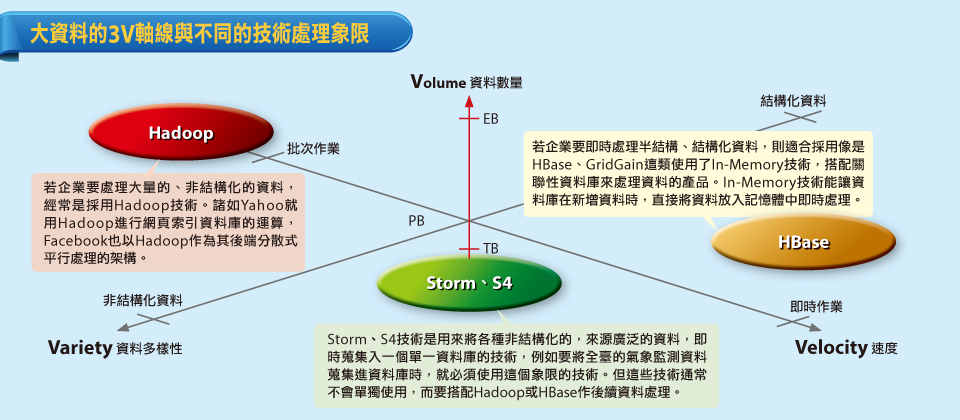
雖然大資料處理的技術,可說是百家爭鳴,但是國家高速網路與計算中心副主任周立德認為,可以從大資料的數量(Volume)、速度(Velocity)、多樣性(Variety)三個軸線展開,來談各種技術的特色,和其合適的應用情境。「數量」指的就是總資料量,「速度」則指資料處理是否要求即時性,而「多樣性」則是指資料來源、格式的歧異度,舉例來說,從社群網站擷取下來的資料,可能就包括了文字、照片、以及聲音、視訊串流等不同的非結構化資料,此外,各種生產機臺產生的工作日誌,也是非結構化資料的例子。
雖然大資料技術蓬勃發展,但遺憾的是,至今並沒有一種技術、產品能夠面對又大量,多樣性又高、即時性要求又快的資料。因此周立德認為,企業應該從自己的業務需求開始,重新檢視自己面對的資料特性,是要處理大量的資料?是有即時性的資料處理需求?或是要處理多樣化的資料格式?確定了企業要面對的資料特性,再從中選擇適合的技術,才能真正解決資料處理的瓶頸。
不同的資料處理要求,有不同的技術可供選擇
了解了大資料的3種特性之後,就可以開始討論能夠滿足各種需求的技術,以及其原理了。周立德指出,若企業要處理大量的、非結構化的資料,則經常是採用Hadoop技術。諸如Yahoo就用Hadoop進行網頁索引資料庫的運算,Facebook也以Hadoop作為其後端分散式平行處理的架構,此外,Twitter也採用了Hadoop作為其檔案系統的技術之一。
然而,若企業要即時地處理半結構、結構化資料,則適合採用像是HBase、GridGain這類使用了In-Memory技術,搭配關聯性資料庫來處理資料的產品。In-Memory技術能讓資料庫在新增資料時,直接將資料放入記憶體中,讓使用者能對新增的資料做即時的處理,也因為記憶體的高存取速度,能達到幾近即時的反應。周立德表示,諸如證券交易、土石流預警應變系統等,都因為對即時性的要求,而適合採用這類型的資料處理技術。
周立德認為,企業必須評估自己的業務需求,看自己面對的資料,是落在數量、增加率、多樣性交織下的哪一個象限,最後再依成本考量,選擇最合適於自己的技術。批次資料處理機制在傳統上行之有年,由於是以硬碟作為資料儲存的第一關,成本也較低廉。不過在另一方面,即時處理也已逐漸成為企業的要求,其中最常被引用的就是In-Memory技術。記憶體的I/O存取速度比起硬碟,可以快到100倍到1,000倍,若是以隨機資料存取(Random Access)行為來作比較,則甚至可以快到10,000倍以上,因此,資料處理的速度也比傳統的批次處理機制快。
批次資料處理的機制:以Hadoop為例
Hadoop對大量資料的批次處理,可分為3個主要階段,在第1階段,大量資料會直接平行寫入多臺機器的硬碟,預備後續的處理,這是第1次的硬碟寫入。接下來第2階段是資料處理階段,使用者必須透過系統排程,預先提交運算任務,並等待特定的排程時間,排程到臨時,系統會將資料從儲存設備中載入記憶體,並傳送至處理器進行運算,而處理器的運算結果會再寫回資料庫,等到使用者要調用資料時,再從硬碟中讀取資料出來,這是第3個事件處理階段。
