Elon Musk在今年7月成立一家AI新創xAI,最近揭露首款產品Grok,是一個以大型語言模型為基礎的AI聊天機器人。其核心模型為Grok-1,經多項基準測試,模型整體表現優異,特別是在程式碼任務上,僅次於Claude 2和GPT-4。
xAI
重點新聞(1027~1102)
生成式AI Grok Chatbot
今年7月開始訓練33B語言模型,馬斯克揭露xAI首款Chatbot
馬斯克日前揭露旗下xAI公司的首款產品Grok,是一款類似ChatGPT的聊天機器人,主打能幽默回應使用者、與使用者產生共鳴。xAI也在X平臺上說明,Grok能透過X平臺獲取即時資訊,來回答使用者問題,還能回答其他AI系統拒絕回答的辛辣問題。馬斯克表示,Grok目前還在初期測試階段,未來將提供給X Premium+訂閱戶使用。
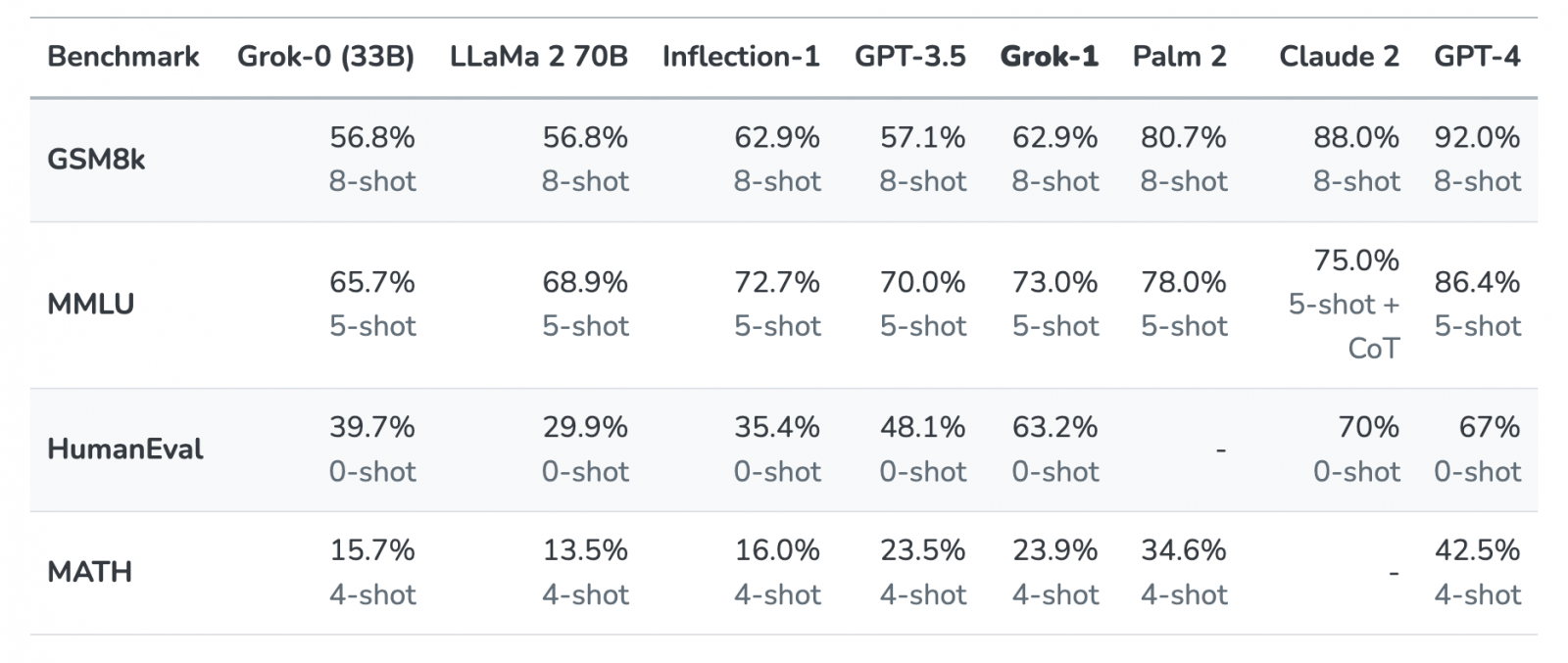
xAI在官網指出,公司自今年7月成立後,就開始訓練一個330億參數的語言模型Grok-0。該模型在標準的語言模型基準測試中,表現與700億參數的Llama 2相當,但只使用了一半的訓練資源。接著,在過去2個月裡,團隊又提高模型的推理和寫程式能力,最終產出Grok-1模型。
這個Grok-1功能更強大,在HumanEval基準測試的寫程式任務中拿下了63.2%成績,僅次於70%的Claude 2和67%的GPT-4。而在多學科多重選擇題的MMLU基準測試中,Grok-1拿下了73%,僅次於GPT-4、PaLM 2和Claude 2。xAI說明,為打造Grok,他們還建立了基於K8s、Rust和JAX的自定義訓練和推論堆疊,而且,為確保GPU不發生故障,團隊採用一組客製化的分散式系統,能立即辨識、自動處理每種故障,如配置不正確、記憶體晶片效能下降等。這個方法,讓xAI在過去幾個月裡,大幅減少停機時間,並保持高度的模型浮點運算利用率(MFU),就算在硬體不可靠的情況下依然如此。接下來,他們要繼續優化模型能力,包括用數萬個加速器來訓練模型、執行網際網路等級的工作管線,以及開發Grok新功能和新工具等。(詳全文)
LLM RedPajama 資料集
專為LLM設計,具30兆Token的開源資料集來了
最近,AI新創公司Together.ai開源釋出第二代LLM訓練資料集RedPajama-Data-v2,共有30兆個Token,要用來強化語言模型訓練品質。該資料集包含2大部分,一是從開源網路爬蟲資料集CommonCrawl的84個轉存(Dumps)中精挑細選,將原本100多兆個Token過濾、剔除重複的資料,保留30兆個Token,涵蓋英語、法語、西班牙語、德語和義大利語等5種語言,但未包含中文。另一部分是40多個預運算的資料品質註釋,可用於進一步的過濾和權重,提高資料集的實用性。
早在今年3月,該新創就釋出5TB的高品質英語標記資料集RedPajama-1T,半年多來累積了19萬次下載量。這次,他們進一步開源涵蓋5種語言的資料集,號稱是目前最龐大的LLM訓練資料集,同時在GitHub和HuggingFace上提供所有數據。(詳全文)

