
Zalando在2015年從一家電商進一步發展成大平臺,開始對生態圈和合作夥伴輸出技術,關鍵就是在2015年開始擁抱公有雲,並將單體式應用,全面轉換成為容器化的微服務架構。圖片來源/Zalando
快時尚電商Zalando是一家不到15歲的鞋子和服飾品電商,在臺灣知名度雖然不高,但他們是歐洲最大的服飾電商平臺。2022年第一季的顧客人數高達4,800萬人,超過5,800萬張訂單,全部都是透過網路平臺完成。Zalando一年營收約100億歐元,相當於臺幣3,100億元,相當於臺灣2021年前三季所有電商營收金額的總和。
Zalando在2008年創立後,迅速拓展到各國,2015年更從電商進一步發展成平臺化的戰略,開始對生態圈和合作夥伴輸出技術,關鍵就是在2015年開始擁抱公有雲,並將單體式應用,全面轉換成為容器化的微服務架構。
很難想像,2008年在德國柏林創立的Zalando,第一年營收只有600萬歐元(不到臺幣2億元),隔年開始出貨到奧地利,3年後更賣到荷蘭和法國等更多國家。直到2011年時,Zalando正式進入其他國家開設分店,推出英國、義大利、瑞士的本地電商平臺,正式成了跨國電商,隔年更在歐洲其他8國落地,順利於2014年在德國上市。至今,Zalando在歐洲23國提供服務,從賣鞋子起家,到後來銷售各種服飾用品、體育用品,超過4千個品牌,累計近89萬件商品。
甚至,Zalando不只是服飾業者,更靠技術拓展其他商業模式,例如他們各國官網總流量一年高達50億人次,其中85%來自手機,這促使Zalando開始提供了官網或App的廣告服務,作為品牌商數位行銷通路之用。不只電商和廣告業務,他們還打造一套自家的支付平臺,每年經手的金額高達20億歐元,等於是一家頗具規模的金融科技公司,Zalando還將自己在全歐建置的物流系統,打造成一套B2B物流服務,來支援其他品牌實體門市的供貨,Zalando就像是歐洲服飾圈的Amazon一樣的地位。他們一年投資在物流和科技建置的預算高達4、5億歐元,約臺幣130到150億元。
從第一年營收600百萬歐元到現在的100億歐元,14年營收成長超過1,600倍,科技力是Zalando撐起如此龐大的交易規模背後的關鍵。
一開始,Zalando只是一個用PHP搭配MySQL開發的網路商店,就像臺灣許多電商平臺,也都採用了這個在2008年常見的免費網站開發技術來打造,只有一小組人用Java打造特定應用,隨著業務逐漸擴大,甚至發展到2010年用Java技術搭配PostgrsSQL重新打造。接下來的3年,是Zalando快速跨入各國落地的關鍵,一方面導入企業級ERP,另一方面開始發展各國網站,也打造一個具有大規模處理能力的訂單和交易集中式平臺。
為了支援未來全歐多國的營運布局,2014年底,Zalando決定大力擁抱公雲,導入Docker容器技術,開始發展微服務架構,來取代老舊的單體式架構。上市後隔年,也就是2015年,Zalando開始往平臺化戰略發展,要將自己變成生態圈的技術平臺商,開始對合作夥伴和生態圈輸出技術服務。這時,Zalando擁有1萬名員工,超過1千名IT工程師,200個開發團隊。
2016年,Zalando陸續完成了各項系統的上雲轉換,將自己變成了一家雲端原生架構的電商平臺,也開始進一步導入K8s,2019年時,Zalando就是靠部署在公有雲上的118個k8s叢集,撐起全歐各國的電商平臺,甚至是黑色星期五大採購都順利完成。Zalando自己也是K8s的資深貢獻者,累計到2022年,開源了超過47個元件。
上雲兩年遇到維運大考驗,待命人手不足,決定導入SRE
