
Uber列出開源平臺大數據分析省錢戰略,鎖定供應、需求、平臺效率等三部分,來著手改善。
螢幕截圖
重點新聞(0903~0909)
Uber 開源平臺 大數據分析
Uber數百PB資料分析全靠開源平臺,如何思考省錢戰略?
大數據分析是Uber業務的核心,他們仰賴AI、ML和大數據分析來優化顧客體驗。在過去四年來,Uber資料量從幾PB暴增至上百PB,全仰賴Hadoop、Kafka、Spark和Hive等開源平臺來分析。這是因為,開源軟體能快速擴展、滿足業務需求,讓團隊不必閉門造車。
但Uber坦言,大數據分析平臺是自家三大平臺中最燒錢的工具。於是,Uber採取一套省錢戰略,先在2019年底節省數百萬美元的硬體成本,再於2020年初,制定未來兩年的成本節省藍圖,來降低大數據分析支出。
這個省錢戰略鎖定供應(Supply)、需求(Demand)和平臺效率三部分。供應是指執行大數據儲存和運算所需的硬體資源,比如本地端與雲端運算、災難復原架構。Uber成立11年來,大部分運算工作都在本地端資料中心執行,只有少數專案在雲端執行。對他們來說,上雲能不能明顯降低硬體成本,是第一個要思考的議題。團隊認為,本地端搭配適度的雲端運算,能有效降低成本。而在災難復原設計上,Uber採用AA架構來確保運算不中斷,但也因此產生兩倍運算成本,這是他們面臨的另一挑戰。

在需求部分,Uber考量的是運算工作負載,像是多租戶問題。Uber大數據分析平臺擁有數千名內部使用者,包括後端工程師、產品工程師、ML 工程師、數據工程師與分析師、資料科學家、產品經理、業務分析師等,他們來自不同部門、從事不同業務。
這麼龐大複雜的用戶群,也讓資源利用效率不彰,比如Uber無法深入了解所有使用情況,或因大數據儲存、運算能力有限,因此難以決定優先給哪些使用者資源,也難以決定哪些使用者該為此付費。

平臺效率部分則考慮P99和硬體資源的平均使用率。Uber用P99利用率來描述在叢集中的高負載節點比率,他們認為,低延遲系統需要低P99值,來避免花更多時間處理請求和查詢,但P99卻有可能比硬體平均使用率高上好幾倍,在硬碟空間使用率、CPU/記憶體使用率、網路使用率等場景都會發生,影響處理效率。他們的目標,是要縮短P99和平均使用率的差距,來讓機器資源有效運用。
歸納出這些原因後,Uber從這三大領域下手,展開一系列的開源平臺省錢實驗。(詳全文)
資料管理 Tableau 擴展性
繼無程式碼ML功能後,Tableau再添企業級資料管理功能
Salesforce旗下數據分析工具Tableau透露,即將推出的2021.3版將新添資料管理和平臺擴展功能。
