
微軟開發一款語言模型Orca,參數量130億,但表現比ChatGPT等大型語言模型還要好。
微軟
重點新聞(0602~0608)
微軟 Orca 生成式AI
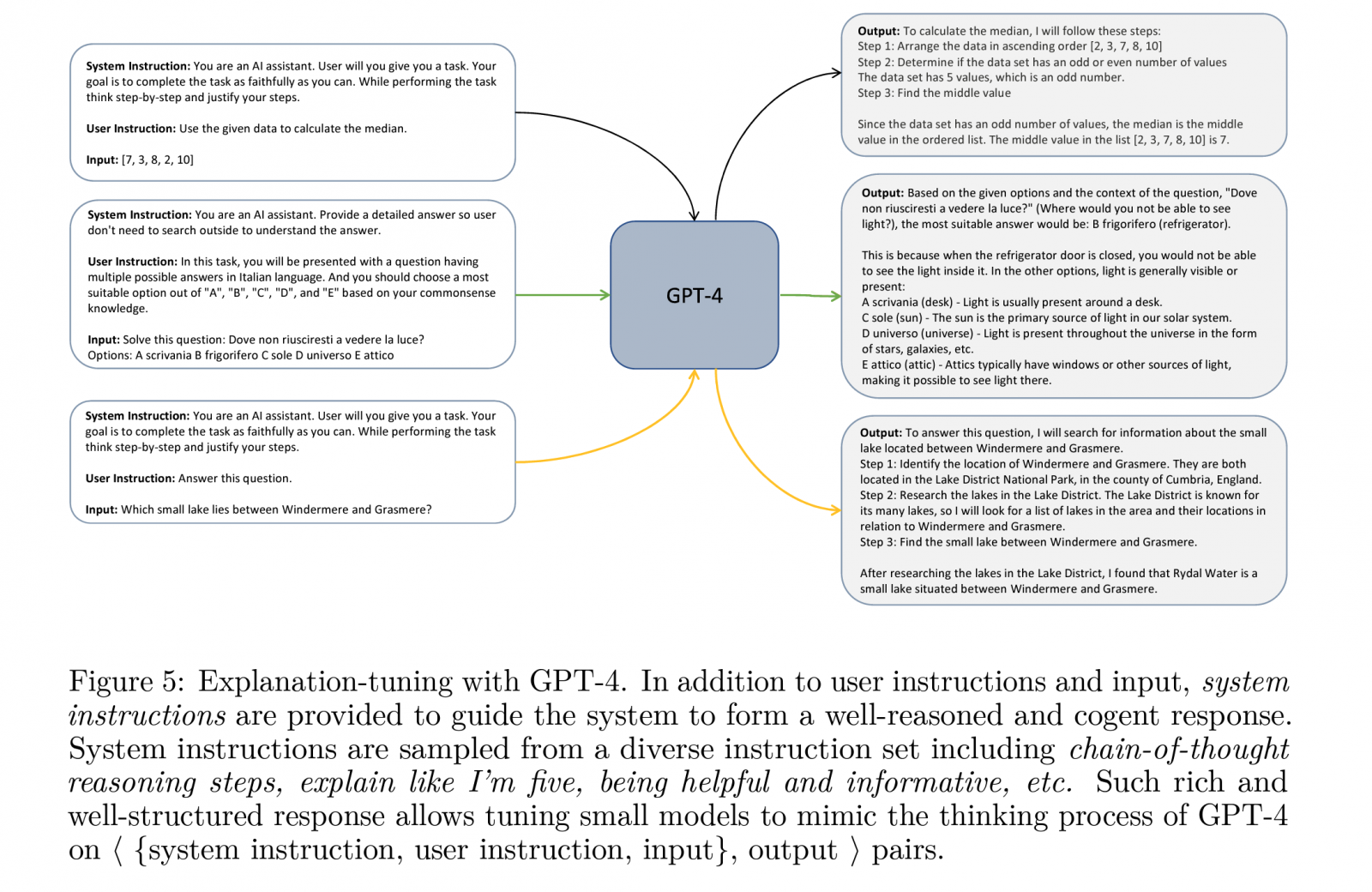
微軟發表130億參數模型Orca,表現比ChatGPT還要好
微軟日前發表一款130億參數的語言模型Orca(虎鯨),還在一系列基準測試中贏過主流大型基礎模型,像是ChatGPT、Bard,以及其他同參數量的Vicuna-13B、Alpaca-13B和LLaMA-13B等模型。進一步來說,微軟想透過學習、模仿大型語言模型的推理過程,來提高小模型表現,於是,他們以GPT-4為標竿,讓Orca學習GPT-4的推理過程,包括解釋步驟、逐步(Step by step)思考模式和其他複雜指令,並由ChatGPT的老師模型來引導。
測試時,團隊以GPT-4作為評分工具,來衡量Orca在嚴格的基準測試Big Bench Hard(BBH)中與其他SOTA模型的表現,發現比ChatGPT、Bard等要好,也在包含SAT、LSAT、GRE和GMAT等學術考試的AGIEval基準測試中,拿下不錯成績。(詳全文)
函式庫 Teams Copilot
微軟推出AI函式庫,開發者可用來打造Teams AI應用程式
微軟不只在M 365生產力工具中加入Copilot擴充套件、用大型語言模型協助用戶處理語言任務,現在還進一步擴展大型語言模型的支援,推出Teams AI函式庫。Teams AI函式庫是一個開發工具,以GPT-4為基礎,能讓開發者在Teams平臺上打造具AI功能的Teams應用程式,也支援多種語言。Teams AI函式庫包括進階AI元件,如對話式AI、提示語管理和安全審查等功能,開發者可開發高度互動的應用程式。微軟指出,該函式庫的設計考慮了開發的簡單性和靈活性,所以開發者不需花大量時間,理解複雜的協定或是編寫自定義對話邏輯。(詳全文)
Google Transformer 擴散模型
一句話一張圖就能準確生成新圖片,Google發表新文字生成圖片模型StyleDrop
Google最近發表一款圖片生成圖片的AI系統StyleDrop,以Google先前發表的同類模型Muse為基礎,可根據使用者給定的一張圖和文字提示,來生成同樣風格和紋理的圖片,表現比擴散模型(如Stable Diffusion、Imagen)還要好。
進一步來說,有別於擴散模型,StyleDrop是一款基於離散Token的視覺Transformer模型。團隊在訓練模型時,採用了人工回饋和自動回饋方法,來提高產出品質,也就是說,團隊對StyleDrop輸入一張圖片後,模型會產出一組同樣風格的圖片,團隊手動挑選或用CLIP模型自動分類出品質最好的圖片,再用這些圖片來訓練模型。與此同時,團隊也利用Dreambooth模型來強化StyleDrop對物件圖片的生成表現,由前者學習物件、後者學習風格,再整合為生成結果。Google表示,StyleDrop的強項在於能捕捉圖片風格中的細微差異,像是色彩、陰影、圖案設計等,並能按照該風格生成圖片。他們評比發現,StyleDrop的風格轉換表現比Textual Inversion、Dreambooth、LoRAs和Imagen等主流模型還要好。(詳全文)