但是,Zalando上雲之路不是一帆風順,2016年時,雖然大多數系統已經完成架構轉換而部署到公有雲上,而最早上雲的團隊也有超過1年的雲端維運經驗,但是,他們卻遇到了擁抱公雲後最大的維運難題,甚至影響了他們各部門平臺的正常運作。
Zalando首席軟體工程師Pedro Alves在自家部落格上公開了這一路導入SRE的三階段發展過程,他坦言,完全上雲之後,對工程團隊帶來很大的衝擊。因為上雲之後,工程團隊得全權負責自己打造的軟體,從設計,開發,測試,部署到最重要的「維運」,研發工程團隊都得負責。「這是在全面上雲之前,他們沒有意識到改變,這件事帶來截然不同於開發的挑戰和複雜度。」他強調。
Zalando原本的系統大多是以Java技術打造的單體式大型應用,上雲過程同時進行架構轉換,變成了分散式的為服務架構。研發團隊熟悉的是從軟體開發角度的維運經驗,上雲之後,不論是監控、自動測試、部署,到各種雲端服務事件的處理,甚至是雲端Runtime的管理,都是與本地端大型單體應用截然不同維運經驗。
待命支援人力不足,成了Zalando的超級痛點
同時進行AP架構和IT基礎架構的轉換,在轉換成微服務架構之後,Zalando設立了5個待命團隊(On-call)來支援當時超過200個開發團隊,來適應微服務化之後的新架構。
可是,這些待命團隊擅長的仍舊是,單體式架構的開發和維運,Docker容器技術和微服務架構對他們來說,也是全新的技術體系。轉換到新架構。各個研發團隊,一方面需要修改原本所有服務的維運做法,重新建立新的標準化做法,另一方面,還要在雲上快速發展各種新應用,也就遇到了大大小小不同的問題需要技術支援。可是,許多技術支援工單,卡在待命團隊等待回答,上百個開發團隊遲遲等不到回答,又不知道該如何更妥善的維護那些已經上雲的服務,缺乏了一些治本的標準解方,研發團隊得花不少時間來救急,疲於應付經常發生的維運麻煩。Pedro Alves直言:「待命團隊的能力,跟不上新的技術需求,因此,沒有辦法滿足新服務的技術支援,而且愈來越無法負荷。」
階段一:開始導入SRE,按產品線設置SRE小組
2016年,剛好是Google發表《Site Reliability Engineering: How Google Runs Production Systems》 這本書的那一年,Zalando工程團隊一看到這本書就大受啟發,覺得說中了自己的痛點,積極說服高層後,決定大力擁抱SRE。
從Pedro Alves公開的一張SRE導入腦力激盪圖,可以看到Zalando最大目標就是要解決待命支援不足的問題,希望讓待命支援能力可以永續而不中斷。他們也是先從辨識各種事件和失敗特徵做起,開始定義SLO、量測 SLO,並且要建立監測機制、警示機制等下手。Pedro Alves回顧,導入成功SRE還有另一個關鍵因素是,Zalando原本就擁有不怕改變的文化,因此,在高層作出決定後,Zalando工程團隊就毅然地全面擁抱SRE。不過,仍然有一個重要的課題,怎麼配置SRE團隊的編制?Zalando在2016年時已經有1千名軟體研發工程師,產品線也很多,幾番討論後決定,不是建立一個超大的SRE團隊,也不是在各團隊下各自設置一名SRE人力。而是「按照產品叢集來建立SRE團隊,一個團隊負責一個叢集,一個SRE團隊負責同一個產品網域下的所有維運責任。」Pedro Alves指出。
