
Google針對行動裝置以及人工智慧運算架構Edge TPU,釋出採用AutoML技術最佳化的機器學習模型MobileNetV3和MobileNetEdgeTPU。在維持相同精確度的情況下,MobileNetV3的運算速度是前一代MobileNetV2的兩倍,而MobileNetEdgeTPU模型則是專為Edge TPU架構設計,在機器學習運算的速度、準確度以及功耗效率表現,可比其他模型還要好。
為了同時實現隱私保護、總是可用以及回應式的人工智慧功能,Google在行動裝置上加入機器學習運算硬體與演算法,像是在最近發表的手機Pixel 4中就部署Pixel Neural Core,這是Google Edge TPU人工智慧運算架構的實例,提供像是臉部辨識解鎖、智慧助理以及特殊相機功能等應用。除了硬體之外,演算法也是機器學習應用至關重要的元素,且因為行動裝置不像是雲端伺服器,有著理論上無限的運算能力,因此裝置上的模型需要有具壓縮且有效率的特性。
Google現在發布的兩個最新裝置上機器學習模型,在效能與功耗表現都獲得進展。MobileNetV3與之前由人工設計的MobileNet不同,Google使用AutoML技術,為手機電腦視覺任務尋找MobileNetV3的最佳架構,而且為了在不同條件都可以提供最佳效能,Google同時產出大與小兩種模型。
(下圖左)以小型模型來看,在裝置Pixel 4中,綠線MobileNetV2要達到與藍線MobileNetV3相同的精確度65.4%,MobileNetV2延遲達10ms,而MobileNetV3延遲則只有5ms。而在(下圖右)可看到,藍線大型MobileNetV3模型與綠線MobileNetV2的比較,當MobileNetV3達75%的精確度與MobileNetV2達70%的精確度時,所產生的延遲均為20ms,明顯的MobileNetV3效能比起前一代提升不少。
.png)
除了分類模型之外,MobileNetV3還加入物件偵測模型,在COCO資料集中使用相同精確度,MobileNetV3比MobileNetV2的偵測延遲少了25%。
另一個Google發表的機器學習模型MobileNetEdgeTPU,則是專為Pixel 4中的Edge TPU設計,Google提到,Pixel 4中的Edge TPU架構與Coral產品系列中的Edge TPU板相似,但是有為手機上的相機進行調整。Google同樣也應用了AutoML方法,為機器學習模型MobileNetEdgeTPU進行最佳化。
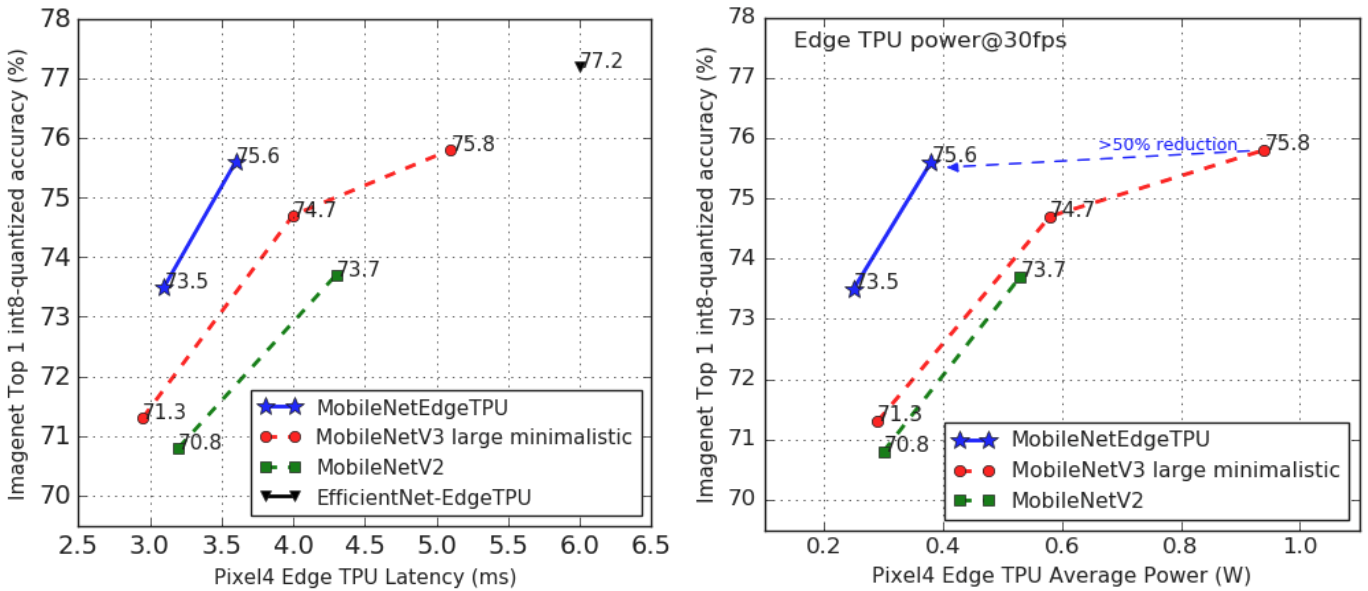
MobileNetEdgeTPU在硬體Edge TPU中有著極佳的延遲表現以及精確度,與MobileNetV2和極簡型MobileNetV3相比,在固定延遲的情況下,MobileNetEdgeTPU能提供更高的精確度(下圖),而且花費的功耗更少,在相同精確度下,MobileNetEdgeTPU使用的功耗不到極簡型MobileNetV3的50%。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10