
Meta
Meta上周發表了可同時支援文字與圖像生成的CM3Leon模型,這是史上第一個由純文字語言模型配方所訓練的多模態模型,並宣稱其圖像生成所使用的訓練運算資源只要其它方法的1/5,即可達到先進效能。
CM3Leon是個基於Token、檢索增強與decoder-only的模型,它採用因果隱蔽混合模態(Causal Masked Mixed-Modal,CM3)架構,代表該模型得以僅關注之前的元素來生成輸出序列,確保生成內容的連貫性,且於訓練過程中能夠忽視或隱蔽某些元件,以生成更好的結果,還可同時處理文字及圖像的輸入。
Meta強調CM3Leon是個通用模型,透過單一模型即可處理許多不同的任務,像是以文字描述來生成圖像,也能以文字描述來編輯圖像,或者是要求該模型替圖像生成圖說等。
例如以文字要求它生成「在撒哈拉沙漠的一株小仙人掌戴上了一頂鑲有霓虹太陽眼鏡的草帽」的圖像;也能利用文字幫《戴珍珠耳環的少女》戴上墨鏡,或是以文字調整天空的顏色;使用者還可要求CM3Leon替圖像生成圖說,以文字描繪圖像中的元素。

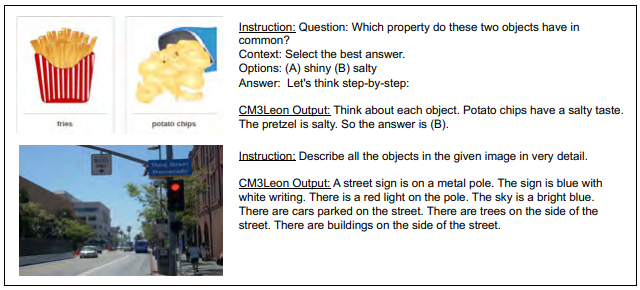
研究人員表示,CM3Leon僅使用30億個Token的文字資料進行訓練,大幅低於OpenFlamingo的400億個Token與Flamingo的1,000億個Token,但它卻能在替圖像產生圖說,以及回答圖像問題等兩個任務上,達到與OpenFlamingo相當的zero-shot效能等級。此外,它在回答VizWiz資料集中圖像問題的表現還勝過Flamingo。
有別於今年5月大方開源整合文字、聲音與視覺資料的多模態AI模型ImageBind,此次Meta並未公布是否或何時釋出CM3Leon。
熱門新聞

2026-02-16


2026-02-17



2026-02-16

2026-02-16

2026-02-13