從以上的3個步驟看來,資料從進入系統,到被使用者調用出來,總共經歷了2次的硬碟讀寫過程,因此速度會相對緩慢。不過,批次資料處理的優點,在於其能以低廉的價格購置硬碟,以平行化方式達到大量資料快速暫存,同時,由於資料進入到系統的同時,也進入了硬碟當中,即使運算過程中有斷電發生,也不會影響資料的正確性。
即時資料處理的機制:以HBase為例
HBase是用In-Memory技術搭配結構化資料庫,來處理即時的結構化資料。首先,在資料收集的階段,資料就是直接寫入到記憶體中,而非先寫入硬碟,接下來,使用者可以撰寫共同處理器(Co-Processor)中的程式碼,事先決定在何種時機點(例如有資料新增的時候)進行所指定的運算。而每隔一段固定時間,Hbase就會將記憶體中較不常用的的快取資料,定時寫入本機硬碟,而常用的資料則會隨時因適當條件觸發,迅速送入處理器進行運算,而運算結果也能直接從處理器中調用。
在資料處理的階段當中,資料的流向可以分成2個部份,常用的資料會快取在記憶體內,每當事件觸發,則立刻移至處理器內進行運算。而記憶體中較不常用的資料,則會周期性地寫入硬碟,以空出更多的記憶體來儲存常用資料。因為寫入硬碟的動作是周期性地判斷是否有常用資料,除此之外,整個流程並不會進行硬碟I/O的存取,因此能夠以極快速的速度回應即時的資料調用、處理。
不過,跟批次資料處理相較起來,前端的資料是全數先直接寫入到記憶體內,因此若要處理龐大的資料量,則必須建置大量的記憶體來對應,相較於批次資料處理用硬碟來存放前端資料,其成本會較高,除非將一部分沒有即時需求的資料移至硬碟存放。此外,在In-Memory架構的設計中,由於資料只會定期寫入硬碟,因此一旦系統斷電,還未進入到硬碟的資料就會消失,造成無可挽回的後果。周立德表示,Google能夠在3秒內分析1PB大量資料的Dremel技術,也包含了In-Memory技術,並運用了大量的平行運算,達到大量資料的即時處理效果,此外,Dremel也藉由In-Memory的技術以及資料庫演算法的彈性設計,來達到漸進更新(Incremental Update)的效果,也就是說,若原本的10,000份資料要再加入10筆資料,則不必重新索引,即可在之後的查詢調出這10,010筆資料的關連性。
批次資料處理與即時資料處理,各有適用的應用領域,周立德指出,企業應謹慎評估自己的業務需求以及成本考量,讓這兩種機制能在面對不同資料的情境下,都能各自有效發揮。
即時資料處理 vs. 批次資料處理
用In-Memory機制實現的即時資料處理,由於不必經過冗長的硬碟I/O存取,能夠比傳統的批次機制更快速地處理資料。但由於大量使用記憶體作為資料暫存媒介,其成本也比傳統的批次處理機制要高。
此外,由於In-Memory在資料蒐集階段,就直接將資料平行快取至記憶體內,而在之後的資料處理階段,直接被處理器調用,只有一些不常用的資料會周期性地存入硬碟中,因此一旦系統發生斷電,所有快取在記憶體中的資料都會消失,相反地,批次處理會再資料蒐集階段就將資料存入硬碟內,因此即使發生斷電,也不會有資料流失之虞。
![]()
即時資料處理流程:以HBase為例
在HBase的即時資料處理機制中,資料會直接寫入到記憶體中,使用者可以事先決定在何種時機點(例如有資料新增的時候)進行運算。每隔一段固定時間,系統都會將記憶體中較不常用的的快取資料寫入硬碟,而常用的資料則會因適當條件觸發,迅速送入處理器進行運算。
![]()
批次資料處理流程:以Hadoop為例