另外,Zalando也透過內部問卷,搜集內部各團隊對於SRE角色的意見和期待,來凝聚所有人對SRE定位的共識,最後歸納出這個角色的能力定義:SRE具有軟體工程能力、維運思維、系統工程能力、軟體架構技能和問題解決能力。這五大能力成了日後Zalando建立內部人才庫的重要參考方向,不只用來培養SRE人才,更用來要求各種技術角色的工程師,都要培養這五大類的能力。這一步是促成了日後SRE能力普及到更多團隊的關鍵。
接著,Zalando成立第一個SRE團隊後,第一個工作就是設計SLI(服務水準指標) ,以及訂出想要達成的SLO(服務水準目標),也打造了一款內部使用的SLO報表工具,並舉辦工作坊,來對內部上百團隊的產品PM和工程師介紹SRE。甚至在每年最重要的網路購物週的因應計畫中,也舉辦SRE工作坊,來討論購物潮網站的各項可靠性設計,來因應這個年度最大的交易爆量考驗。
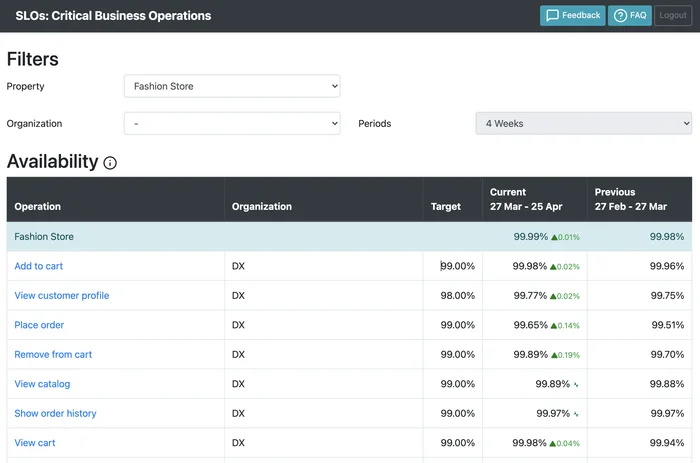
Zalando現在所用的SLO監測儀表板,更容易從顧客角度來觀察可能造成服務當機的徵兆,例如會監測顧客加入購物車的行為。圖片來源/Zalando
階段二:取消產品SRE小組配置,將SRE工作交給各產品交付小組
不過,搜集了大量SLI指標維運數據之後,空有SRE數據, SRE團隊卻沒有解決原本待命支援不足的問題,也沒有善用這些維運數據來改善開發。Pedro Alves點出最大的問題是,原本的SLI指標是以確保微服務可用性的角度來設計,但是隨著他們所用的微服務越來越多,甚至發展出4千個微服務,一個產品可能由數十個或上百個微服務來支援,對工程團隊來說,越來越難從上百個微服務的SLI指標數據來判斷。
Zalando決定改變SRE導入策略,從工具面和組織面兩方面開始調整。一方面改良SRE工具和SRE做法,從產品管理層級來管理SLO的達成情況,而非監控微服務工程層級的龐大SLI指標數據,也不再用當機事件的指標數據,改用事件徵兆來設計警示機制,改為搜集那些可能造成當機事件的事前訊號,例如記憶體快速暴增的趨勢,來提前發布預警,來減少誤判,還設計了新的事件處理流程,區分出異常狀況和緊急事件的不同處置做法,並進一步區分不同的改善做法對顧客或是業務能帶來的效益,優先採取更有利的做法。另外,也開始注重待命工程師的健康,避免長期疲勞帶來的影響。
最重要的是,Zalando開始累積SRE維運指標的成效數據,來評估所設計的可觀測性指標,是否符合當初所設計的目標,用這套數字來規畫SRE工作的KPI,定期量測結果,回報和檢討這些 KPI。
另外,為了統整分散在不同工具中的SLO資訊,也打造了一個新的服務水準管理工具,可以提供營運角度的SLO報表,讓管理團隊快速掌握目前各項網站或平臺的服務水準狀態,也可以查詢還有多少錯誤預算(Error Budget)可用,方便來安排各項任務的優先順序,尤其是出錯預算越吃緊的關鍵服務,一但有需求就得優先處理。
另一方面,Zalando也改變了SRE團隊的組織編制方式,取消了原本在各產品下所設置的SRE團隊,將SRE工作改交給各產品團隊中的交付小組(Delivery Team)來接手,讓他們接手自己產品中關鍵服務的維運,要求產品交付團隊必須具備SRE能力,來負責各自所負責的關鍵產品的待命工作。
改良SRE做法,再加上改由交付團隊接手待命工作之後,2017年時,Zalando終於解決了技術待命人力不足問題,足足花了2年才客服,而SRE事後檢討報告(Post-mortem)也成為了各產品團隊的習慣做法,對SRE做法也累積出了一套最佳實踐,包括了監控機制,事件應變,混沌工程和可靠性工程。
雖然取消了各產品團隊下的SRE小組,但是Zalando在2018年時,建立了兩個SRE輔助團隊,一個是在數位基礎架構部門(共用功能開發部門)下設置了SRE啟動團隊,負責輔導各產品團隊導入SRE,另一個是負責改善SRE體驗的開發團隊,接手打造各種SRE工具。
