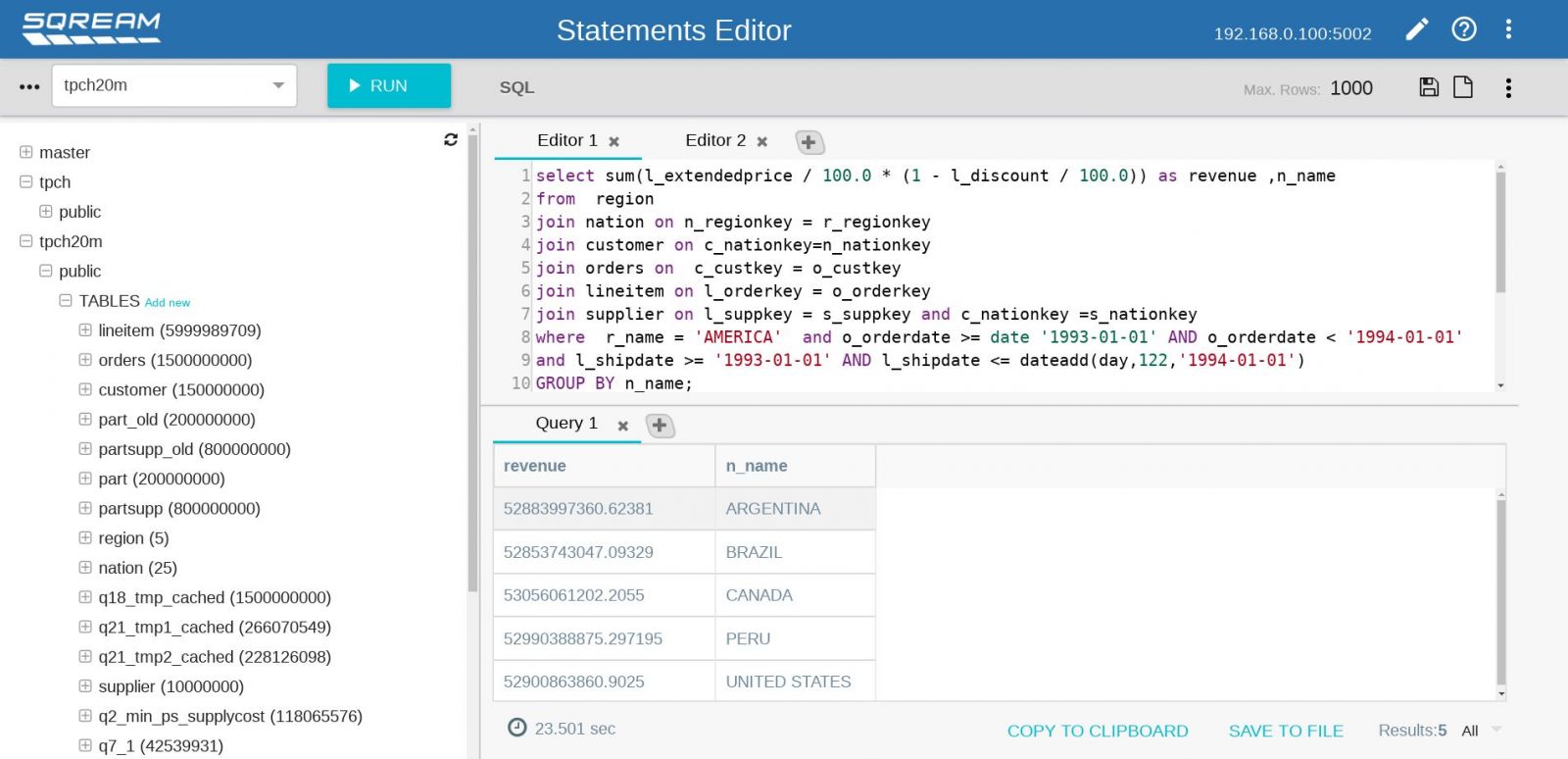
另一個SQream DB吸引企業用戶的賣點在於,它本身是一套相容於ANSI SQL標準(ANSI-92)的關聯性資料庫,開發人員可使用普及、熟悉的SQL語法來進行資料查詢,而不像導入其他資料庫或資料倉儲系統,須重新學習語法才能操作。
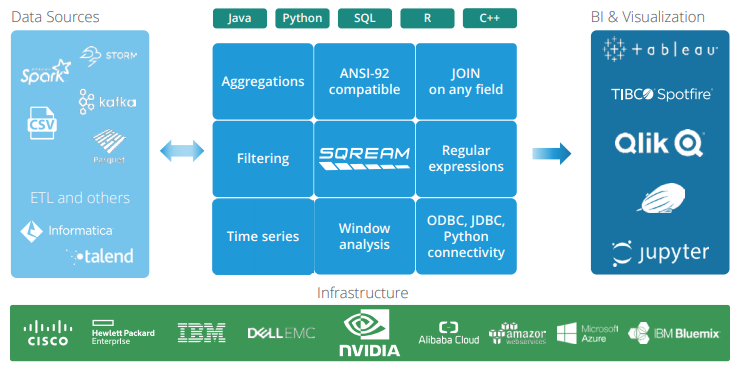
SQream DB目前支援的資料來源,相當廣泛,可以順利整合公司既有的資料儲存方式。原廠提供了多種驅動程式、連接器,可涵蓋ODBC、JDBC、Python、Node.JS、Java、C++等應用程式開發環境,而能存取Apache Kafka、Apache Spark等大數據系統,同時,也能支援通用檔案格式,像是CSV檔,以及Hadoop環境下的直欄式儲存格式Apache Parquet,以及Infomatica等商業智慧軟體廠商的ETL工具。
產品資訊
SQream DB 2019.1.2
●代理商:漢領國際(02)2709-6983
●建議售價:廠商未提供
●硬體需求:2顆8核心Xeon E5-2600 v4系列或POWER9、128GB記憶體(對應每張GPU加速卡)、2張Nvidia Tesla K80/P40/P100、存放作業系統2臺100GB SSD(RAID 1)、加速排存2臺400GB SSD(RAID 1)
●儲存配置:主要儲存區為10臺600GB SAS介面硬碟或SSD(RAID 5或6),外部SAN/NAS儲存:配合每張GPU加速卡的儲存吞吐量為500 GB/s
●作業系統需求:64位元Linux(CentOS 7.3、Ubuntu 16.04、Amazon Linux 2017.03)
●系統安裝方式:Docker(Docker CE 18.03、Nvidia Docker2)、RPM
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-06

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-06
")
2026-02-09