
微軟用Transformer架構打造OCR文字辨識工具,特別的是,這個工具完全不需CNN作為骨幹網路,單靠Transformer就能通吃影像辨識和文字生成。
微軟
重點新聞(1001~1007)
微軟 OCR Transformer
OCR新突破!微軟用Transformer訓練出高階OCR工具,手寫、影印辨識都行
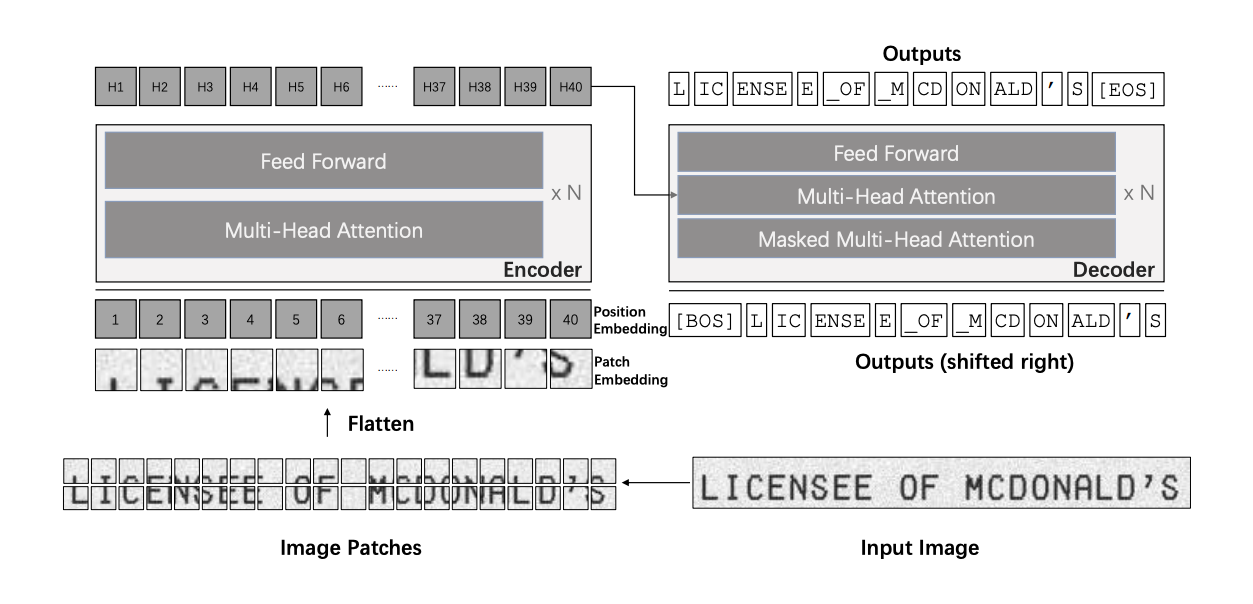
OCR應用場景十分廣泛,舉凡銀行票據手寫辨識、街景招牌辨識、發票辨識等等,都少不了它。微軟AI研究院最近揭露一款OCR工具TrOCR,以擅長處理序列任務的Transformer架構為基礎,完全不需卷積網路(CNN)作為骨幹,就能執行影像辨識和文字生成,手寫辨識和影印辨識都能者達到高階等級的辨識效果。
進一步來說,OCR文字辨識是文檔數位化的關鍵,目前常見的方式是用一套CNN進行影像辨識,再用遞歸網路RNN進行字符等級的文字生成。雖然近期有些用Transformer打造的OCR成果,但仍需要CNN作為骨幹。
為突破這個困難,微軟用Transformer架構打造TrOCR,其中包括用來辨識影像的ViT(Vision Transformer)和用於自然語言處理的BERT預訓練模型。在執行ORC辨識時,TrOCR會調整輸入的文字影像為384x384像素的尺寸,再將影像拆解為16x16像素的小區塊,以供ViT影像辨識使用。再來,團隊在編碼器和解碼器使用標準的Transformer架構,來進行文字生成。微軟表示,TrOCR不需任何複雜的前處理或後處理步驟,就能在手寫和影印辨識達到高階表現,使用者也不要任何外部語言模型,就能達到良好的辨識效果。(詳全文)
資料科學 JupyterLab 桌面版
資料科學工具JupyterLab有桌面應用程式版了!
