
自從2016年Nvidia推出第一款整合式AI應用設備DGX-1以來,隨著GPU架構世代更迭而推出新機型之餘,也陸續開展出工作站DGX Workstation,以及可堆疊10臺DGX系統的DGX BasePOD、串聯140臺DGX系統的DGX SuperPOD,陣容越來越壯大,而在今年5月底舉行的台北國際電腦展期間,他們宣布這個產品家族又將有新的成員,那就是運算能力與規模更加強大的AI超級電腦系統DGX GH200。
為了突顯此套系統對於大型企業的吸引力,Nvidia也預告Google Cloud、Meta、微軟將是第一批存取這項技術的公司,以此探索用於生成式AI工作負載的功能,Nvidia後續將對雲端服務廠商與大型資料中心環境,提供DGX GH200的設計藍圖,以便針對他們本身的IT基礎架構環境進行相關的調整。
除此之外,Nvidia本身正在建置的新一代超級電腦Helios,也將採用4套DGX GH200系統,它們之間是透過Nvidia Quantum-2 InfiniBand網路產品進行互連,預計今年底上線。這套系統將支援Nvidia發展的地球氣候模擬數位雙生雲服務Earth-2,在7月初舉行的柏林地球視覺化運算高峰會期間,Nvidia表示,他們正在建置的三種超級電腦開始上線運作,DGX GH200系統正是其中之一,負責模擬物理特性。

採用融合Arm架構CPU與Nvidia資料中心GPU的運算模組,搭配NVLink Switch System的I/O互連架構