在資料管理部分,使用者現可在Tableau Catalog中,直接在網頁創作流程中查看衍生描述(Inherited descriptions)。使用者也能透過Email訂閱,來掌握資料品質警示,能直接從Email連結打開儀表板,查看品質受影響的資訊。再來,Tableau資料流程管理工具Prep Conductor也新增加了多任務排程功能,除此之外,Prep Conductor也能利用日期、時間、整數值來判斷資料表中遺漏的筆數,來幫助使用者補填資料、完善資料集。
Tableau也預告,今年還將推出企業級架構新功能,明年初則將推出資源管理、支援容器的動態擴充功能。進一步來說,企業級架構具階層結構的拓樸,能讓IT團隊標準化部署Tableau,來實現可用性、安全性、合規性以及可擴展性。在這個架構中,伺服器應用功能的每一層,都受到子網的保護和控管,不論企業是部署在本地端還是雲端,是用VM還是容器,都能靈活地跨子網管理、擴展分層架構。(詳全文)

醫療AI 可解釋性 聯合學習
北榮AI推手呼籲,醫療AI下一步瞄準可解釋性、可信任的FL
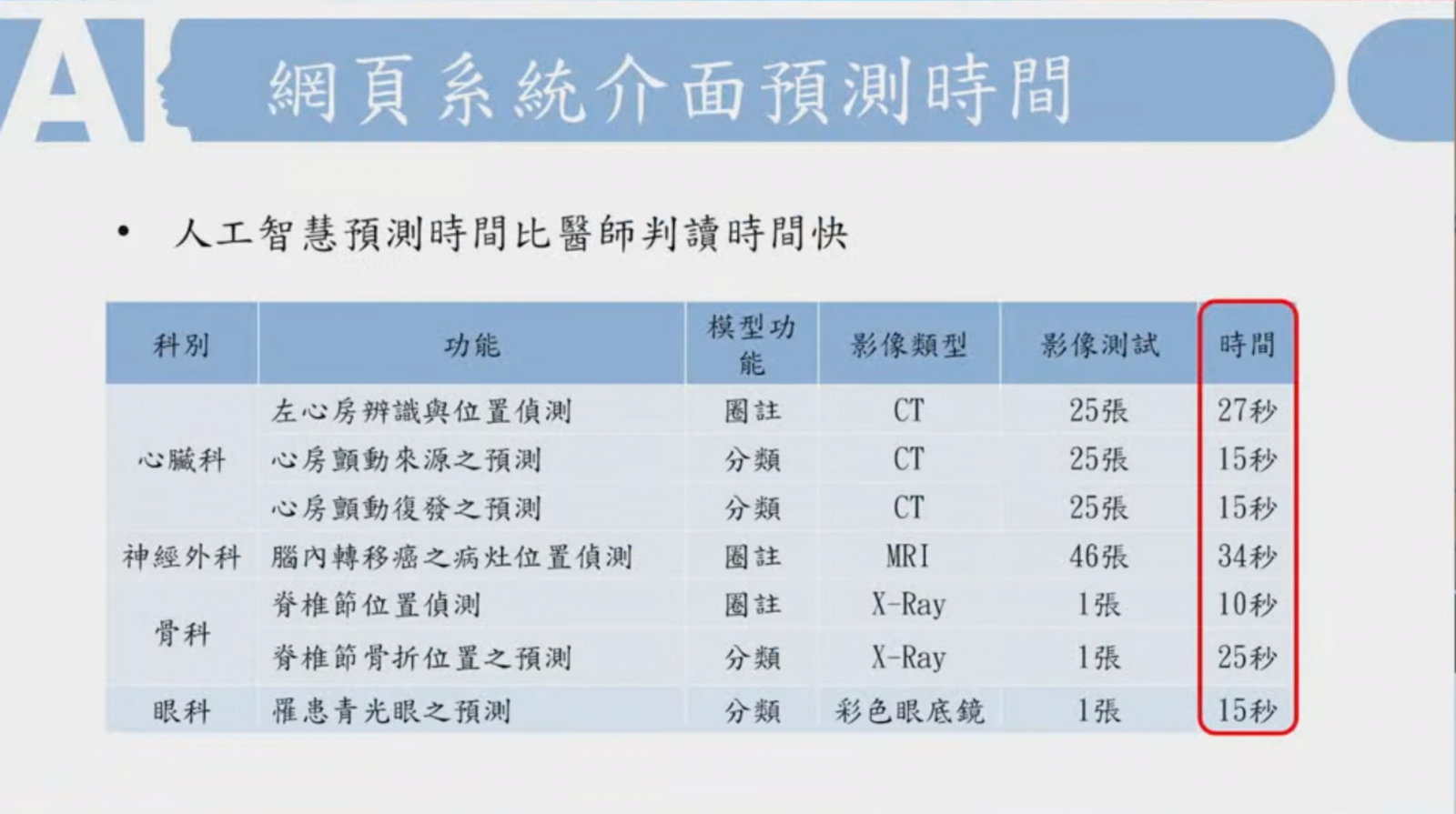
北榮近年來打造了四大科別的AI醫療診斷工具,範圍橫跨心臟科、神經外科、骨科和眼科,比如心房顫動復發率預測、脊椎節骨折之確切位置預測、青光眼和視網膜病變預測等,這些AI系統,已在北榮AI門診實際派上用場。
開發這些AI門診專用系統的核心成員、交大陽明統計學研究所教授盧鴻興在5日智慧醫療高峰會上指出,這些AI工具的判讀時間可比醫師快,像是從25張電腦斷層掃描(CT)影像辨識心房顫動來源只需15秒,從1張彩色眼底鏡分類是否罹患青光眼只需15秒。
但他強調,醫療AI接下來要重視可解釋性的AI(即XAI),來說明模型判斷的依據,並納入醫學教科書中的新章節。同時,他也呼籲發展可信任的聯合學習(FL),透過整合多家醫院、多位醫師的專業知識,產出更好的AI系統,來超越「一位醫師、一家醫院的經驗。」
Google 分層神經 遮罩
連細節都能分離!Google用分層神經開發影片圖像遮罩新方法
連細節都能分離!Google開發一種產生圖像和影片遮罩的新方法,利用分層神經渲染,將影片中的物體和背景分開,產生Omnimatte遮罩。有別於傳統方法,這個遮罩不僅能分離物體本身,還能分離與物體相關的細節,比如影子、部分透明的軟效果,甚至是輪胎摩擦地面產生的煙霧。與傳統遮罩相同的地方是,Omnimatte為RGBA圖像,因此能夠用於廣泛的圖像和影片編輯工具。