這兩個團隊一起參與全公司的SRE推動計畫,持續將分散式SRE追蹤機制導入到所有團隊,也要運用SRE蒐集到的維運數據,來支援各平臺網頁的載入優化以及各產品基礎架構的腰話工作。另外,SRE計畫成員還要支援網購周的事前準備,由SRE計畫成員負責接手網購活動的負載測試,甚至在黑色星期五促銷活動期間,兩個SRE輔導團隊的人員得在活動戰情室中待命。這個單一SRE計畫雙團隊的運作模式做法一直持續到了2018年底。2019年更直接合併成一個專責SRE團隊,開始發展各種更細緻的SRE做法,例如關鍵業務流程的維運,可以提前發現當機問題的徵兆預警機制等。
2019年時,Zalando更參考Google在SRE手冊中提出的服務可靠性架構(Service Reliability Hierarchy)來發展更長期的SRE戰略。一方面利用這個服務可靠性架構來修正現有的SLO,希望從「對使用者產生什麼影響的角度」,來尋找更適當的觀測能力機制,讓事件應變和管理更有效率。
不只在監控機制上搜集各種數據,針對事件應變建立更多待命機制,或善用Postmortem事後分析來尋找根本原因分析,也更重視發布前的測試,來減少出錯,並強化容量規畫的自動化能力,甚至在開發階段就要納入可靠性設計思維,產品設計上也要考慮大規模發布的策略。

隨著微服務越來越多,Zalando甚至發展出4千個微服務,一個產品可能由數十個或上百個微服務來支援,對工程團隊來說,越來越難從上百個微服務的SLI指標數據來判斷。圖片來源/Zalando
.jpeg)
2019年時,Zalando更參考了Google在SRE手冊中提出的服務可靠性架構(Service Reliability Hierarchy)來發展更長期的SRE戰略。圖片來源/Zalando
階段三:SRE升格一級單位,發展長期戰略讓業務單位也嵌入SRE實務
2020年時,Pedro Alves指出,因為SRE實踐成果,帶來了很大的幫助,讓Zalando決定,提升SRE團隊的組織位階,成立一個SRE部門,來推動這一套SRE戰略。這個SRE部門的位階,跟其他產品或研發部門並行,也要負責規畫更長期的企業SRE戰略。
他指出SRE組織升格之後的改變,原本的SRE團隊是任務編組,講求彈性來因應特定任務的專案,但變成一個部門後,就需要訂出一個日常目標,SRE部門的目標,就是將SRE可觀測性做法標準化。
Zalando甚至設計了一套SRE課程,來擴大SRE效益的規模,還設置了一個攝影棚,來拍攝一系列的線上課程,由SRE各主題專家設計內容,每個主題一部影片和一份測驗。
最後,還把這一系列SRE課程,列入新人訓練內容。任何工程師都必須完成這套SRE實踐的入門課程。另一方面,Zalando希望將SRE做法更普及到各項產品和服務,不只與維運相關的部門,甚至連業務部門都要透過這個課程,對SRE觀念有更多了解。
2022年,Zalando下一階段的SRE工作目標是,將產品管理對標到SRE戰略,在SRE部門下發起了一個新的團隊,稱為SRE嵌入團隊,要建立一系列KPI,讓產品管理可以和SRE對標標,從高階主管和產品管理的角度,來促成SRE與各業務部門的合作。

為了擴大SRE效益,導入到業務部門,Zalando甚至設置了一個攝影棚,拍攝一系列SRE線上課程,由SRE各主題專家設計內容,還把這一系列SRE課程,列入新人訓練內容。圖片來源/Zalando

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06