Falcon LLM SageMaker
阿拉伯聯合大公國打造400億參數LLM,霸榜OpenLLM排行榜
近日,阿拉伯聯合大公國科技創新研究所(TII)用AWS機器學習服務SageMaker打造出400億參數的語言模型Falcon-40B,在Hugging Face的OpenLLM排行榜上位居第一,贏過LLaMA、StableLM和RedPajama等模型,最近也開源了。
Falcon-40B是因果解碼器,用將近5億個Token訓練而成。這些訓練資料來自網路公開文件,為提高訓練資料品質,團隊還自建資料處理工作流程,透過過濾和去重複化來挑出高品質資料。此外,團隊還採用了多重查詢注意力(Multiqery attention)機制和FlashAttention注意力機制,來提高模型效率。簡單來說,多重查詢注意力機制可讓模型對每個Token產生多個查詢,來更好表示同一序列中,不同token之間的關係;FlashAttention則能加速自我注意力的運算、降低複雜性,進而提高模型整體的運算效率。
接著,團隊使用SageMaker服務和384顆GPU來進行2個月的訓練。經多個基準測試,表現比LLaMA、Vicuna和Alpaca好,目前開源的版本有Falcon-7B-Instruct和Falcon-40B-Instruct等。(詳全文)

Google Cloud Chatbot 資料搜尋
Google雲推生成式AI新服務,企業可自建Chatbot搜尋內部資料
Google Cloud推出一項AI服務Enterprise Search on Gen App Builder,使用者可用來開發聊天機器人,來搜尋企業內部資料。進一步來說,這款服務特別之處,在與用生成式AI聊天機器人模式來搜尋資料,可克服傳統查詢方法的痛點,如出現大量模式匹配連結、相關答案需要人力檢查等。Enterprise Search on Gen App Builder可讓開發者打造特定資料源的搜尋引擎,提高搜尋準確性和相關性,且可處理多模態資料,像是圖片、影像,還能讓用戶控制答案輸出。
Google也透露,美國醫療龍頭梅約醫學中心將採用Enterprise Search on Gen App Builder,來在幾分鐘內自建搜尋用的聊天機器人和語義搜尋應用程式,且幾乎不需要寫什麼程式,加速醫師及研究人員搜尋醫院內各種格式的文件,如病歷、研究論文、臨床指引和資料庫作為研究、診斷及治療之用。Google Cloud稱,這項服務已符合HIPAA標準。(詳全文)
微軟 VS Code C#
