AWS
為了讓資料科學家更容易進行資料分析,AWS本周宣布完全不用寫程式、不用處理資料正規化,用拖拉、點擊即可操作完成的雲端資料ETL(extract、transform, load)服務Glue DataBrew。
2016年AWS首先推AWS Glue作為第一代ETL服務,強調提供步驟化指引,讓資料分析師或資料科學家載入需要分析的資料,但是仍需要有程式撰寫技能包括SQL、Python、Scala。之後AWS又推出了Glue Studio服務,它省去了寫程式的麻煩,但是使用者仍然需處理資料清洗、正規化,這作業仍然需要仰賴ETL工程師,使得資料分析光是ELT作業就可能要花上數星期甚至幾個月。此外,常見的工具如Excel或Jupyter Notebook等試算表則無法處理大量資料。
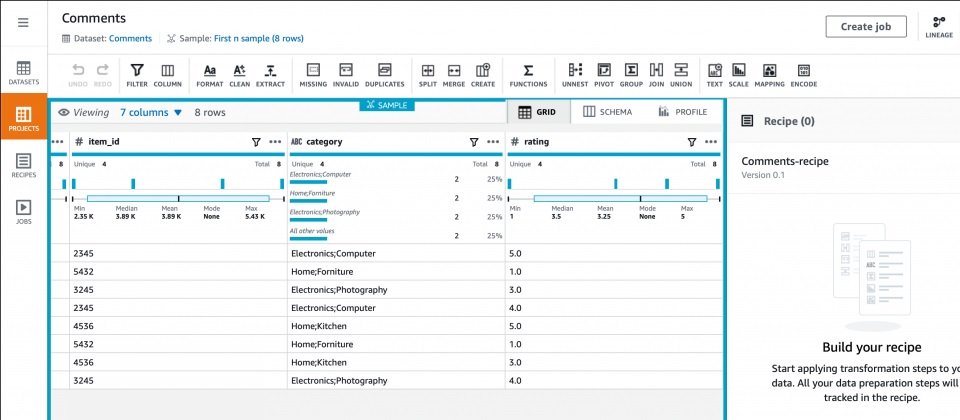
新的AWS Glud DataBrew則在AWS Glue基礎上加以改進,使用者無需寫任何程式碼,透過點擊、互動視覺化介面即可完成操作。它內建250種資料轉換功能,像是篩選異常、標準化資料(如時間及日期)格式、產生集結、修正無效資料值等,可匯入來自AWS S3資料湖泊、Redshift資料倉儲及Amazon Aurora及Amazon RDS(Relational Database Service)的資料。這項工具可提供資料清洗的建議。DataBrew還具備自然語言處理(NLP)技能來處理較複雜的轉換,像是將文字變成資料欄位值(如將yearly轉成「年度」)。
AWS宣稱新工具可將過往幾天或幾個星期的工作大幅縮短。資料準備完成後,DataBrew會將結果出版到Amazon S3。資料分析師之後即可使用第三方(當然最好是AWS的)分析或機器學習服務來查詢資料,或是訓練機器學習模型。
AWS DataBrew是根據轉換的資料量付費。這項服務已在美國、歐洲、亞太(澳洲及日本)區上線,之後會再推向其他地區。目前用戶包括NTT Docomo 、英國石油(BP)及化纖廠Invista等。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10

2026-02-10


2026-02-10