,而非配置為裸機,理由是前者更有彈性,可利用OpenShift在幾分鐘內動態擴大或縮減AI叢集或將運算資源在不同工作負載之間轉移。(圖片來源/IBM)")
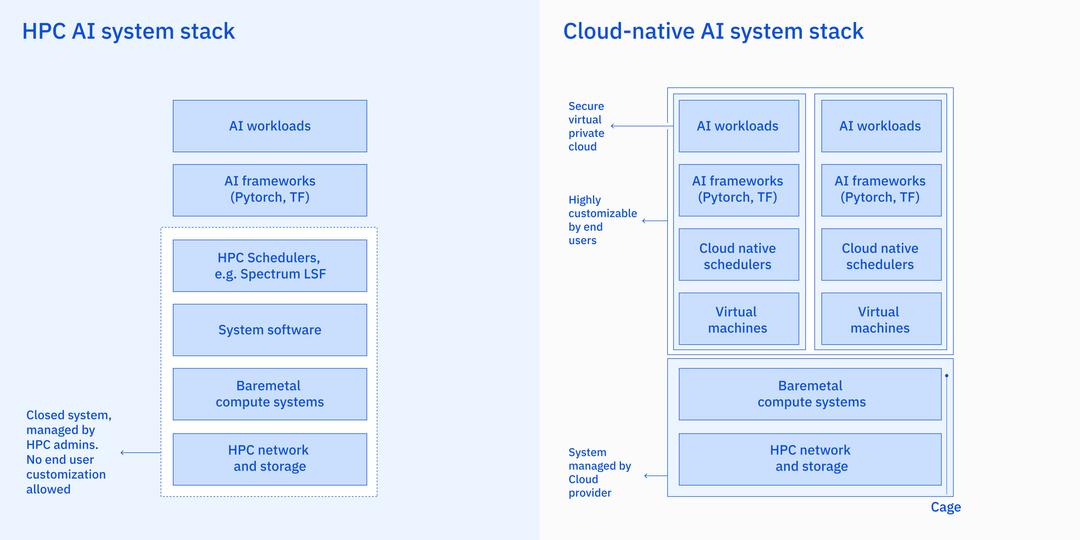
IBM指出,傳統超級電腦設計會使「AI超級電腦」的建造成本大為增加,且限制部署彈性。因此,在選擇AI超級電腦基礎架構上,IBM選擇將節點配置為VM(virtual machine),而非配置為裸機,理由是前者更有彈性,可利用OpenShift在幾分鐘內動態擴大或縮減AI叢集或將運算資源在不同工作負載之間轉移。(圖片來源/IBM)
IBM已經有2座全球前10大的超級電腦系統,如Summit和Sierra,但隨著企業轉向以雲端為主的IT基礎架構,藍色巨人也亟欲展示其雲端服務的能力。IBM研究院本周公布去年在自家IBM Cloud上建立專為執行人工智慧(AI)應用的雲端超級電腦Vela,其速度相當於全球第15大的超級電腦。
IBM指出,超級電腦和AI本來屬於兩種不同領域;超級電腦多半是建立在裸機節點、高效能網路硬體(如InfiniBand、Omnipath和Slingshot)、平行檔案系統及其他高效能運算(HPC)元件。但超級電腦並非為AI設計,而是為了建模或模擬任務,如執行大氣變化模擬、材料開發或蛋白質摺疊等醫療研究。如果要用於執行AI模型建立,傳統設計會使這類「AI超級電腦」的建造成本大為增加,且限制部署彈性。IBM研究院去年就在IBM Cloud上打造了第一臺雲端原生、為AI最佳化的「AI超級電腦」Vela,專門用於大量部署AI應用任務,而且已在2022年5月上線運行。
圖片來源/IBM
IBM說明,Vela解決了效能及部署彈性的兩難。在選擇AI超級電腦基礎架構上,IBM選擇將節點配置為VM(virtual machine),而非配置為裸機,理由是前者更有彈性,可利用OpenShift在幾分鐘內動態擴大或縮減AI叢集或將運算資源在不同工作負載之間轉移。但團隊面臨的挑戰是在VM環境下配置出裸機般的效能。
Vela每個節點具備80GB A100 GPU,2顆第2代Intel Xeon Scalable處理器(Cascade Lake)、1.5TB DRAM及4個3.2 TB NVMe磁碟,IBM表示,超大記憶體及儲存空間是為了能訓練大型模型。為支援分散式訓練,運算節點之間以多道100G網路介面卡相連,且使用IBM Cloud的VPN網路功能,確保連線安全性。
IBM表示,在IBM研究院和PyTorch的合作專案中,使用80GB記憶體使團隊得以使用更大批次資料,以及Meta的FSDP(Fully Shared Date Parallel)訓練策略,進行分散式訓練任務,效率提升到高達90%以上,總參數超過100億個。
此外,由於支援VM擴充(Virtual Machine Extensions,VMX)、Single-root IO virtualization(SR-IOV)及大量頁面的裸機配置,使Vela的VM整體效能耗損減到低於5%。IBM說這是他們已知最低的耗損率,也讓其AI超級電腦效能逼近裸機。IBM研究院希望展現,在標準的乙太網路雲端基礎架構上,也能輕易執行數十億參數的AI模型。
The Next Platform估計,以Vela現有規格,其標竿測試的效能可達每秒27.9 petaflops,若按2022年11月最新的全球五百大電腦排行,約等同於全球第15大。
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10