較於既有的DGX System產品都是採用x86架構處理器、獨立的Nvidia資料中心GPU,搭配Nvidia發展的NVLink、NVSwitch,以及現行的I/O介面與乙太網路、InfiniBand連線環境而成,DGX GH200最大的突破,是改用Nvidia研發的融合式晶片GH200 Grace Hopper Superchip,以及高速I/O交換系統NVLink Switch System而成,同樣可用於現行的資料中心網路環境。
比起目前的整櫃式高效能運算叢集系統產品,DGX GH200另一個賣點是能夠更直接提供超大規模、高速存取的GPU共享記憶體空間,當中借助NVLink Switch System的架構,提供的NVLink頻寬可達到前代DGX系統的48倍,而能透過NVLink連結256顆GH200超級晶片,促使如此大規模系統所具備的運算資源,能以單一GPU的形式供應用戶操作。
相較之下,前代DGX系統在多顆GPU以NVLink串聯成單一GPU使用,若不希望影響運算效能,最多只能同時連接8顆GPU。
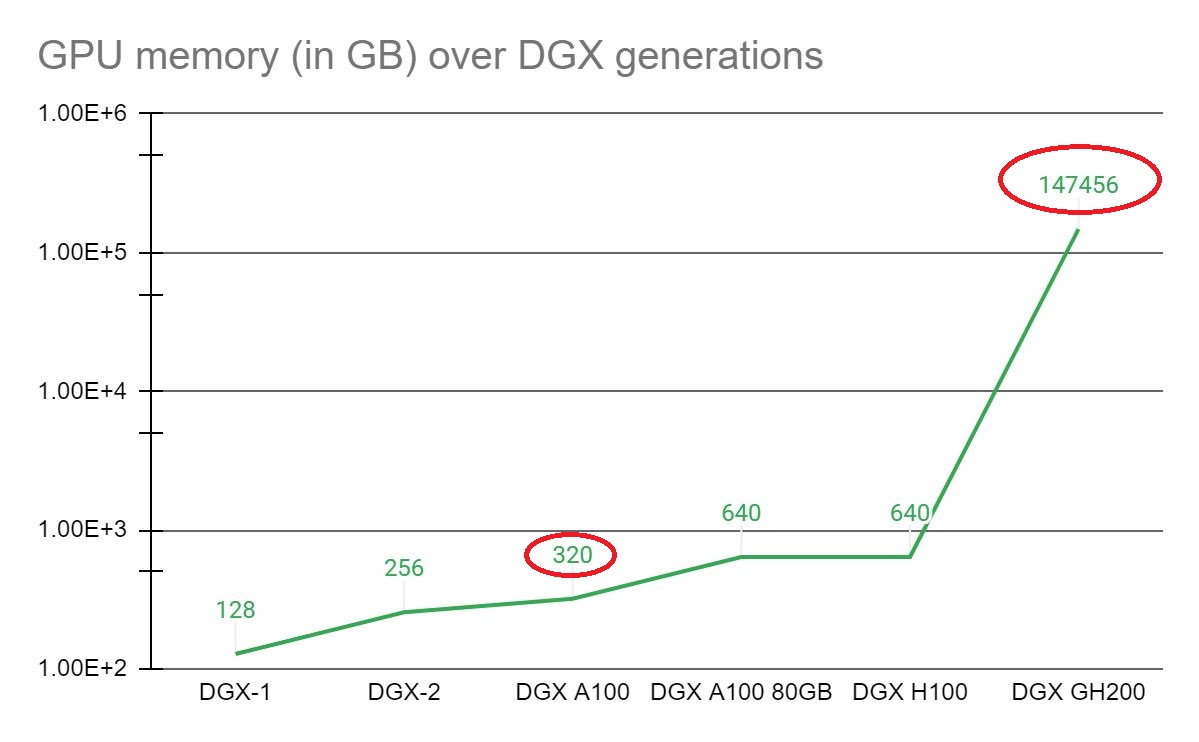
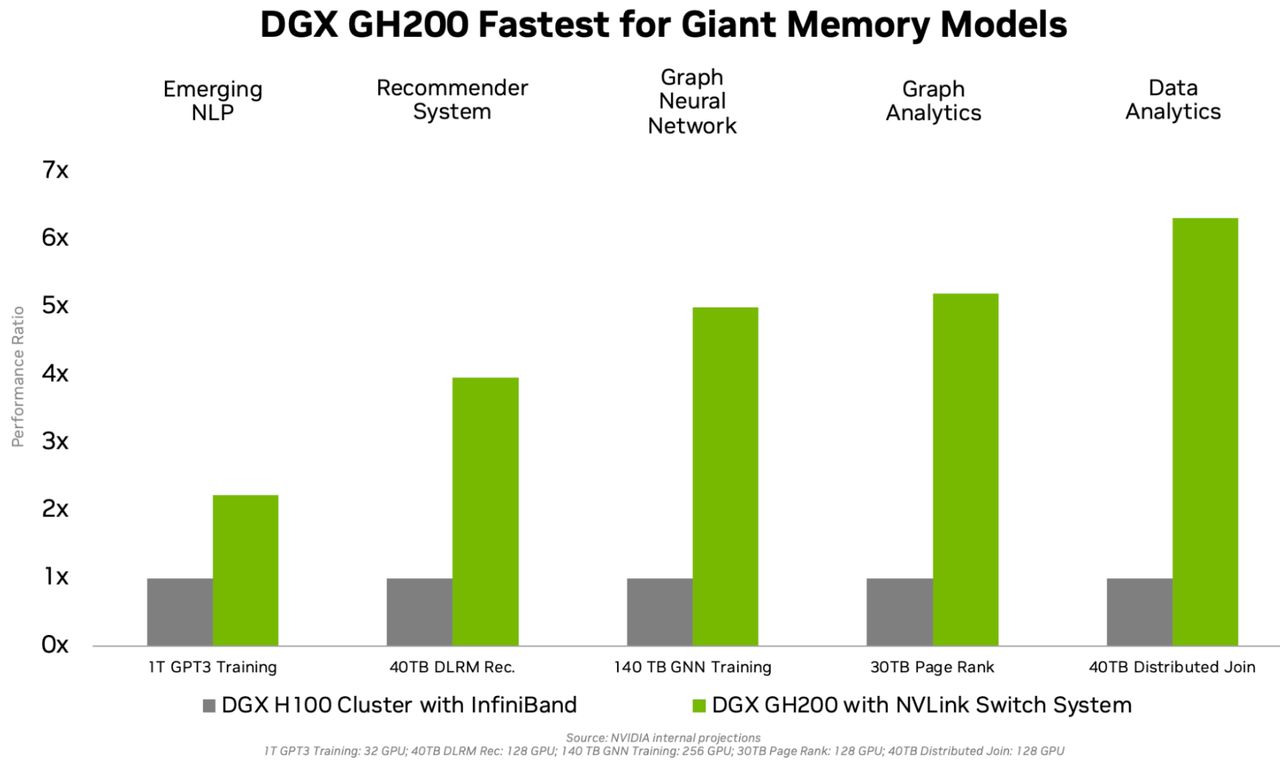
Nvidia表示,單臺DGX GH200系統可提供1 Exaflop的運算效能,以及144 TB的GPU共享記憶體,若以2020年推出的DGX A100(搭配40GB記憶體的A100)為基準,DGX GH200系統的GPU記憶體容量可達到近5百倍。
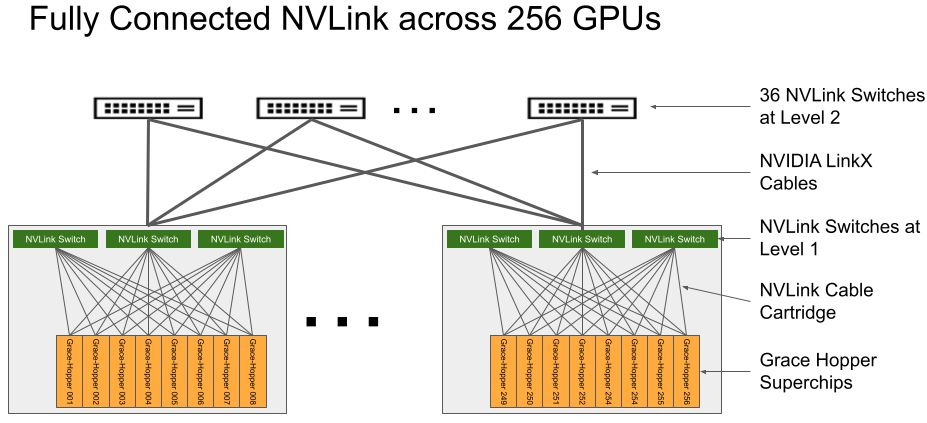
