
網路上充滿各式內容的影片,對使用者來說,最好可以快速知道影片有不有趣,而對於微軟Bing影片搜尋功能來說,問題則是如何提供影片概覽,幫助使用者決定是否要花時間點擊並觀看影片。微軟提到,提供影片摘要是非常困難的工作,不像人類可以直覺的指出影片的主場景,電腦難以内化這類內隱知識或遵照一個概括的規則辨識。
影片摘要分為動態摘要與靜態摘要,動態摘要是將影片切割成數個小區間,選取或是組合一段固定時間長的重要片段,供使用者預覽,微軟表示,他們有資料指出,80%使用者注視縮圖的時間少於10秒,也就是說,使用者並沒有太多的耐心觀看預覽,最後微軟採用了靜態摘要方法。
微軟Bing中提供的影片靜態摘要,除了一個主要縮圖代表影片外,在影片下方還會呈現4張縮圖,讓使用者一眼就可以看出影片大致內容。首先第一步,要為影片產生主縮圖,而為了訓練機器學習模型分辨好或壞的縮圖,微軟從影片中隨機挑出30幀畫面,並交給人類評委,以主觀喜好評估這些畫面,考量代表性、圖像品質以及吸引力等屬性,為畫面打分數,分為3個等級可以為0、0.5或是1分。
除了使用人工製造的訓練資料,微軟也使用了大量來自這些圖像的特徵,來訓練增強樹回歸模型(Boosted Trees Regression Model),這個模型使用這些資料推測影片上的其他畫面,並且輸出0到1之間的分數,來幫助後續選出最佳的影片縮圖。微軟提到,採用圖像的特徵非常廣泛,包括對比度、模糊度、雜訊等級等核心圖像品質特徵外,還有使用臉部偵測,以偵測圖像臉部數量、臉部大小以及位置等特徵。另外,也使用了動作偵測以及畫面差異特徵,視覺相似與位置相同的畫面,會被集結成序列稱為場景,場景和相對應畫面也被當作訓練的特徵。
有了這些特徵,微軟使用深度神經網路,在圖像品質標籤上訓練高維度圖像向量,這些向量被用來捕捉畫面布局的品質,而得分最高的推測畫面,將被用來作為代表影片的主要縮圖。
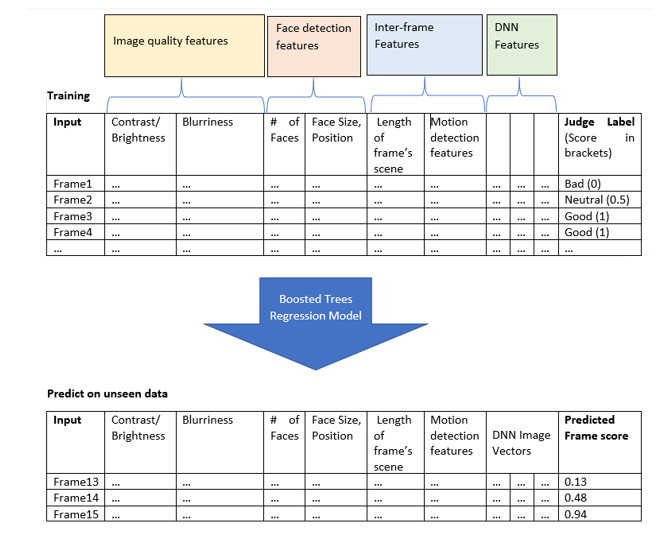
第二步則要產生4幀一組的縮圖,微軟提到,這4張縮圖的重點在於全面性與代表性,而這反而相對於前一步來說,更具技術挑戰,微軟除了無法單純使用最高分的4個畫面來當縮圖,因為這些畫面可能都來自於相同場景,再來,他們也無法要求人工產生訓練資料,因為很難要使用者從一千幀的影片中,選出最具代表性的4幀。
為了處理縮圖的綜合性,微軟在目標函數引入相似因子,嘗試最大化縮圖集的圖像品質總分,並且加入參數來調整相似度。微軟提到,他們將問題轉為貪婪最佳化的問題,以解決運算複雜性,由於他們無法列舉所有4幀畫面組合的可能性,也由於在計算主縮圖,花費了許多心力,因此微軟也決定將主縮圖納入4幀縮圖組之一,有了第一張縮圖作為起點,接下來選擇3張縮圖來最大化總分,而大幅簡化了這項工作的複雜度。
微軟提供兩組縮圖供人類評委判斷最佳的組合,一組是從影片隨機截取畫面,另一組則由最佳化方法產生,人類需要選擇較好的一組,而這個訓練資料將被用來訓練新的目標函數,以導出縮圖集模型。

微軟於Bing影片搜尋部署了這項更新,以4幀計算出來的縮圖,減少使用者搜索圖片的時間,並花更多的時間在觀看影片上。

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06