Google發表一項新的機器學習方法,來讓遊戲開發人員有效訓練遊戲測試代理,以快速找到遊戲中嚴重的錯誤,使得人類測試員能夠將心力放在更複雜的問題上。這個解決方案並不需要專業的機器學習專業知識,而且適用各種流行遊戲類型,Google開源了Falken函式庫來展示這項技術,遊戲開發者能夠快速地訓練足以遊玩自家遊戲的人工智慧代理。
由於過去20年運算和網路技術的進展,使得遊戲作品越來越複雜,從過去簡單的線性關卡,已經演變到無窮盡的開放世界,遊戲具有豐富的多樣性,且隨著網際網路的擴展,也促使了線上遊戲發展,Google提到,遊戲複雜度的成長速度,已經超過目前測試團隊和傳統自動化測試的能力範圍,這些限制使得遊戲品質出現挑戰。
而機器學習技術的進步,展現了能夠解決測試問題的潛力,目前機器學習技術已經能夠協助遊戲設計師平衡遊戲,還能讓美術人員在短時間產出高品質的作品,另外,運用機器學習技術,也能訓練出可與人類抗衡的人工智慧對手。
遊戲開發人員的營運環境剛好有益於機器學習技術應用,因為能夠直接存取遊戲程式,還能簡單取得許多高手的示範資料等。Google考量這些特性,發展出了一個機器學習系統,來協助遊戲開發人員有效地測試遊戲。
Google提到,測試遊戲的最基本的形式就是遊玩遊戲,其中許多嚴重的錯誤,包括程式崩潰或是掉出世界地圖,是很容易偵測和修復,困難的是要在廣泛的遊戲狀態空間中觸發這些錯誤,而能夠大規模遊玩遊戲的機器學習系統,便能幫上忙。

測試遊戲最有效率的方法,並非訓練單個能將遊戲從頭玩到尾的超級代理,而是要訓練一組遊戲測試代理,每個代理能夠有效地遊玩數分鐘的任務,這數分鐘的任務被稱為遊戲循環,Google提到,在商業遊戲實務中,通常透過重複和混合核心遊戲玩法,來創建更長的遊戲循環,因此開發人員也可以將機器學習策略,結合簡單的腳本,來測試大量的遊戲玩法。
但要將機器學習應用到遊戲測試的一大挑戰,是要克服以模擬為中心的電動遊戲,與以資料為中心的機器學習技術間的障礙,而Google開發出來的這個系統,不需要開發人員將遊戲狀態直接轉換為低階的機器學習功能,或是從原始畫素中學習,而是提供開發人員簡易的API,根據玩家能觀察到的基本狀態,以及可以執行的語義操作來描述遊戲,所有的這些資訊都是遊戲開發人員熟悉的概念,像是3D位置和旋轉、實體以及射線等。
開發人員可以使用高階語義API描述觀察和操作,系統也能靈活地適應各種遊戲,遊戲開發人員所選用的API建構模塊,會影響測試系統選用的神經網路架構,像是依據使用數字按鍵或是搖桿控制,以不同方式處理動作輸出,或是使用影像處理技術來處理使用射線探測環境的結果。
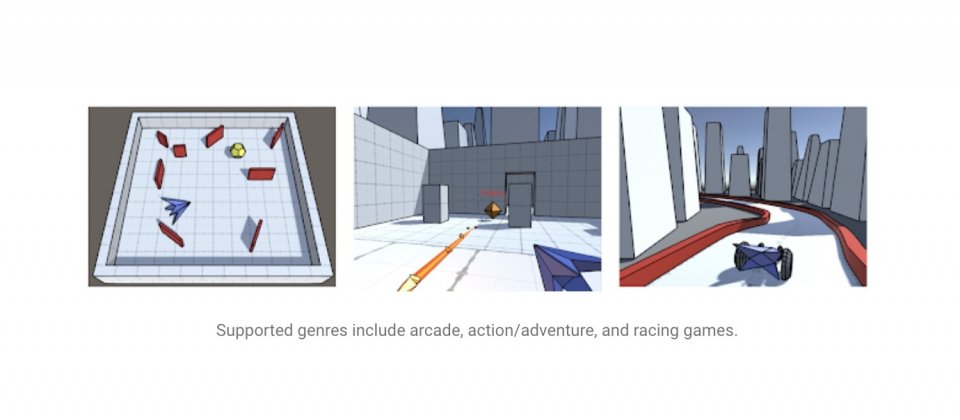
由於API足夠通用,因此可以對應常見的控制方法,像是第一人稱、第三人稱、賽車遊戲甚至是雙搖桿射擊遊戲等,而且因為3D移動和瞄準通常是遊戲重要的一部分,因此Google創建了能夠執行瞄準、接近和迴避等簡單行為的神經網路,Google提到,系統會透過分析遊戲控制方法,來創建神經網路層,以實現基本的行為,像是物體的位置和旋轉,會自動轉換成玩家視角的方向和距離,來加速學習,並且提高學習網路的泛化。
在生成神經網路架構後,還需要有訓練演算法來訓練神經網路遊玩遊戲,Google選用模仿學習(Imitation Learning,IL)技術,透過觀察專家玩遊戲來訓練機器學習策略。不同於增強學習技術需要自己創造出好策略,模仿學習只需要重建人類專家的行為就足夠。系統讓遊戲開發人員可以扮演遊戲專家,展示玩法給神經網路學習,並且隨時切換為觀看模式,觀察機器學習系統遊玩。
Google發布Falken開源函式庫,供遊戲開發者啟用服務,來訓練人工智慧代理遊玩他們所開發的遊戲,由於代理透過觀察人類即時的行為來學習,因此開發者不需要有機器學習專業,可以簡單上手。
熱門新聞

2026-02-06

2026-02-06

2026-02-09

2026-02-06

2026-02-06
")
2026-02-09


2026-02-09