Jupyter發布一套跨平臺獨立的桌面應用程式JupyterLab,內建Python環境和常用Python函式庫,方便開發者用於科學運算和資料科學工作流程中。
JupyterLab應用程式以開源框架Electron為基礎,在嵌入式瀏覽器中執行JupyterLab前端,而JupyterLab後端和Python函式庫,則透過conda Python環境提供,環境中的函式庫則有numpy、scipy、pandas、ipywidgets和matplotlib等熱門科學運算函式庫。可直接從GitHub頁面下載安裝程式,目前能支援Debian、Fedora等Linux發布版本、macOS和Windows作業系統。(詳全文)
DeepMind 臨近降水預報 氣象局
1小時後降雨下雪都能預測!DeepMind發表降水臨近預報AI模型
DeepMind和英國氣象局合作,發表最新的AI氣象預報研究,可用來預測未來1到2小時的降雨和下雪等降水現象,提供臨近預報。臨近預報對水資源管理、農業、航空和戶外活動等產業非常重要,天氣感測裝置的進步,能蒐集到更多高解析度的雷達資料,搭配機器學習來利用高品質資料,有機會解決關鍵領域難題。
DeepMind利用生成建模(Generative Modelling)方法,能根據過去的雷達資料,對未來的雷達資料進行詳細且合理的預測。他們能以此準確捕捉大規模事件,還能生成系集預報(Ensemble Predictions),進而探索降雨的不確定性。這項研究使用了來自英國和美國的雷達資料,並且經英國氣象局的50位氣象專家進行評估,與目前被廣泛使用的臨近預報方法相比,在89%的案例中DeepMind的新方法表現較佳。(詳全文)

國泰金控 AutoML Tumblebug
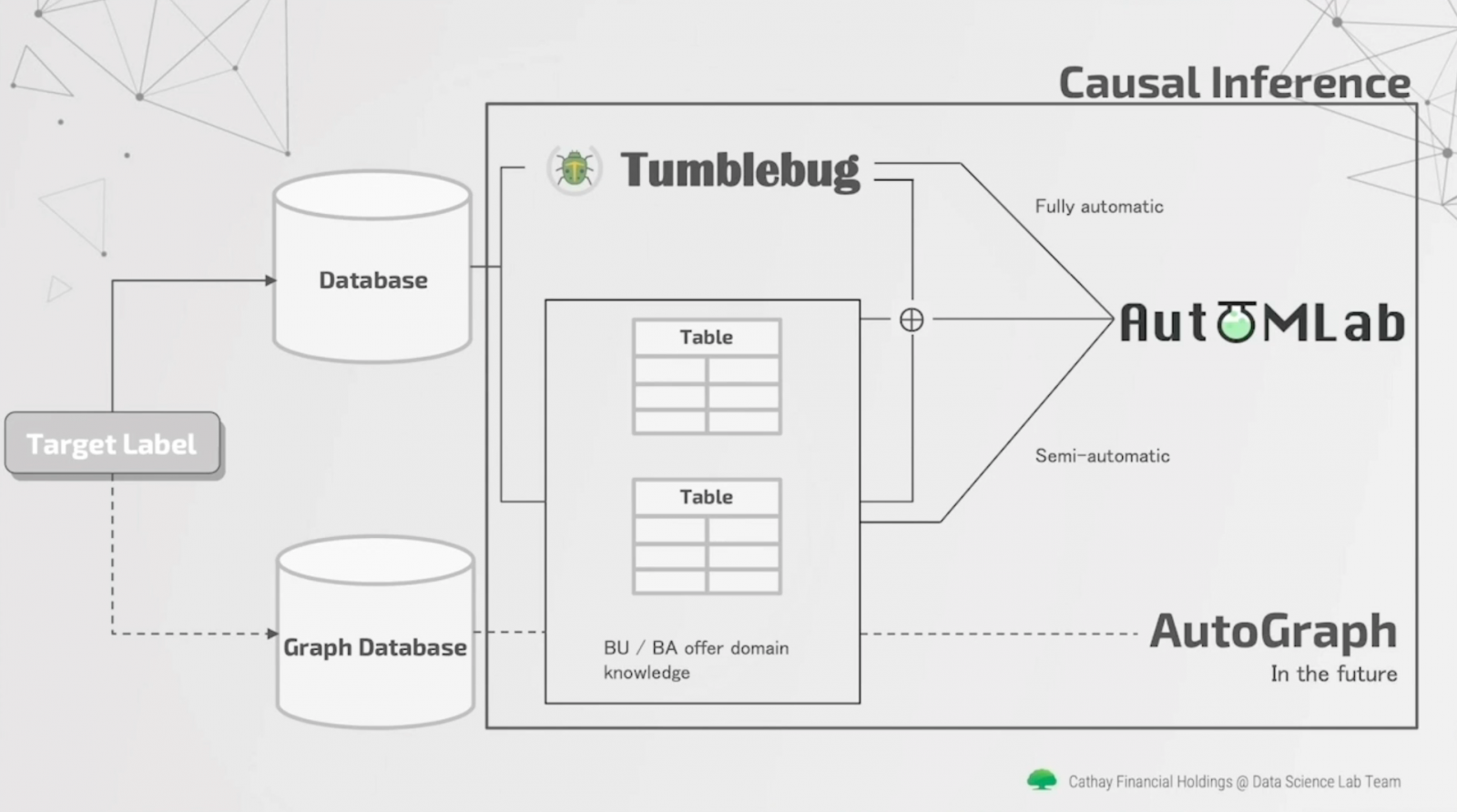
國泰金控打造AutoML工具,下一步要發展GraphML
國泰金控日前在技術年會上揭露一款AI資料分析專用工具Tumblebug,能根據使用者需求,自動從資料庫海中撈出所需資料,補足AutoML最後一哩路。國泰金控的AI資料分析流程可分為四大步驟,包括問題定義、取得相關資料、特徵工程,以及模型選擇和訓練。這四步驟非常耗時,於是,國泰金控自行開發一款AutoML套件AutoMLab,來自動處理第三、四步驟。
不只如此,他們還打造一款基於Spark分散式運算平臺的特徵搜尋套件Tumblebug,能根據預測目標,來從國泰金控海量資料表中撈出關鍵資訊,自動匯集成一張資料表,供使用者後續建模分析使用,不再受限於特定領域知識,也能快速驗證專案。如此,國泰金控就成功自動化執行第二步驟了。
目前,國泰金控資料科學團隊正打造圖學資料庫,要將客戶金流網絡、關係網絡轉換為圖學資料,儲存至圖學資料庫中。未來還要打造AutoGraph工具,自動化執行圖學模型的建置與訓練,方便分析師善用圖學技術解決更複雜的金融問題。(詳全文)
機器學習函式庫 關鍵字參數 Scikit-learn 1.0
14年終於發布正式版,機器學習函式庫Scikit-learn 1.0問世,新添關鍵字參數不必再記複雜的位置了