行政命令 風險 安全
拜登簽署美國首個AI行政命令
美國總統拜登10月30日簽署了AI行政命令,提出8項行動目標,包括建立AI安全新標準、保護人民隱私、促進公平與公民權利、支持勞工、推動創新與競爭、提升美國在海外的領先地位,以及保障消費者、病患和學生,還有確保政府負責任及有效使用AI。
其中,建立AI安全新標準列舉許多重點工作,首先是要求AI系統開發者,與美國政府分享其AI安全測試結構和其他重大資訊,再來是要發展各式標準、工具和測試方法,來確保AI系統的可靠性。此外還包括制定標準,來監控生物合成,避免不法人士用AI設計出危險的生物材料。不只如此,美國政府也要建立分辨AI生成內容與官方內容的偵測機制和實作方法,最後則是開發AI工具,來找出和修補重大軟體的安全漏洞。(詳全文)
Jina AI LLM 文字嵌入
與OpenAI同等級!Jina AI開源第2代文字嵌入模型
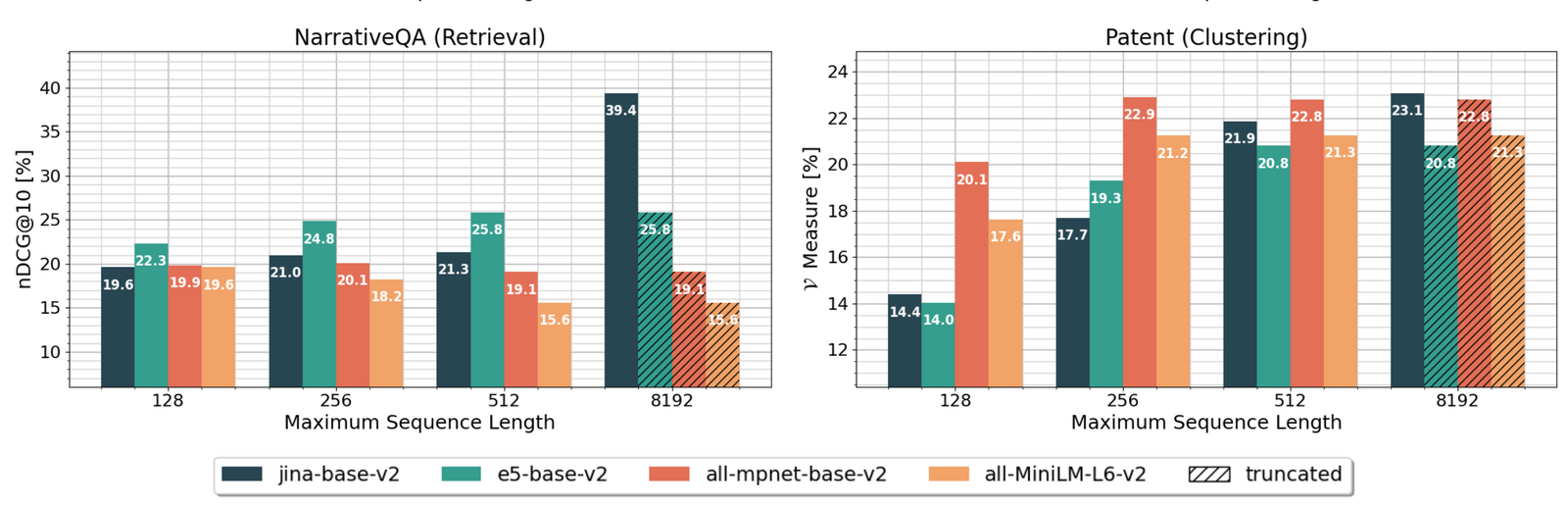
德國AI新創Jina AI開源自家第2代文字嵌入模型jina-embeddings-v2,可處理多達8,192個token的文長。而且,經大規模文字嵌入基準(Massive Text Embedding Benchmark)測試評估,該模型排名第17,與商用OpenAI text-embedding-ada-002的第15名相差無幾。而且在分類、重新排序、檢索和摘要生成等自然語言處理任務中,該模型表現比OpenAI的模型還要好。
jina-embeddings-v2能處理8,192個token是一大進展,代表模型可應用的領域更廣,像是分析法律文件、更細緻地捕捉文件中細節,或從財務報表中解析關鍵資訊、進行財務預測,也能用於對話機器人,來處理複雜的用戶查詢。目前,使用者可從Huggingface免費下載jina-embeddings-v2模型,包括2種版本,一是針對學術研究或商業分析等高準確性需求設計的,大小為0.27 GB的基礎模型,另一是適用於輕量級應用程式,能整合行動應用程式或運算資源有限裝置的小型模型,容量只有0.07 GB。(詳全文)
風險 OpenAI Preparednes
OpenAI設立專屬團隊,要評估通用AI災難性風險
OpenAI最近宣布要建立Preparedness團隊,來評估通用AI可能造成的災難性風險,並由麻省理工學院的可部署機器學習中心主任Aleksander Madry主導。這些風險涵蓋個人化說服、網路安全、化學/生物/放射性/核(CBRN)威脅,以及自主複製與適應(ARA)。其中,個人化說服指的是以AI建立的個人化內容,來影響個人的行為、觀點或決策;至於ARA則指AI系統具自我複製與演進能力,使它脫離人類控制,或產生非預期目標。
