
非營利人工智慧研究組織OpenAI發布了最新的人工智慧應用Jukebox,這是一個可以產生各種類型和風格歌曲的神經網路,OpenAI現在將模型權重和程式碼,以及用於探索生成樣本的工具發布在GitHub上,供其他研究人員進一步深入研究。
在早前就有不少音樂自動生成的研究,最先出現的是音符產生器,生成可以彈奏的樂譜,但是這種方法雖然能夠安排音符出現的時機、音高、速度和演奏樂器,製造出巴哈聖詠、複音音樂等作品,但是其具有不少限制,無法捕捉人聲,以及其他音樂細節,像是音色、力度和表現性。
另一種音樂自動生成的方法,則是直接以音訊層級生成音樂,但這種方法也不容易,光以16位元44 kHz的CD音質,產生典型4分鐘的歌曲,就需要超過一千萬時步(Time Step),研究人員提到,這是要在音訊層級產生音樂的一大挑戰,相比OpenAI Five在每場Dota遊戲中,才花費數萬時步而言,千萬時步是一個很大的前進,因此要學習音樂的高階語義,模型需要能夠處理極長的相依關係。
OpenAI提到,他們之所以會開始進行人工智慧在音樂上的應用,因為這是生成模型當前的界限,OpenAI之前的相關研究MuseNet,探索了大量MIDI資料合成音樂的方法,而現在他們從原始音訊中,讓模型解決高多樣性和超長結構的問題,且特別的是,在原始音訊域無法容忍發生在短期、中長期和長期時序的錯誤。
OpenAI研究團隊使用自動編碼器解決這個問題,編碼器會移除無關的訊息位元,將原始音訊壓縮成較低維的空間(下圖),而新模型會在壓縮空間中產生音訊,然後將其採樣回原始音訊空間。
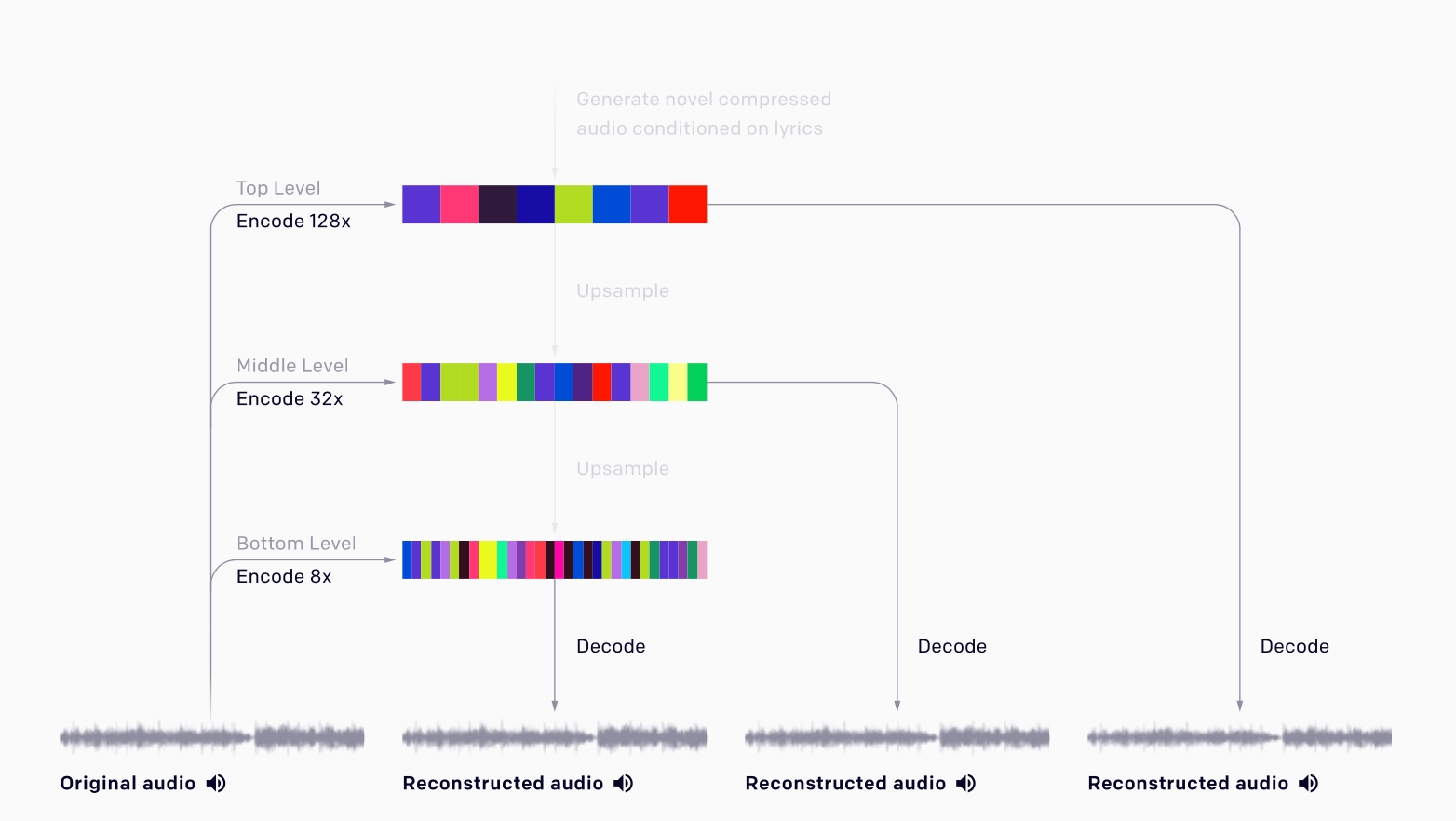
為了訓練這個模型,OpenAI在網路上抓了120萬首歌組成新的資料集,其中有60萬首是英文歌,並配對LyricWiki的歌詞和元資料,歌曲元資料包含藝術家、專輯類型和歌曲年份,還有與每首歌曲相關聯的心情和播放列表關鍵字,以32位元44.1 kHz的原始音質,並隨機降混(Downmix)左右聲道產生單聲音訊,達到資料增強的目的。
研究人員提到,雖然Jukebox無論是在音樂品質、連貫性、音訊樣本的長度,以及對藝術家、類型和歌詞的適應能力都往前一大步,但Jukebox所創建的音樂與人類的作品相比,仍是天壤之別。雖然Jukebox產生的歌曲,在局部具有連貫性,可產生遵循傳統的和弦模式,甚至表現出深刻的獨奏,但是卻不會有像是重複的副歌這類大型的音樂結構。
而且由於受Jukebox所使用的採樣技術影響,採樣的過程非常緩慢,約要9個小時才能渲染出一分鐘的音訊,所以現在的成果還不能放在互動式的應用程式中。此外,Jukebox的訓練資料集,主要是西方音樂,歌詞的部分都是英文,將來OpenAI希望可以將Jukebox擴展應用更多地區的歌曲。
除了研究成果之外,這項研究在推特上受到討論的另一個點,在於版權問題,因為Jukebox自動產生各種風格的歌曲,這些歌曲可能包含知名歌手的聲音以及相似風格的旋律,因此OpenAI也被質疑,在把這些歌曲作為訓練資料集之前,是否有取得適當的授權,但有人則認爲,這可能要討論用來訓練人類跟訓練機器人原始資料的不同之處。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10

2026-02-10


2026-02-10