微軟推出全新C#開發工具包,新添AI開發功能
微軟推出VS Code新C#開發工具包,可在Linux、macOS和Windows等作業系統上,提供更高效可靠的工具環境。C#開發工具包由一組VS Code擴充套件組成,這組擴充套件提供完整的C#編輯、AI開發、解決方案管理和整合測試功能。
在安裝C#開發工具包時,系統會自動安裝IntelliCode for C# Dev Kit,這個新IntelliCode比原本C#擴充套件中的IntelliCode還要好,而且,新添的AI功能還能依據開發者個人程式碼庫,提供整行程式碼完成以及星形標籤的建議,也會將最可能使用的內容,在C#專案的IntelliSense完成列表置頂。(詳全文)
Nvidia 3D Neuralangelo
Nvidia公布能將2D影片轉成3D的AI模型Neuralangelo
Nvidia最近發表可將2D影片片段轉為3D的AI模型Neuralangelo,而且細節豐富、紋理清楚,如建築、雕刻和其他真實物體,創作者可用來產生3D物件、匯入到設計應用,或是進一步編輯,應用於藝術、電玩開發、機器人或數位分身中。
Neuralangelo使用即時神經繪圖原語來捕捉物體微妙的細節,能以不同角度拍攝的2D影片為素材,從中選擇多個不同角度的影格,一旦決定每個影格的相機位置後,就會產出初步的3D再現影像,並加入細節、使其成型,產出的3D物件可用於VR應用、機器人等領域。Nvidia研究院預定在6月18到22日舉行的電腦視覺盛會CVPR上發表這款模型,並在預定發布的影片中,展示模型如何重建米開朗基羅的著名雕刻《大衛》、平板拖車和建築物室內裝潢與室外設計。(詳全文)
OpenAI AI幻覺 過程監督
OpenAI新訓練方法可避免AI出現幻覺
OpenAI採用了一種稱為過程監督(Process Supervision)的訓練方法,來獎勵每個正確步驟的推理,讓模型能遵循人類認可的關聯思考(Chain-of-Thought),產生更可靠的結果。
雖然近期大型語言模型的推理能力大幅度提高,但OpenAI指出,即便是最先進的模型,仍會產生邏輯錯誤,也就是幻覺(Hallucination),而解決幻覺是建置通用AI的關鍵。OpenAI先是評估2種監督方法,利用MATH測試集來衡量過程監督和結果監督,發現過程監督的效能比結果監督佳,而且當問題變得複雜,效能差距也會增加,整體來說,過程監督獎勵模型更加可靠。(詳全文)
圖片來源/微軟、Google、TII、Nvidia
AI近期新聞
1. Google發表AI系統的安全性概念框架
2. DeepMind AI模型不下圍棋了,新AlphaDev模型可加速資料中心運算效率
3. Wordpress Jetpack AI助理可幫忙寫部落格
資料來源:iThome整理,2023年6月
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10