若要了解DGX GH200何以提供如此強大的運算能力,需細部檢視其組成方式。根據Nvidia在網站公布的白皮書指出,它總共包含256臺運算模組插槽,以及1套NVLink Switch System,形成兩層式的NVLink連結架構。




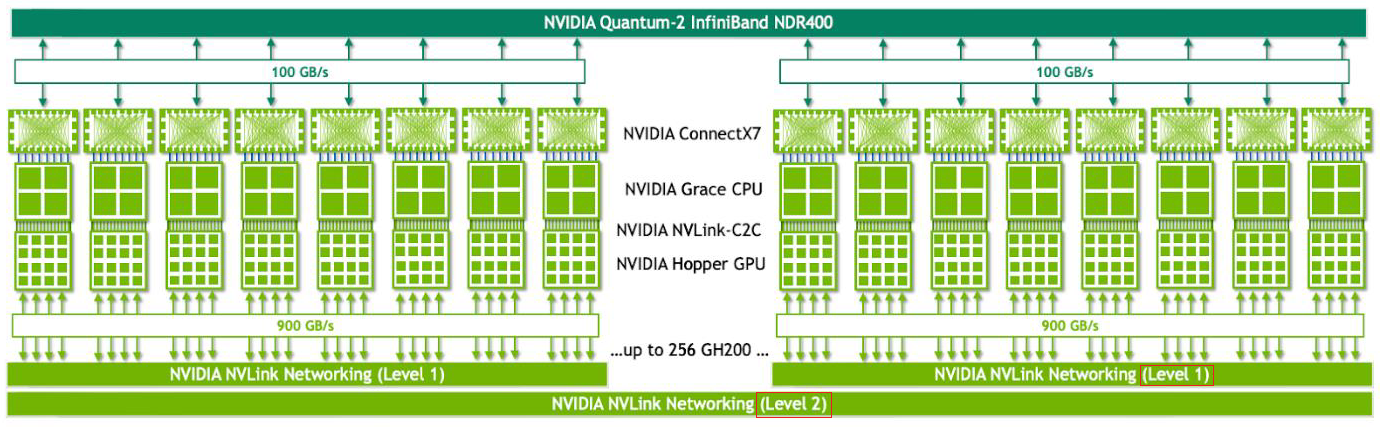
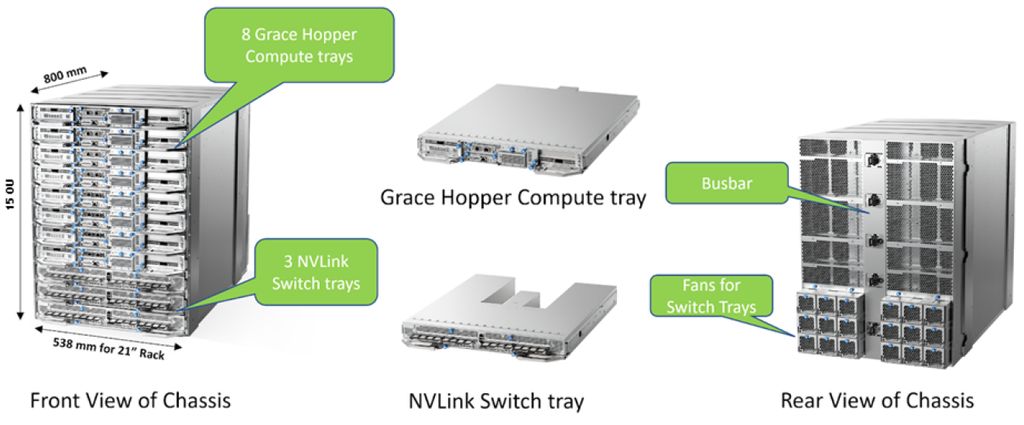
基本上,每臺運算模組包含單顆GH200 Grace Hopper晶片,網路元件(由Nvidia乙太網路或InfiniBand網路卡ConnectX-7,以及資料處理器BlueField-3組成)、伺服器管理系統(基板控制器)、用於存放資料與作業系統檔案的固態硬碟。接著再將8臺運算模組連接3臺第一層NVLink NVSwitch模組,形成一座容納8顆GH200的機箱,

值得注意的是,關於這部分運算堆疊設備的組成,是由ZT Systems這家伺服器廠商所設計出來的。Nvidia共同創辦人暨執行長黃仁勳在Computex主題演講當中,針對MGX模組化伺服器架構介紹多家合作廠商時,特別提到ZT Systems基於此架構而成的產品,正是Nvidia Grace Hopper人工智慧超級電腦的運算Pod,他的意思是ZT Systems的這類型產品就是DGX GH200的運算Pod,而在ServeTheHome的相關報導與ZT Systems的臉書與LinkedIn貼文,以及Nvidia公布的DGX GH200白皮書公布的照片,也與這個說法呼應。