另一方面,Omnimatte也能控制物體在影片中出現的時間(Retime)。研究團隊指出,這項效果常用於電影,但傳統方法必須在受控的環境中執行,而分解成為Omnimatte後,即便是日常影片,也能簡單操縱物體時序,只需更改每一個圖層的播放速度,就能達到過去必須要對每個物體重新拍攝才能達到的效果,且由於Omnimatte是標準的RGBA圖像,因此能使用傳統的影片編輯軟體來編輯物體時間軸。(詳全文)

機器學習平臺 低延遲 Vertex AI
IoT資料回傳更即時,Google機器學習平臺Vertex AI開始支援私有端點
Google機器學習平臺Vertex AI上新添私有端點(Private Endpoints)功能,透過VPC對等連結,用戶可配置專用的連接與端點通訊,資料不必經過公開的網際網路就能運算、預測,如此也更安全、更快速。
Vertex AI是Google在今年發布的全託管機器學習平臺,要來簡化企業部署和維護機器學習模型工作。為解決即時機器學習模型預測的延遲問題,他們利用VCP對等連接來提供低延遲的網路連接,降低系統收到請求的時間,還可以創建私有端點,讓資料永不穿過網際網路來提高安全性。Google指出,在私有端點部署模型的額外開銷很小,且效能幾乎與在GKE或GCE的服務相同。(詳全文)
Nvidia 語音合成 Flowtron
Nvidia新技術連語音都合成得唯妙唯肖
Nvidia應用深度學習研究部門副總裁Bryan Catanzaro盤點Nvidia對話式AI成果,如輕量級語音合成系統、專屬資料集、降噪模型,以及GTC大會登場AI旁白系統Flowtron。Flowtron中有套關鍵的文字轉語音模型RAD-TTS,不只能產生語音,還能轉換語音風格。開發時,團隊借鏡語音合成重要技術自迴歸流概念,以此改善經典語音合成模型Tacotron,來提高語音合成品質。
另比如,RAD-TTS能更好地控制音高、音調、語速、節奏和口音,甚至能轉換聲音,將A男說話的聲音同步轉換為B女,並保留A男說話的特徵。如此一來,使用者可錄製自己讀出的影片腳本,再用Flowtron將說話內容改變為不同性別的聲音,或是透過系統調整合成語音,來強調特定字眼或放慢節奏。Bryan Catanzaro指出,這個AI模型不只用於配音,還能用在遊戲、協助語言機能障礙者理解,甚至能以使用者自己的聲音,翻譯成不同語言。(詳全文)
圖片來源/Uber、盧鴻興、Tableau、Google、Nvidia
AI趨勢近期新聞
1. Automation Anywhere發布RPA成熟度工具
2. 知名語言學習廠商Duolingo用AI配對學習資源
3. Boston Dynamics分享人形機器人的技術挑戰
資料來源:iThome整理,2021年9月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10