Preparedness團隊將針對各種前沿模型,評估模型能力與紅隊測試,並制定開發及維護風險意識發展政策(RDP),闡述該團隊所開發的模型能力評估與監控方法,還要建立模型治理架構。OpenAI已開始招募不同背景人才加入Preparedness團隊,同時推出AI Preparedness挑戰賽,鼓勵參賽者設想自己是駭客,在可無限制地存取OpenAI模型時,有哪些可造成災難的獨特使用情境。(詳全文)
生成式AI 抓漏 提示攻擊
Google公布AI抓漏獎勵範圍,新添生成式AI類別
日前,Google宣布擴大AI系統抓漏獎勵計畫,要進一步納入生成式AI。進一步來說,Google認為,相較於傳統的安全漏洞,生成式AI有著不同問題,如不公平偏見、模型操縱或資料誤解。隨著Google日益將生成式AI整合到產品中,內部團隊正全面預測和測試其潛在風險,同時也想藉外部研究者協助,來找出新漏洞並解決問題。
其實,Google本來就有AI抓漏獎勵計畫,其類別包括提示攻擊、訓練資料汲取、操縱模型、對抗性擾動,以及模型竊取等,凡是利用提示來影響模型的行為或輸出,重建或汲取包含敏感資訊的訓練資料,得以改變模型行為,或可竊取模型權重與結構等關鍵資訊的安全漏洞,都在獎勵之列。(詳全文)
MLCommons 安全 LLM
MLCommons成立AI安全工作組
開放工程聯盟MLCommons最近成立人工智慧安全(AIS)工作組,要建立一個平臺,來讓貢獻者組成測試池,支援各種用例的AI安全基準。該工作組初期將使用史丹佛大學的HELM框架,作為大型語言模型開發安全基準。
MLCommons是一個開放協作生態系,目的在於推動機器學習的發展和應用,並發展基準測試、最佳實踐、資料集和各種共享資源上。MLCommons的新平臺將提供一個機制,讓使用者從測試池中選擇基準測試,也能將輸出整合成容易理解的分數,來對AI系統安全性評級。該平臺的近期重點,在於支援嚴謹、可靠的AI安全測試技術發展。此外,AIS工作組也計畫,將內部用於AI安全測試的技術公開,與MLCommons社群共享。(詳全文)
聯合國 AI顧問組織 治理
聯合國成立AI顧問組織
聯合國日前成立AI顧問組織,來研究AI技術風險和機會,以及全球治理方向。該組織由聯合國秘書長António Guterres發起,招攬了全球39名專家,預計要在今年底前,針對AI的風險、挑戰、機會,以及如何利用AI來加速永續發展目標(SDGs)等議題提出建議。
Guterres指出,AI顧問組織是全球AI治理的起點,來盡可能為所有人帶來利益,同時遏制風險。但這也取決於AI是否被負責任地利用,以及是否所有人都能使用,因為,目前相關專業知識集中在少數公司和國家,這很可能深化全球不平等,使數位落差成為鴻溝。而這個組織,可望解決這些問題。(詳全文)
圖片來源/xAI、Together.ai、Jina AI
AI趨勢近期新聞
1. DeepMind發布新版AlphaFold模型,可精準預測生物分子結構加速藥物開發
2. PChome揭行動商務優先的介面改版策略,包括用AI強化搜尋功能
資料來源:iThome整理,2023年11月
熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13