而每一臺NVLink NVSwitch模組可透過LinkX傳輸線材,連上盲接纜線連接器與第二層NVLink Switch。以DGX GH200整個系統而言,可透過36臺第二層NVLink Switch連接32座上述容納8顆GH200的機箱,因此,單臺系統總共可支配256顆GH200晶片。

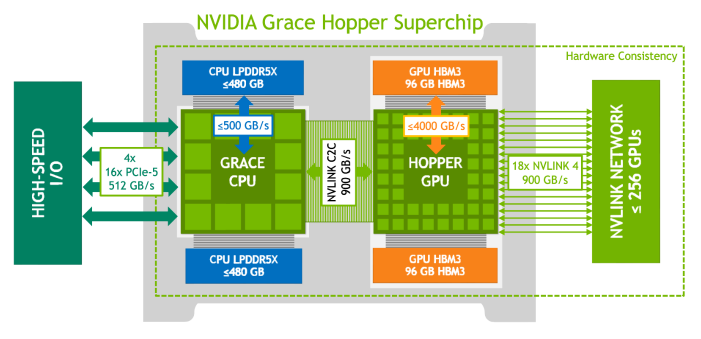
而144 TB共享記憶體容量是從何得來的?根據Nvidia公布的Grace Hopper Superchip規格來看,每顆晶片包含中央處理器Grace,以及圖形處理器H100,前者是由72顆Arm Neoverse V2核心組成,最多可支援480 GB容量的LPDDR5X記憶體,後者最多可配置96 GB容量的HBM3記憶體,由於同處於單一晶片封裝的Grace與H100之間,可透過頻寬高達900 GB/s的NVLink-C2C介面連接,使得H100也能共享Grace所能存取的記憶體,因此,以單顆Grace Hopper Superchip晶片而言,最多可用到的記憶體容量達到576 GB,而串連256顆GH200晶片的DGX GH200,最多可存取的記憶體容量達到147,456 GB,也就是144 TB。
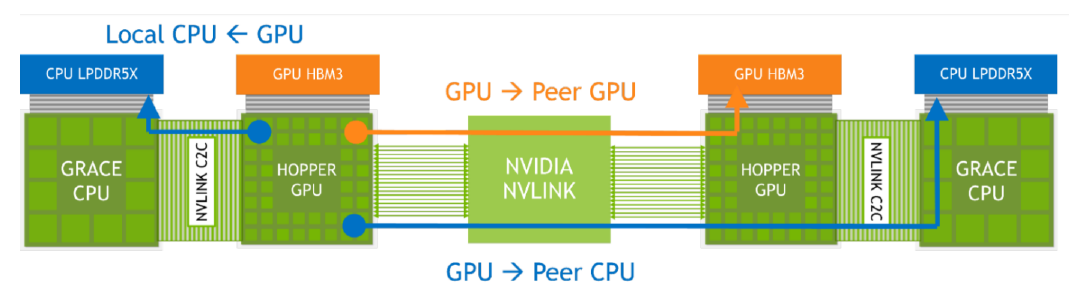