Python開發者慣用的ML函式庫Scikit-learn終於發布1.0版本,也代表更適合用於正式上線環境。這個在2007年誕生於Google夏日程式碼競賽的SicPy工具箱,後來廣受資料科學家們愛用,現在終於推出了第一個正式版本,更新重點聚焦穩定性,來應付更多複雜的使用場景,最大功能更新則是關鍵字參數。
因為,scikit-learn API提供了許多需要輸入大量參數的函式,但過多參數常造成混淆。為提高程式碼的可讀性,現在用戶需要提供大多數參數的名稱,作為關鍵字參數,而非原本以位置作為識別方法的位置參數。另一方面,官方也在SGDOneClassSVM中加入了隨機梯度下降方法,實作出One-Class SVM線上線性版。(詳全文)
IBM Linux基金會 AI儲存庫專案
IBM聯手Linux基金會啟動AI儲存庫專案MLX,要解決模型資料交換挑戰
IBM與Linux基金會旗下AI暨資料(LFAI and Data)基金會合作,啟動機器學習交換專案(MLX),要打造一個資料和AI資產目錄的執行引擎,來支援AI生命周期中資料跨組織共享和交換的問題。
進一步來說,打造AI系統需要大量資料處理,開發者也會與不同團隊互動,比如建立資料集、特徵、模型等,而這些工作需要可追溯性、治理、風險管理和元資料收集等支援。
MLX就是要解決這些問題。它要打造一個中央儲存庫,儲存所有資產類型,以便跨組織共享和重複使用這些資產。MLX儲存庫能執行檢查、授權和追蹤資料集,也允許用戶上傳、註冊、執行和部署AI工作管線、模型、資料集和筆記本。MLX在OpenShift和Kubernetes上執行,工作管線引擎則以Kubeflow Pipelines on Tekton為基礎,並提供一系列免費開源的深度學習模型。(詳全文)

台電 戶外巡檢機器人 工研院
台電高壓變電所巡檢改靠國產機器人,自動避障即時回傳巡檢結果
工研院聯手台電、臺灣智能機器人公司發表一款國產戶外巡檢機器人,外觀像是瓦力的四輪移動式小車,已實際運用在台電變電所場域,接下來要累積機器人實務經驗,擴大應用到國營、民營企業變電站。
經濟部工業局組長林華宇表示,過去巡檢機器人多屬非自主性機器人,巡檢時需要人員用遙控器操作,並人工記錄相關資訊,但這次研發的機器人導入AI導航模組,可高度自動化、降低出錯率。
這款戶外巡檢機器人進駐台灣電力公司萬華二次變電所,依照中央控制室排定的巡檢時程,來檢查電容器、主變壓器等設備。機器人能在既定路線上進行巡檢,透過AI自動導航定位導航和避障,斜坡、碎石路或5公分高低差路面都可行走,可一邊行走一邊回傳巡檢影像到中控室,讓台電人員了解即時狀況,視需要派遣人員前往維護,提升工作效率。(詳全文)

圖片來源/微軟、JupyterLab、DeepMind、國泰金控、Scikit-learn、Linux、工研院
AI趨勢近期新聞
1. OpenAI新ML模型可摘要任意長度的書籍
2. 美國FDA核准一套能偵測前列腺癌的醫療AI軟體Paige Prostat
3. 臉書發布強化學習環境函式庫CompilerGym
資料來源:iThome整理,2021年10月
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
