微軟與AMD合作,使得深度學習最佳化函式庫DeepSpeed,能運用支援ROCm平臺的GPU加速運算,這也包含AMD自家的Instinct GPU。這項更新使得DeepSpeed得以獲得運算、記憶體和通訊最佳化技術加持,能夠用於訓練高達5,300億參數的語言生成Transformer模型,並在真實的使用場景中,加快訓練和推理速度達2倍到20倍。
大規模深度學習模型,在自然語言處理和電腦視覺等應用表現出色,但是要訓練這些具有數億甚至是數百億參數的大型模型並不簡單,微軟提到,由於模型的規模過於龐大,需要分散到多個節點上,調度運算和通訊才能訓練完成。
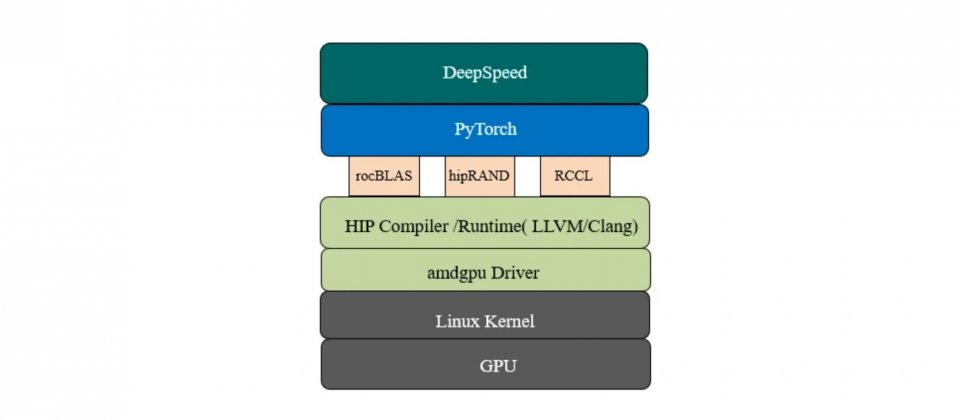
為了讓這個工作更將容易,微軟開發了DeepSpeed,這是一個PyTorch開源函式庫,能夠極大程度提高大型模型訓練和推理的規模、速度和可用性,開發者可以使用最少的程式碼,在應用程式中運用運算、記憶體和通訊最佳化技術。而DeepSpeed現在進一步支援相容ROCm的GPU,使大型模型訓練更加有效率。
AMD從2006年開始,發展用於高效能運算(HPC)和機器學習運算的GPU硬體與軟體技術,AMD的開放軟體平臺ROCm,提供函式庫、編譯器、執行環境和工具,讓研究人員得以使用AMD Instinct GPU,或是其他支援ROCm技術的GPU加速運算。目前主要的機器學習框架諸如PyTorch與TensorFlow,都提供ROCm支援,因此開發者不需要執行任何移植工作,便可以直接在相容的GPU硬體上,執行這些框架的程式碼。
微軟與AMD密切合作,在DeepSpeed上支援這套平行化和最佳化技術,藉由相容ROCm的GPU上,高效能地訓練大型模型,這使得到AMD Instinct MI100/MI200單一GPU或是分散式叢集,都可被用來訓練千億參數的模型。
DeepSpeed提供了一套平行化與記憶體最佳化方法,如ZeRO、ZeRO-Offload、ZeRO-Infinity和3D平行,這些方法將可讓開發者,顯著地在AMD GPU上擴展模型規模,遠遠超出純資料的平行化限制。在8個節點128個MI100 GPU上訓練模型,跟資料平行方法的15億參數限制比起來,每個DeepSpeed最佳化方法都可以使模型擴展兩個數量級,在更極端的情況,ZeRO-Infinity甚至可以訓練接近2兆參數的模型。

在微軟與AMD的合作下,DeepSpeed 0.6開始原生支援相容ROCm的GPU,而且這個新版本與舊版本使用相同的API,因此開發者不需要更改任何程式碼,就可以直接在支援ROCm的GPU上,使用DeepSpeed的所有功能。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-06

2026-02-09

2026-02-09