由於同處於單一晶片封裝的Grace與H100之間,可經由NVLink-C2C介面連接,由於此介面具備7倍於PCIe 5.0的I/O頻寬(雙向頻寬為900 GB/s),以及耗電量僅需PCIe 5.0的五分之一等特性,使得H100能以高速,以及高能源效益的方式共享Grace所能存取的記憶體,因此,以單顆Grace Hopper Superchip晶片而言,最多可用到的記憶體容量達到576 GB,而串連256顆GH200晶片的DGX GH200,最多可存取的記憶體容量達到147,456 GB,也就是144 TB。
沿用Nvidia長期發展的AI與資料應用軟體堆疊架構,以及SaaS雲端管理服務
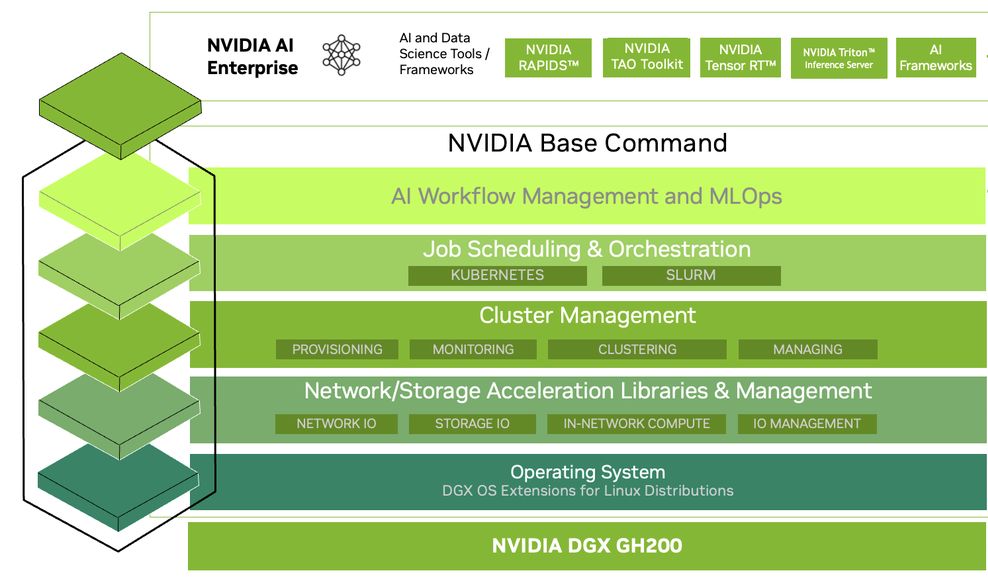
除了提供強大的運作性能與規模擴展特性,DGX GH200也受惠於Nvidia持續培養與開發的各種加速與不同領域應用的軟體解決方案,而能因應大型AI與資料分析的工作負載,用戶可搭配企業級軟體套餐Nvidia AI Enterprise,利用裡面提供超過100種框架、預先完成訓練的機器學習模型,以及開發工具,得以快速發展與部署電腦視覺、語文辨識處理與生成式AI等正式應用。
在此同時,企業與組織也能運用Nvidia代管的雲端軟體平臺Base Command,管理AI工作流程、叢集環境運作、進行加速處理的儲存與網路程式庫、已針對AI工作負載完成效能調校的系統軟體。
產品資訊
Nvidia DGX GH200
●原廠:Nvidia
●建議售價:廠商未提供
●整體架構:256臺GH200 Grace Hopper運算插槽(32座8-GPU機箱)、1座NVLink Switch System(96臺L1 NVLink NVSwitch、36臺L2 NVLink NVSwitch、2304 LinkX光纖纜線)
●8-GPU機箱規格:8臺GH200 Grace Hopper運算插槽、3臺NVLink NVSwitch插槽,機架高度15 OU
●運算插槽組成:1顆GH200 Grace Hopper Superchip晶片(72顆Arm Neoverse V2核心,Nvidia H100 GPU,GPU記憶體為576 GB,融合96 GB HBM3與480GB LPDDR5X)、網路元件(1張400 Gb InfiniBand網路介面卡ConnectX-7、1張資料處理器BlueField-3或ConnectX-7,提供頻內網路200GbE或儲存網路200 Gb InfiniBand)、1套管理系統(BMC)、4臺NVMe固態硬碟(2臺2.5吋U.2外形4TB容量,用來存放資料、RAID 0備援,2臺M.2外形2TB容量,用來存放作業系統、RAID 1備援)
●NVLink NVSwitch組成:2顆第三代NVSwitch ASIC晶片,支援第四代NVLink
●系統軟體組成:作業系統為Nvidia DGX OS、Ubuntu、Red Hat Enterprise Linux、Rocky,雲端管理平臺Nvidia Base Command、AI軟體套件為Nvidia Al Enterprise
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞


2026-02-16


2026-02-13

2026-02-16


2026-02-16
