| Anthropic | Claude | LLM可解釋性 | AI推理機制 | AI安全性
Anthropic公開新研究揭示LLM的內部思考機制
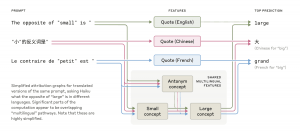
Anthropic發表兩項研究,揭露大型語言模型Claude的推理與生成路徑,顯示其具概念普遍性與前瞻規畫能力,替人工智慧可解釋性提供實證基礎
2025-03-31