在Hadoop的批次資料處理機制中,大量資料會直接平行寫入多臺機器的硬碟,接下來,使用者必須透過工作排程,預先提交運算任務,並等待特定的排程時間,排程到臨時,系統會將資料從儲存設備中載入記憶體,並傳送至處理器進行運算,處理器的運算結果會再寫回資料庫,使用者要調用資料時,再從硬碟中將資料讀出。
![]()
國網中心副主任周立德認為,批次與即時資料處理有各自的應用領域,企業應謹慎評估業務需求,讓這兩種機制能在面對不同資料的情境下,都能有效發揮。
如何打破資料處理技術的極限
許多新技術、新思維都在大資料的浪潮下的應運而生,然而,現行的軟硬體架構逐漸無法因應大量、高即時性與多樣性的資料要求,而其根本的解決之道,仍要回歸到運算效率的本身
對於大資料的3種特性:數量(Volume)、速度(Velocity)、多樣性(Variety)漸增的要求,人類是否有著最終的解答?什麼是推進資料處理技術的根本動力,是必須依靠運算媒介的改變,還是軟體設計、演算法仍有改良的可能?要因應大資料的3V,最終仍要回歸到運算效率的提升,效率提升了,就能以更即時的速度,處理更大量的資料,同時能對不同的資料來源、資料格式做處理。
雖然長久以來,資料處理速度已經達到了前所未有的高度,但事實上,不管是來自學界、業界的要求,都越來越難以被現有的資料處理技術滿足。清華大學資工系副教授李哲榮舉例,如學界知名的RSA加密演算法破解計算,即使以現在最高端的軟硬體資料處理技術,仍然很難在一個可接受的時間內完成,此外,對於一些高維度(High Dimensional)的運算、非線性(Non-Linear)的資料分析,例如要在一群巨量的資料群中尋找資料的相關性、以特定條件對資料做分類等,都不是現行的運算架構可以輕易解決的問題。
新的製程方式與媒介,也許能夠提供一種解答。李哲榮認為,下一代的運算媒介有可能提供一條新的出路,諸如量子電腦、生物電腦、以及3D FinFET電路的製程,可以讓電晶體的密度大幅提升,雖然這些技術仍在研究階段,但都為更快速的大資料處理帶來了一線希望。
不過李哲榮同時也提醒,運算媒介的改變,最多只能達到線性的加速,加上目前有太多技術上的不確定性,尚無法真正替資料處理帶來真正的速度增加。華碩雲端公司總經理吳漢章則認為,在現行運算媒介下改變演算法設計,是目前最有效的解決辦法。以In-Memory技術為例,記憶體和處理器在I/O表現上的速度,比起硬碟、記憶體間的傳輸速度還要快上數百、數千倍,因此,若能搭配合適的演算法,資料處理速度的提升,理想上應該能達到千倍的效果。
李哲榮認為,資料處理的進步不是依靠單一的硬體技術改革,或是演算法新設計,而是必須在軟硬體發展至一個成熟階段後,才可能帶動整體資料處理技術的革新。例如平行演算法的普及,是得力於平行電腦硬體架構的成熟,以及其製造成本的降低。而如果不是因為目前資料傳輸和硬碟的I/O速度與計算單位間的速度越差越大,In-Memory計算技術也不會受到關注。李哲榮指出,平行運算和In-Memory技術很早前就有人在研究了,只是因為硬體發展趨勢,直到今天才形成主流最後,吳漢章和李哲榮都不約而同的認為,人類的「需求」才能真正驅動技術的推進,而這也許才是打破資料處理技術的重要原因。
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05